通过 GitHub 发现 DuckDB 用例
TL;DR: 在本文中,我们使用 GitHub API 查找提及 DuckDB 的仓库,然后使用 DuckDB 本身,通过 SQL 高效地解析和查询结果。
介绍
维护开源库面临的长期挑战之一是缺乏对其使用方式、地点和使用者可见性。在 DuckDB,我们会查看 awesome-duckdb 仓库,其中包含精选的 DuckDB 库、工具和资源列表。为了补充这一点,我们希望自动化从 GitHub 获取洞察,以发现使用 DuckDB 的新兴项目。在本文中,我们阐述了如何使用 DuckDB 查询 GitHub API,将数据导出到 Markdown 文件,并可视化从 Git 提交生成的历史数据。
从 GitHub 检索数据
GitHub 提供了一系列 REST API,可用于从 GitHub 检索数据。其中,搜索仓库 API 返回一个公共仓库列表,其名称、描述或 README 与搜索文本匹配。
GitHub 还有一个搜索代码 API,用于匹配代码依赖项,但它不会返回搜索仓库 API 提供的所有信息。可以先使用搜索代码 API,然后针对每个结果从仓库 API 检索仓库信息。
为了使用 GitHub API,我们创建了一个对公共仓库具有读取权限的访问令牌。将访问令牌保存为环境变量后,我们在 DuckDB 中创建了一个秘密,供 API 请求使用
import os
import duckdb
def get_duckdb_conn():
conn = duckdb.connect()
conn.sql(f"""
CREATE SECRET http_auth (
TYPE http,
BEARER_TOKEN '{os.getenv("READ_PUBLIC_REPO_TOKEN")}',
SCOPE 'https://api.github.com/search'
);
""")
return conn
通过 DuckDB Python 客户端的 read_json 函数,我们能够使用 SQL 查询 API 响应。上述秘密由 DuckDB 自动传递给 API 调用
duckdb_conn = get_duckdb_conn()
api_response = duckdb_conn.read_json(
"https://api.github.com/search/repositories?q=duckdb"
)
API 调用返回以下响应
┌─────────────┬────────────────────┬──────────────────────────────────────┐
│ total_count │ incomplete_results │ items │
│ int64 │ boolean │ struct(id bigint, node_id varchar,...│
├─────────────┼────────────────────┼──────────────────────────────────────┤
│ 3837 │ false │ [{'id': 138754790, 'node_id': ... │
└─────────────┴────────────────────┴──────────────────────────────────────┘
我们可以通过以下方式分析响应
- 使用
api_response.columns获取列列表['total_count', 'incomplete_results', 'items'] - 获取列类型
api_response.types[ BIGINT, BOOLEAN, STRUCT(id BIGINT, node_id VARCHAR, "name" VARCHAR, full_name VARCHAR, private BOOLEAN, "owner" STRUCT(login VARCHAR, id BIGINT, node_id VARCHAR, avatar_url VARCHAR, gravatar_id VARCHAR, url VARCHAR, html_url VARCHAR, followers_url VARCHAR, following_url VARCHAR, gists_url VARCHAR, starred_url VARCHAR, subscriptions_url VARCHAR, organizations_url VARCHAR, repos_url VARCHAR, events_url VARCHAR, received_events_url VARCHAR, "type" VARCHAR, user_view_type VARCHAR, site_admin BOOLEAN), html_url VARCHAR, description VARCHAR, fork BOOLEAN, url VARCHAR, forks_url VARCHAR, keys_url VARCHAR, collaborators_url VARCHAR, teams_url VARCHAR, hooks_url VARCHAR, issue_events_url VARCHAR, events_url VARCHAR, assignees_url VARCHAR, branches_url VARCHAR, tags_url VARCHAR, blobs_url VARCHAR, git_tags_url VARCHAR, git_refs_url VARCHAR, trees_url VARCHAR, statuses_url VARCHAR, languages_url VARCHAR, stargazers_url VARCHAR, contributors_url VARCHAR, subscribers_url VARCHAR, subscription_url VARCHAR, commits_url VARCHAR, git_commits_url VARCHAR, comments_url VARCHAR, issue_comment_url VARCHAR, contents_url VARCHAR, compare_url VARCHAR, merges_url VARCHAR, archive_url VARCHAR, downloads_url VARCHAR, issues_url VARCHAR, pulls_url VARCHAR, milestones_url VARCHAR, notifications_url VARCHAR, labels_url VARCHAR, releases_url VARCHAR, deployments_url VARCHAR, created_at TIMESTAMP, updated_at TIMESTAMP, pushed_at TIMESTAMP, git_url VARCHAR, ssh_url VARCHAR, clone_url VARCHAR, svn_url