- 安装
- 文档
- 入门
- 连接
- 数据导入
- 客户端 API
- 概览
- ADBC
- C
- C++
- CLI
- Dart
- Go
- Java (JDBC)
- Julia
- Node.js (已弃用)
- Node.js (Neo)
- ODBC
- PHP
- Python
- R
- Rust
- Swift
- Wasm
- SQL
- 介绍
- 语句
- 概览
- ANALYZE
- ALTER TABLE
- ALTER VIEW
- ATTACH 和 DETACH
- CALL
- CHECKPOINT
- COMMENT ON
- COPY
- CREATE INDEX
- CREATE MACRO
- CREATE SCHEMA
- CREATE SECRET
- CREATE SEQUENCE
- CREATE TABLE
- CREATE VIEW
- CREATE TYPE
- DELETE
- DESCRIBE
- DROP
- EXPORT 和 IMPORT DATABASE
- INSERT
- LOAD / INSTALL
- PIVOT
- 性能分析
- SELECT
- SET / RESET
- SET VARIABLE
- SUMMARIZE
- 事务管理
- UNPIVOT
- UPDATE
- USE
- VACUUM
- 查询语法
- SELECT
- FROM 和 JOIN
- WHERE
- GROUP BY
- GROUPING SETS
- HAVING
- ORDER BY
- LIMIT 和 OFFSET
- SAMPLE
- 展开嵌套
- WITH
- WINDOW
- QUALIFY
- VALUES
- FILTER
- 集合操作
- 预处理语句
- 数据类型
- 表达式
- 函数
- 概览
- 聚合函数
- 数组函数
- 位字符串函数
- Blob 函数
- 日期格式化函数
- 日期函数
- 日期部分函数
- 枚举函数
- 间隔函数
- Lambda 函数
- 列表函数
- 映射函数
- 嵌套函数
- 数值函数
- 模式匹配
- 正则表达式
- 结构体函数
- 文本函数
- 时间函数
- 时间戳函数
- 带时区时间戳函数
- 联合函数
- 实用函数
- 窗口函数
- 约束
- 索引
- 元查询
- DuckDB 的 SQL 方言
- 示例
- 配置
- 扩展
- 核心扩展
- 概览
- 自动补全
- Avro
- AWS
- Azure
- Delta
- DuckLake
- 编码
- Excel
- 全文搜索
- httpfs (HTTP 和 S3)
- Iceberg
- ICU
- inet
- jemalloc
- MySQL
- PostgreSQL
- 空间
- SQLite
- TPC-DS
- TPC-H
- UI
- VSS
- 指南
- 概览
- 数据查看器
- 数据库集成
- 文件格式
- 概览
- CSV 导入
- CSV 导出
- 直接读取文件
- Excel 导入
- Excel 导出
- JSON 导入
- JSON 导出
- Parquet 导入
- Parquet 导出
- 查询 Parquet 文件
- 使用 file: 协议访问文件
- 网络和云存储
- 概览
- HTTP Parquet 导入
- S3 Parquet 导入
- S3 Parquet 导出
- S3 Iceberg 导入
- S3 Express One
- GCS 导入
- Cloudflare R2 导入
- 通过 HTTPS / S3 使用 DuckDB
- Fastly 对象存储导入
- 元查询
- ODBC
- 性能
- Python
- 安装
- 执行 SQL
- Jupyter Notebooks
- marimo Notebooks
- Pandas 上的 SQL
- 从 Pandas 导入
- 导出到 Pandas
- 从 Numpy 导入
- 导出到 Numpy
- Arrow 上的 SQL
- 从 Arrow 导入
- 导出到 Arrow
- Pandas 上的关系型 API
- 多个 Python 线程
- 与 Ibis 集成
- 与 Polars 集成
- 使用 fsspec 文件系统
- SQL 编辑器
- SQL 功能
- 代码片段
- 故障排除
- 术语表
- 离线浏览
- 操作手册
- 开发
- 内部结构
- 为什么选择 DuckDB
- 行为准则
- 发布日历
- 路线图
- 站点地图
- 在线演示
DuckDB 的 Python 客户端如果需要,可以直接在 Jupyter Notebook 中使用,无需额外配置。然而,可以使用额外的库来简化 SQL 查询开发。本指南将介绍如何利用这些额外的库。有关如何将 DuckDB 和 Python 结合使用的信息,请参阅 Python 部分的其他指南。
在此示例中,我们使用 JupySQL 包。此示例工作流也可以通过 Google Colab notebook 获取。
库安装
四个额外的库可以改善 Jupyter Notebooks 中的 DuckDB 使用体验。
- jupysql: 将 Jupyter 代码单元格转换为 SQL 单元格
- Pandas: 清晰的表格可视化以及与其他分析的兼容性
- matplotlib: 使用 Python 绘图
- duckdb-engine (DuckDB SQLAlchemy 驱动): 由 SQLAlchemy 用于连接 DuckDB(可选)
如果 Jupyter Notebook 尚未安装,请从命令行运行这些 pip install 命令。否则,请参阅上面的 Google Colab 链接以获取 Notebook 内的示例。
pip install duckdb
安装 Jupyter Notebook
pip install notebook
或 JupyterLab
pip install jupyterlab
安装支持库
pip install jupysql pandas matplotlib duckdb-engine
库导入和配置
打开 Jupyter Notebook 并导入相关库。
在 jupysql 上设置配置,以便直接将数据输出到 Pandas 并简化打印到 Notebook 的输出。
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
原生连接到 DuckDB
要连接到 DuckDB,请运行
import duckdb
import pandas as pd
%load_ext sql
conn = duckdb.connect()
