- 安装
- 文档
- 入门
- 连接
- 数据导入
- 客户端 API
- 概览
- ADBC
- C
- C++
- CLI
- Dart
- Go
- Java (JDBC)
- Julia
- Node.js (已弃用)
- Node.js (Neo)
- ODBC
- PHP
- Python
- R
- Rust
- Swift
- Wasm
- SQL
- 介绍
- 语句
- 概览
- ANALYZE
- ALTER TABLE
- ALTER VIEW
- ATTACH 和 DETACH
- CALL
- CHECKPOINT
- COMMENT ON
- COPY
- CREATE INDEX
- CREATE MACRO
- CREATE SCHEMA
- CREATE SECRET
- CREATE SEQUENCE
- CREATE TABLE
- CREATE VIEW
- CREATE TYPE
- DELETE
- DESCRIBE
- DROP
- EXPORT 和 IMPORT DATABASE
- INSERT
- LOAD / INSTALL
- PIVOT
- 性能分析
- SELECT
- SET / RESET
- SET VARIABLE
- SUMMARIZE
- 事务管理
- UNPIVOT
- UPDATE
- USE
- VACUUM
- 查询语法
- SELECT
- FROM 和 JOIN
- WHERE
- GROUP BY
- GROUPING SETS
- HAVING
- ORDER BY
- LIMIT 和 OFFSET
- SAMPLE
- 展开嵌套
- WITH
- WINDOW
- QUALIFY
- VALUES
- FILTER
- 集合操作
- 预处理语句
- 数据类型
- 表达式
- 函数
- 概览
- 聚合函数
- 数组函数
- 位字符串函数
- Blob 函数
- 日期格式化函数
- 日期函数
- 日期部分函数
- 枚举函数
- 间隔函数
- Lambda 函数
- 列表函数
- 映射函数
- 嵌套函数
- 数值函数
- 模式匹配
- 正则表达式
- 结构体函数
- 文本函数
- 时间函数
- 时间戳函数
- 带时区时间戳函数
- 联合函数
- 实用函数
- 窗口函数
- 约束
- 索引
- 元查询