VARCHAR, homepage VARCHAR, size BIGINT, stargazers_count BIGINT, watchers_count BIGINT, "language" VARCHAR, has_issues BOOLEAN, has_projects BOOLEAN, has_downloads BOOLEAN, has_wiki BOOLEAN, has_pages BOOLEAN, has_discussions BOOLEAN, forks_count BIGINT, mirror_url JSON, archived BOOLEAN, disabled BOOLEAN, open_issues_count BIGINT, license STRUCT("key" VARCHAR, "name" VARCHAR, spdx_id VARCHAR, url VARCHAR, node_id VARCHAR), allow_forking BOOLEAN, is_template BOOLEAN, web_commit_signoff_required BOOLEAN, topics VARCHAR[], visibility VARCHAR, forks BIGINT, open_issues BIGINT, watchers BIGINT, default_branch VARCHAR, permissions STRUCT("admin" BOOLEAN, maintain BOOLEAN, push BOOLEAN, triage BOOLEAN, pull BOOLEAN), score DOUBLE)[] ] - 使用
api_response.select("len(items)")获取项目数量┌────────────┐ │ len(items) │ │ int64 │ ├────────────┤ │ 30 │ └────────────┘
提及 DuckDB 的仓库总数为 3837 个,但 items 对象仅包含 30 个。这是由于分页默认设置为每页 30 条记录。我们可以通过使用 per_page 查询参数来检索最多 100 条记录。此外,我们使用 page 查询参数来检索每页的结果
(
duckdb_conn
.read_json("https://api.github.com/search/repositories?q=duckdb&per_page=100&page=2")
.select("len(items)")
)
┌────────────┐
│ len(items) │
│ int64 │
├────────────┤
│ 100 │
└────────────┘
由于 GitHub 在搜索 API 中最多返回 1000 个结果,并且我们每天检索数据,因此我们添加了一个过滤器,仅检索在过去 7 天内有推送的仓库
api_url = "https://api.github.com/search/repositories?q=duckdb"
last_pushed_date = (datetime.now() - timedelta(days=7)).strftime("%Y-%m-%d")
api_url = f"{api_url}+pushed:>={last_pushed_date}"
duckdb_conn.read_json(f"{api_url}&per_page=100&page=1").to_table("github_raw_data")
我们将第一页存储在一个名为 github_raw_data 的表中,并根据第一次调用返回的总计数计算需要检索的页数。然后,使用 insert_into 方法,我们将每页的数据附加到 github_raw_data 中
for page in range(2, number_pages + 1):
logger.info(f"Fetching {page} out of {number_pages}")
(
duckdb_conn
.read_json(f"{api_url}&per_page=100&page={page}")
.insert_into("github_raw_data")
)
将数据保存到 Markdown 文件
有了表中可用的数据,我们可以继续进行数据处理,方法是使用 unnest 函数,它将展平 API 返回的 items
(
duckdb_conn.table("github_raw_data")
.select("unnest(items, recursive := true)")
)
通过使用递归展平,items 中的 STRUCT 对象也将被展平;下面是展平后从 items 派生的一些列的示例
['id',
'node_id',
'name',
'full_name',
'private',
'login',
'id',
...
'pull',
'score']
我们的目标是创建一个包含以下格式表格的 Markdown 文件
- name,包含仓库的名称、链接、描述、许可证和所有者;
- topics,仓库的主题列表;
- stars,星标数量;
- open issues,未解决问题数量;
- forks,分支数量;
- created at,仓库创建时间;
- updated at,仓库上次更新时间。
为了检索 name 字段,我们使用 concat_ws 和 concat 函数,以生成带有 Markdown 换行符(<br>)的超链接和文本
selection_query = (
duckdb_conn.table("github_raw_data")
.select("unnest(items, recursive := true)")
.select("""
concat_ws(
'<br>',
concat('[', name, '](', concat('https://github.com/', full_name),')'),
coalesce(description, ' '),
concat('**License** ', coalesce(name_1, 'unknown')),
concat('**Owner** ', login)
) as repo_details
""")
)
上述返回
repo_details = [duckdb-web](https://github.com/duckdb/duckdb-web)<br>DuckDB website and documentation<br>**License** MIT License<br>**Owner** duckdb
repo_details = [duckdb](https://github.com/duckdb/duckdb)<br>DuckDB is an analytical in-process SQL database management system<br>**License** MIT License<br>**Owner** duckdb
...