%sql conn --alias duckdb
警告:原生 DuckDB 连接中不识别 变量。
通过 SQLAlchemy 连接到 DuckDB
或者,您可以使用 duckdb_engine 通过 SQLAlchemy 连接到 DuckDB。请参阅性能和功能差异。
import duckdb
import pandas as pd
# No need to import duckdb_engine
# jupysql will auto-detect the driver needed based on the connection string!
# Import jupysql Jupyter extension to create SQL cells
%load_ext sql
可以连接到新的内存中的 DuckDB、默认连接或文件支持的数据库。
%sql duckdb:///:memory:
%sql duckdb:///:default:
%sql duckdb:///path/to/file.db
如果将
duckdb:///:default:作为 SQLAlchemy 连接字符串提供,则%sql命令和duckdb.sql共享相同的默认连接。
查询 DuckDB
单行 SQL 查询可以在行首使用 %sql 运行。查询结果将显示为 Pandas DataFrame。
%sql SELECT 'Off and flying!' AS a_duckdb_column;
通过在单元格开头放置 %%sql,整个 Jupyter 单元格可以用作 SQL 单元格。查询结果将显示为 Pandas DataFrame。
%%sql
SELECT
schema_name,
function_name
FROM duckdb_functions()
ORDER BY ALL DESC
LIMIT 5;
要将查询结果存储在 Python 变量中,请使用 << 作为赋值运算符。这可以与 %sql 和 %%sql Jupyter magic 命令一起使用。
%sql res << SELECT 'Off and flying!' AS a_duckdb_column;
如果设置了 %config SqlMagic.autopandas = True 选项,则该变量是一个 Pandas 数据框;否则,它是一个 ResultSet,可以通过 DataFrame() 函数转换为 Pandas。
查询 Pandas DataFrames
DuckDB 能够找到并查询 Jupyter Notebook 中以变量形式存储的任何数据框。
input_df = pd.DataFrame.from_dict({"i": [1, 2, 3],
"j": ["one", "two", "three"]})
被查询的数据框可以在 FROM 子句中像其他任何表一样指定。
%sql output_df << SELECT sum(i) AS total_i FROM input_df;
警告:当使用 SQLAlchemy 连接且 DuckDB 版本 >= 1.1.0 时,请确保运行
%sql SET python_scan_all_frames=true,以使 Pandas 数据框可查询。
可视化 DuckDB 数据
在 Python 中绘制数据集最常见的方法是使用 Pandas 加载它们,然后使用 matplotlib 或 seaborn 进行绘图。这种方法需要将所有数据加载到内存中,效率极低。JupySQL 中的绘图模块在 SQL 引擎中运行计算。这将内存管理委托给引擎,并确保中间计算不会持续占用内存,从而高效地绘制大量数据集。
箱线图和直方图
要创建箱线图,请调用 %sqlplot boxplot,并传递表名和要绘制的列名。在此示例中,表名是本地存储的 Parquet 文件的路径。
from urllib.request import urlretrieve
_ = urlretrieve(
"https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet",
"yellow_tripdata_2021-01.parquet",
)
%sqlplot boxplot --table yellow_tripdata_2021-01.parquet --column trip_distance
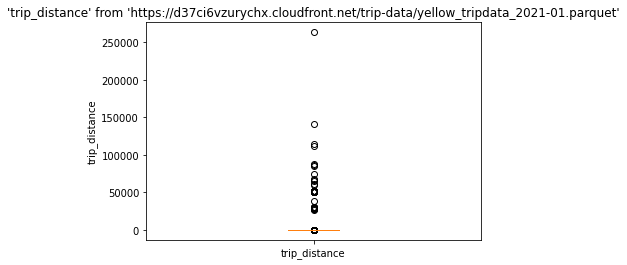
安装并加载 DuckDB httpfs 扩展
DuckDB 的 httpfs 扩展允许通过 http 远程查询 Parquet 和 CSV 文件。这些示例查询包含纽约市历史出租车数据的 Parquet 文件。使用 Parquet 格式允许 DuckDB 只将所需的行和列拉入内存,而不是下载整个文件。DuckDB 也可以用于处理本地 Parquet 文件,如果查询整个 Parquet 文件或运行需要文件大子集的多个查询,这可能是可取的。
%%sql
INSTALL httpfs;
LOAD httpfs;
现在,创建一个按第 90 百分位数过滤的查询。请注意 --save 和 --no-execute 函数的使用。这会告诉 JupySQL 存储查询,但跳过执行。它将在下一个绘图调用中被引用。
%%sql --save short_trips --no-execute
SELECT *
FROM 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet'
WHERE trip_distance < 6.3
要创建直方图,请调用 %sqlplot histogram 并传递表名、要绘制的列名和 bin 数量。这使用了 --with short-trips,因此 JupySQL 使用之前定义的查询,从而只绘制数据的子集。
%sqlplot histogram --table short_trips --column trip_distance --bins 10 --with short_trips
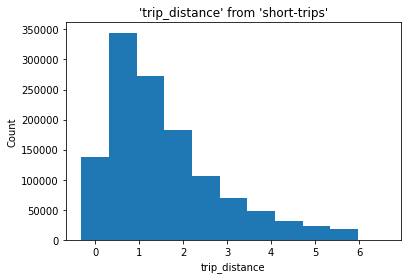
总结
现在,您能够以简单且高性能的方式在 SQL 和 Pandas 之间切换!您可以直接通过引擎绘制大量数据集(避免下载整个文件和将其全部加载到 Pandas 内存中)。数据框可以在 SQL 中作为表读取,SQL 结果可以输出到 DataFrames。祝您分析愉快!
jupysql 的替代方案是 magic_duckdb。