- DuckDB 的 SQL 方言
- 示例
- 配置
- 扩展
- 核心扩展
- 概览
- 自动补全
- Avro
- AWS
- Azure
- Delta
- DuckLake
- 编码
- Excel
- 全文搜索
- httpfs (HTTP 和 S3)
- Iceberg
- ICU
- inet
- jemalloc
- MySQL
- PostgreSQL
- 空间
- SQLite
- TPC-DS
- TPC-H
- UI
- VSS
- 指南
- 概览
- 数据查看器
- 数据库集成
- 文件格式
- 概览
- CSV 导入
- CSV 导出
- 直接读取文件
- Excel 导入
- Excel 导出
- JSON 导入
- JSON 导出
- Parquet 导入
- Parquet 导出
- 查询 Parquet 文件
- 使用 file: 协议访问文件
- 网络和云存储
- 概览
- HTTP Parquet 导入
- S3 Parquet 导入
- S3 Parquet 导出
- S3 Iceberg 导入
- S3 Express One
- GCS 导入
- Cloudflare R2 导入
- 通过 HTTPS / S3 使用 DuckDB
- Fastly 对象存储导入
- 元查询
- ODBC
- 性能
- Python
- 安装
- 执行 SQL
- Jupyter Notebooks
- marimo Notebooks
- Pandas 上的 SQL
- 从 Pandas 导入
- 导出到 Pandas
- 从 Numpy 导入
- 导出到 Numpy
- Arrow 上的 SQL
- 从 Arrow 导入
- 导出到 Arrow
- Pandas 上的关系型 API
- 多个 Python 线程
- 与 Ibis 集成
- 与 Polars 集成
- 使用 fsspec 文件系统
- SQL 编辑器
- SQL 功能
- 代码片段
- 故障排除
- 术语表
- 离线浏览
- 操作手册
- 开发
- 内部结构
- 为什么选择 DuckDB
- 行为准则
- 发布日历
- 路线图
- 站点地图
- 在线演示
Vector 是在执行期间用于存储内存中数据的容器格式。DataChunk 是 Vector 的集合,例如用于表示 PhysicalProjection 运算符中的列列表。