我们还计算了星标、未解决问题数量和分支等指标,并将它们汇总到一个字段 activity_count 中。一个仓库只有在其 activity_count 大于 3 且不是分支时才会出现在列表中。从上面我们还看到 DuckDB 拥有的仓库也被返回了,因此我们也将它们过滤掉
selection_query.filter("""
login != 'duckdb'
and not fork
and activity_count >= 3
""")
Markdown 表格类似于 CSV 文件,由竖线(|)分隔,但它必须
- 在每行的开头和结尾包含分隔符;
- 在表头和第一行之间需要有一行虚线(称为分隔行)。
为了将数据导出为 Markdown 文件,我们应用了一些技巧。第一个技巧是在开头和结尾添加包含 NULL 的虚拟列来选择表头
duckdb_conn.sql("""
select
NULL,
'Name',
'Topics',
'Stars',
'Open Issues',
'Forks',
'Created At',
'Updated At',
NULL
""")
然后我们将上述表头与分隔行合并(union)
.union(
duckdb_conn.sql("""
select
NULL as '',
'--' as "Name",
'--' as "Topics",
'--' as "Stars",
'--' as "Open Issues",
'--' as "Forks",
'--' as "Created At",
'--' as "Updated At",
NULL as ''
""")
)
返回
┌───────┬─────────┬──────────┬─────────┬───────────────┬─────────┬──────────────┬──────────────┬───────┐
│ NULL │ 'Name' │ 'Topics' │ 'Stars' │ 'Open Issues' │ 'Forks' │ 'Created At' │ 'Updated At' │ NULL │
│ int32 │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ int32 │
├───────┼─────────┼──────────┼─────────┼───────────────┼─────────┼──────────────┼──────────────┼───────┤
│ NULL │ Name │ Topics │ Stars │ Open Issues │ Forks │ Created At │ Updated At │ NULL │
│ NULL │ -- │ -- │ -- │ -- │ -- │ -- │ -- │ NULL │
└───────┴─────────┴──────────┴─────────┴───────────────┴─────────┴──────────────┴──────────────┴───────┘
最后,我们与初始的 GitHub 选择查询合并(union),并通过禁用标题导出将数据导出到 CSV
.union(selection_query)
).to_csv("./exported_records.md", sep="|", header=False)
下面是 exported_records.md 文件的一个示例,渲染为 HTML
| 名称 | 主题 | 星标 | 未解决问题 | 分支 | 创建时间 | 更新时间 |
|---|---|---|---|---|---|---|
| tailpipe select * from logs; 许可证 GNU Affero General Public License v3.0 所有者 turbot |
[aws, azure, detections, devops, duckdb, forensics, gcp, incident-response, log-analysis, mitre-attack, open-source, parquet, siem, tailpipe, threat-detection] | 438 | 41 | 9 | 2024-04-18 02:44:35 | 2025-06-17 11:57:42 |