数据流
DuckDB 使用向量化查询执行模型。DuckDB 中的所有运算符都经过优化,以在固定大小的 Vector 上工作。
这个固定大小在代码中通常被称为 STANDARD_VECTOR_SIZE。默认的 STANDARD_VECTOR_SIZE 是 2048 个元组。
Vector 格式
Vector 逻辑上表示包含单一类型数据的数组。DuckDB 支持不同的向量格式,这允许系统以不同的物理表示存储相同的逻辑数据。这可以实现更紧凑的表示,并可能在整个系统中实现压缩执行。下面列出了支持的向量格式。
平面向量
平面向量物理上存储为连续数组,这是标准的未压缩向量格式。对于平面向量,逻辑和物理表示是相同的。
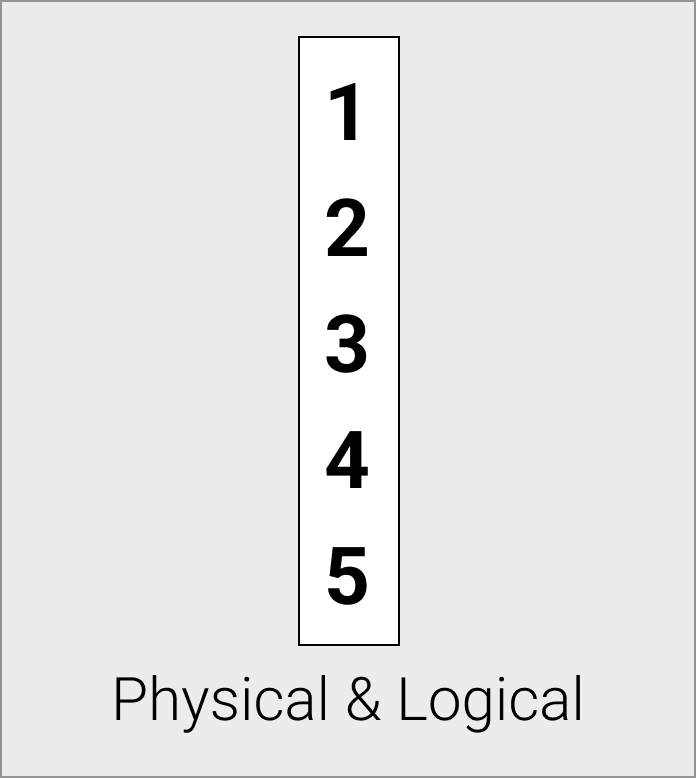
常量向量
常量向量物理上存储为单个常量值。
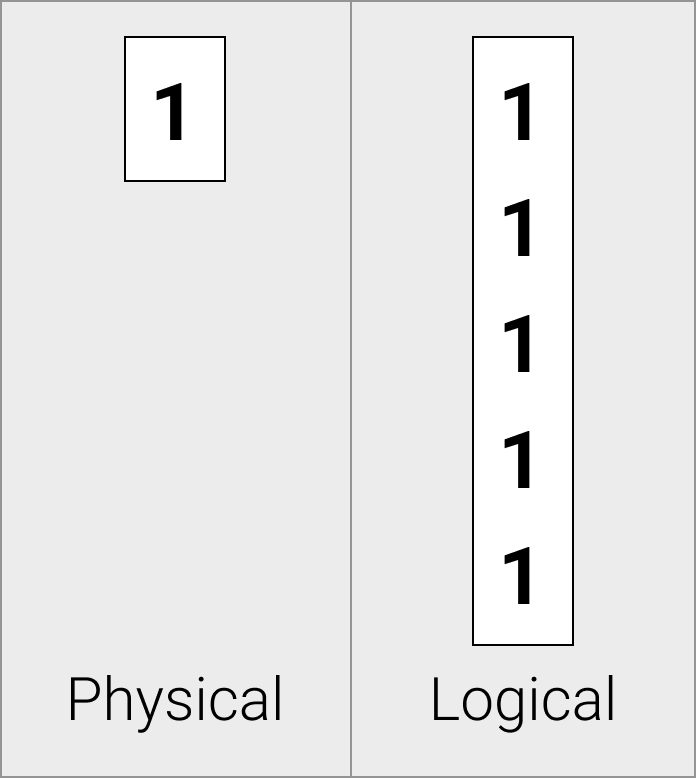
当数据元素重复时,常量向量很有用——例如,在函数调用中表示常量表达式的结果时,常量向量允许我们只存储值一次。
SELECT lst || 'duckdb'
FROM range(1000) tbl(lst);
由于 duckdb 是一个字符串字面量,因此该字面量的值对于每一行都是相同的。在平面向量中,我们必须为每一行复制一次字面量 'duckdb'。常量向量允许我们只存储该字面量一次。
从常量压缩解压时,存储层也会发出常量向量。
字典向量
字典向量物理上存储为一个子向量,以及一个包含子向量索引的选择向量。
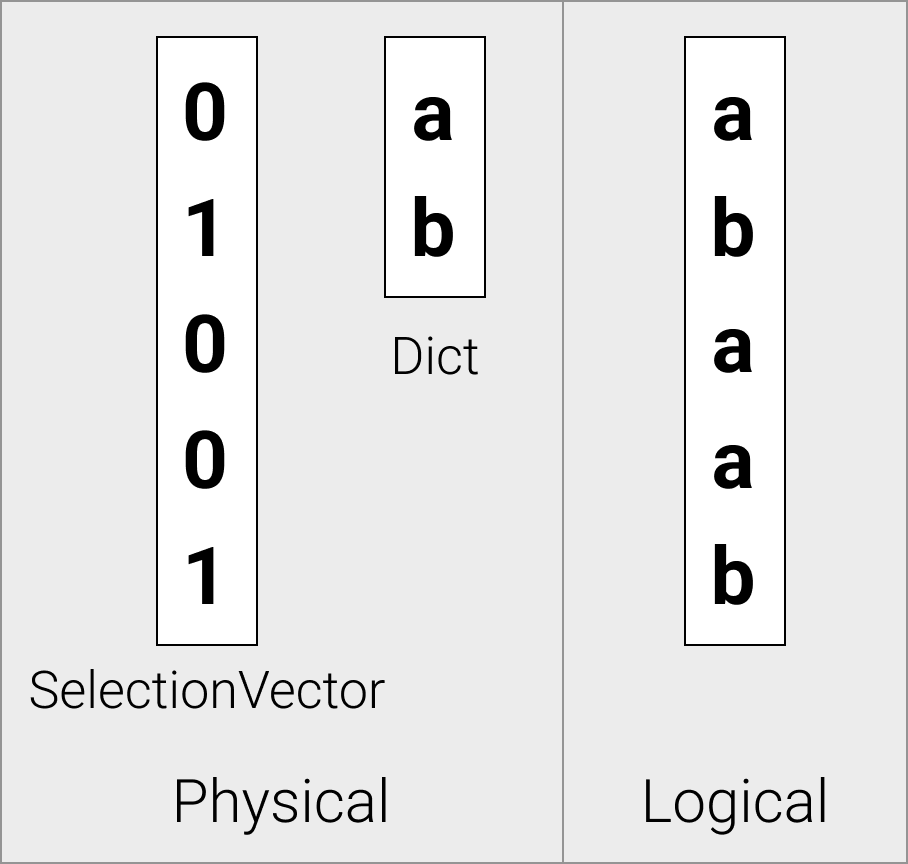
从字典解压时,存储层会发出字典向量
与常量向量一样,字典向量也由存储层发出。当反序列化字典压缩的列段时,我们将其存储在字典向量中,以便在查询执行期间保持数据压缩。
序列向量
序列向量物理上存储为偏移量和增量值。
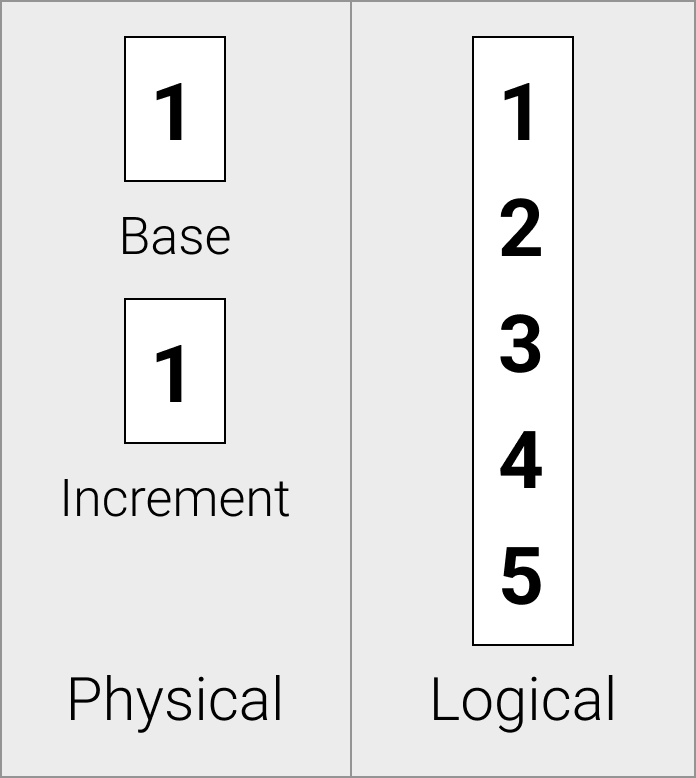
序列向量对于高效存储增量序列很有用。它们通常用于行标识符。
统一向量格式
这些不同向量格式的属性非常有利于优化,例如,您可以设想这样一种情况:函数的所有参数都是常量,我们可以只计算一次结果并发出一个常量向量。但是,由于可能性的组合爆炸,为每个函数的每种向量类型组合编写专用代码是不可行的。