您可能会问,为什么是 Markdown 文件?因为 GitHub 会自动渲染它,无需将我们的小型数据应用程序托管在其他地方。事实上,我们将上述表格复制到 README 中,以便它自动显示在仓库的第一页
echo '# Repositories using `duckdb`' > README.md && \
cat exported_records.md >> README.md
创建 README 文件的另一种方法是使用 string_agg 函数
selected_data = (
selection_query
.select("""
concat(
'|',
concat_ws(
'|',
repo_details,
topics, stars,
open_issues,
forks,
created_at,
updated_at
)
) as line
""")
.string_agg(
'line',
sep='|\n'
)
).fetchone()[0]
with open('README.md', 'w') as readme_file:
readme_file.write("# Repositories using `duckdb`\n")
readme_file.write("|Name|Topics|Stars|Open Issues|Forks|Created At|Updated At|\n")
readme_file.write(f"{duckdb_conn.sql("select concat(repeat('|--', 7),'|')").fetchone()[0]}\n")
readme_file.write(f"{selected_data}|")
在上面的代码片段中,我们用竖线字符连接列,然后将记录聚合为一个字符串,以 |\n 分隔,以便在每行末尾添加一个竖线和换行符。然后我们使用 Python 将页面标题、Markdown 表格标题、分隔行(通过使用 repeat 函数)和数据本身写入 README。
数据量非常小,每次提交的 README 大约 35 KB。
使用 GitHub 工作流实现自动化
通过 GitHub 工作流,我们自动化了上述数据处理步骤。我们首先在项目中定义一个 Makefile,以配置需要在工作流中执行的步骤
search-repos:
uv run using_duckdb/search_repositories.py
readme:
echo '# Repositories using `duckdb`' > README.md && \
cat exported_records.md >> README.md
在 GitHub 仓库的设置中,我们创建一个仓库秘密,其中包含上面生成的 API 令牌的值。然后我们可以在工作流中配置环境变量并定义处理步骤
name: Search
on:
workflow_dispatch:
schedule:
- cron: '37 5 * * *'
env:
READ_PUBLIC_REPO_TOKEN : $
jobs:
make-readme-md:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- uses: actions/checkout@v4
with:
ref: $
fetch-depth: 0
- name: Install uv
uses: astral-sh/setup-uv@v6
- name: Install the project
run: uv sync
- name: Get search results
run: make search-repos
- name: Export current results
run: make readme
- name: Get datetime
id: datetime
run: echo "datetime=$(date -u +'%Y-%m-%dT%H:%M:%SZ')" >> $GITHUB_OUTPUT
- uses: stefanzweifel/git-auto-commit-action@v5
with:
commit_message: 'Update as of $'
file_pattern: 'README.md'
通过 git-auto-commit-action,我们将创建包含更新后的 README.md 文件的提交的权限委托给 GitHub
可视化历史数据
由于我们将搜索结果存储在 README 文件中并每天用 Git 更新,因此我们可以通过获取每次提交的 Git 差异来检索搜索历史
git-log:
echo '|Name|Topics|Stars|Open Issues|Forks|Created At|Updated At|' > git_log.md && \
echo '|--|--|--|--|--|--|--|' >> git_log.md && \
git log --follow -p --pretty=format:"" -- README.md | grep '^+|\[' | sed 's/^+//' >> git_log.md && \
git diff -- README.md | grep '^+|\[' | sed 's/^+//' >> git_log.md
在上述 Makefile 命令中,我们
- 创建一个文件
git_log.md,其第一行是 Markdown 表格的标题; - 向
git_log.md添加分隔行; - 对于每次提交,将 README 差异的新行附加到
git_log.md; - 将当前 README 更改的新行附加到
git_log.md。
git_log.md 现在包含了附加到 README 文件中的所有记录的历史,并且可以用于显示提及 DuckDB 的仓库的气泡图
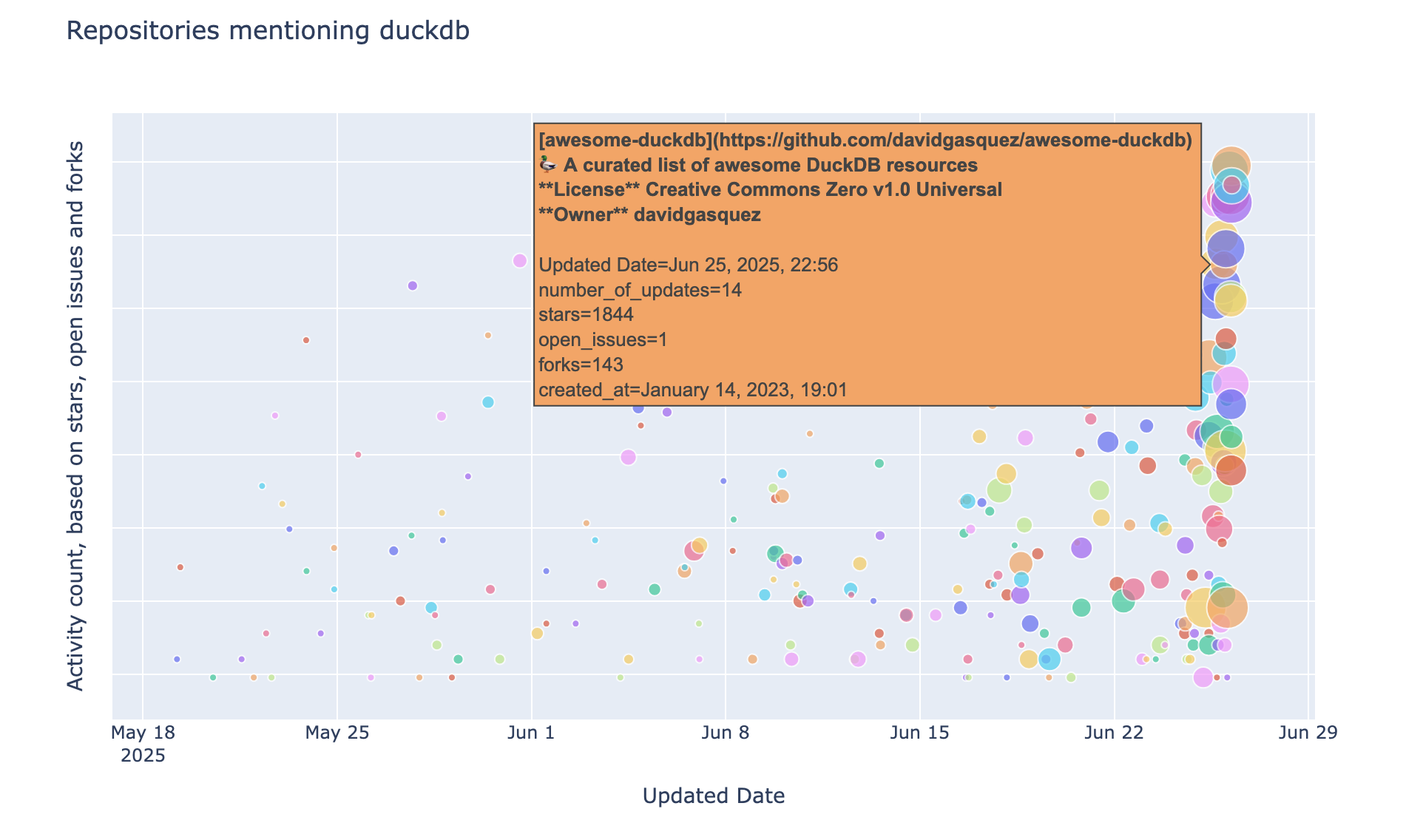
上述图表是使用 Plotly 生成的,其数据源为 DuckDB Python 关系
px.scatter(
duckdb_conn.read_csv(
"./git_log.md"
skiprows=2
)
.select("""
#2 as repo,
#3 as topics,
#4 as stars,
#5 as open_issues,
#6 as forks,
strftime(#7, '%B %d, %Y, %H:%m' ) as created_at,
#8 as updated_at,
if(stars + forks + open_issues = 0, 0, log(stars + forks + open_issues)) as log_activity_count,
substr(repo, position('[' in repo) + 1 , position(']' in repo) - 2) as repo_name,
count(distinct updated_at::date) over (partition by repo_name) as number_of_updates,
row_number() over (partition by repo_name order by updated_at desc) as rn
""")
.filter("rn = 1")
.order("updated_at"),
x="updated_at",
y="log_activity_count",
labels={
"updated_at": "Updated Date",
"log_activity_count": "Activity count, based on stars, open issues and forks"
},
...
将 Markdown 用作历史数据的文件格式可能不是最佳解决方案,因为它——除其他外——不支持模式演进。虽然我们无法在文件中间进行更改(除了列重命名),但由于 DuckDB 读取格式错误的 CSV 文件的方式,我们可以删除最后一列或在末尾添加新列。
结论
在本文中,我们展示了如何使用 DuckDB 处理 API 请求和来自 Git 提交的历史数据。GitHub 搜索 API 返回的一些仓库已收录到 awesome-duckdb,这是我们精选的 DuckDB 相关项目列表;例如 tailpipe,一个用于即时日志洞察的开源安全信息和事件管理系统,以及 preswald,一个用于基于 Python 的交互式数据应用程序的 Wasm 打包器。