与其这样做,不如在无论类型如何都希望通用地使用向量时,可以使用 UnifiedVectorFormat。这种格式本质上充当了 Vector 内容的通用视图。每种 Vector 类型都可以转换为这种格式。
复杂类型
字符串向量
为了高效存储字符串,我们利用了 string_t 类。
struct string_t {
union {
struct {
uint32_t length;
char prefix[4];
char *ptr;
} pointer;
struct {
uint32_t length;
char inlined[12];
} inlined;
} value;
};
短字符串(<= 12 bytes)内联到结构中,而较长的字符串则通过指针存储在辅助字符串缓冲区中的数据。长度在所有函数中都被使用,以避免调用 strlen 和连续检查空指针。前缀用于比较作为快速退出(当前缀不匹配时,我们知道字符串不相等,无需追踪任何指针)。
列表向量
列表向量与一个子 Vector 一起存储为一系列列表条目。子向量包含列表中存在的值,而列表条目指定了每个独立列表的构建方式。
struct list_entry_t {
idx_t offset;
idx_t length;
};
偏移量指的是子 Vector 中的起始行,长度则记录了该行列表的大小。
列表向量可以递归存储。对于嵌套列表向量,列表向量的子向量仍然是列表向量。
例如,考虑类型为 BIGINT[][] 的 Vector 的这个模拟表示。
{
"type": "list",
"data": "list_entry_t",
"child": {
"type": "list",
"data": "list_entry_t",
"child": {
"type": "bigint",
"data": "int64_t"
}
}
}
结构体向量
结构体向量存储子向量列表。子向量的数量和类型由结构体的模式定义。
映射向量
内部地,映射向量存储为 LIST[STRUCT(key KEY_TYPE, value VALUE_TYPE)]。
联合向量
内部地,UNION 利用与 STRUCT 相同的结构。第一个“子项”始终由 UNION 的标签向量(Tag Vector)占据,该标签向量记录了每一行适用于 UNION 的哪种类型。