使用 DuckDB 的轻量级文本分析工作流
摘要:本文演示了如何使用 DuckDB 进行关键词、全文和基于嵌入的语义相似度搜索。
介绍
文本分析是许多现代数据工作流的核心组件,涵盖关键词匹配、全文搜索和语义比较等任务。传统工具通常需要复杂的管道和大量基础设施,这可能带来显著挑战。DuckDB 提供了一个高性能的 SQL 引擎,可以简化和优化文本分析。在本文中,我们将演示如何利用 DuckDB 在 Python 中高效执行高级文本分析。
以下实现是在 marimo Python notebook 中执行的,该 notebook 可在 GitHub 上的我们的示例存储库中找到。
数据准备
我们将使用 Hugging Face 上提供的一个公共数据集,该数据集包含英文 Twitter 消息及其对以下情感之一的分类:愤怒、恐惧、喜悦、爱、悲伤和惊讶。
借助 DuckDB,我们可以通过 hf:// 前缀访问 Hugging Face 数据集
from_hf_rel = conn.read_parquet(
"hf://datasets/dair-ai/emotion/unsplit/train-00000-of-00001.parquet",
file_row_number=True
)
from_hf_rel = from_hf_rel.select("""
text,
label as emotion_id,
file_row_number as text_id
""")
from_hf_rel.to_table("text_emotions")
如何使用 DuckDB 访问 Hugging Face 数据集的详细信息已在文章“使用 DuckDB 访问 Hugging Face 上的 15 万+ 数据集”中详细说明。
在上述数据中,我们只有情感标识符(emotion_id),没有其描述性信息。因此,我们根据数据集描述中提供的列表,通过解嵌套 Python 列表并使用 generate_subscripts 函数检索每个值的索引来创建一个引用表
emotion_labels = ["sadness", "joy", "love", "anger", "fear", "surprise"]
from_labels_rel = conn.values([emotion_labels])
from_labels_rel = from_labels_rel.select("""
unnest(col0) as emotion,
generate_subscripts(col0, 1) - 1 as emotion_id
""")
from_labels_rel.to_table("emotion_ref")
最后,我们通过连接这两个表来定义一个关系
text_emotions_rel = conn.table("text_emotions").join(
conn.table("emotion_ref"), condition="emotion_id"
)
通过执行
text_emotions_rel.to_view("text_emotions_v", replace=True),将创建一个名为text_emotions_v的视图,该视图可在 SQL 单元中使用。
我们在条形图上绘制情感分布,以便对数据有一个初步的了解
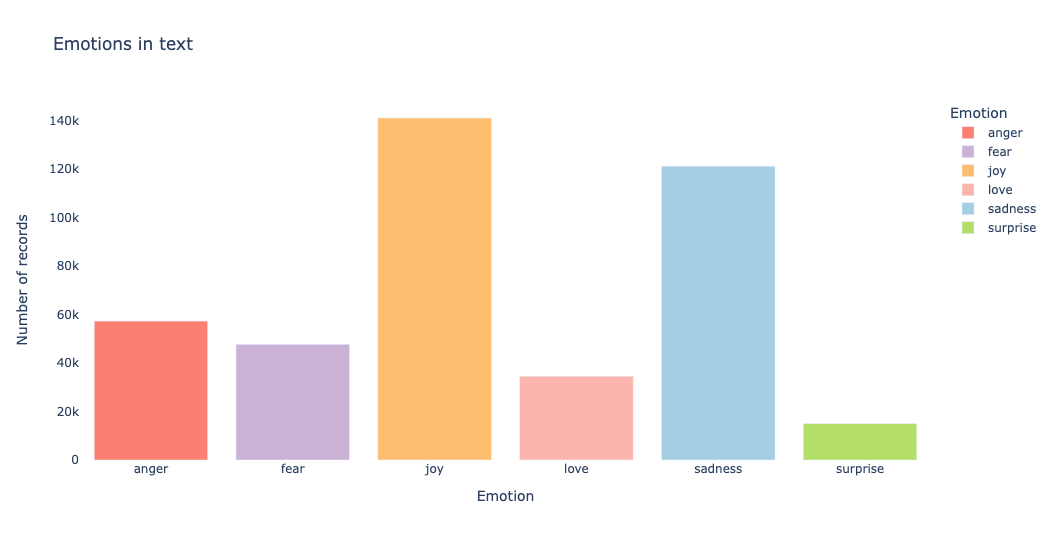
关键词搜索
关键词搜索是最基本的文本检索形式,它使用 SQL 条件(例如 CONTAINS、ILIKE 或其他 DuckDB 文本函数)来匹配文本字段中的精确单词或短语。它速度快,无需预处理,并且适用于过滤日志、匹配标签或查找产品名称等结构化查询。
例如,获取包含短语 excited to learn 的文本及其情感标签,只需对上面定义的关系应用 filter 即可
text_emotions_rel.filter("text ilike '%excited to learn%'").select("""
emotion,
substring(
text,
position('excited to learn' in text),
len('excited to learn')
) as substring_text
""")
┌─────────┬──────────────────┐
│ emotion │ substring_text │
│ varchar │ varchar │
├─────────┼──────────────────┤
│ sadness │ excited to learn │
│ joy │ excited to learn │
│ joy │ excited to learn │
│ fear │ excited to learn │
│ fear │ excited to learn │
│ joy │ excited to learn │
│ joy │ excited to learn │
│ sadness │ excited to learn │
└─────────┴──────────────────┘
文本处理中一个常见的步骤是将文本拆分为标记(关键词),其中原始文本被分解成更小的单元(通常是单词),可以进行分析或索引。这个过程被称为“标记化”,有助于将非结构化文本转换为适合关键词搜索的结构化形式。在 DuckDB 中,这个过程可以通过 regexp_split_to_table 函数实现,该函数将根据提供的正则表达式拆分文本,并返回每一行上的每个关键词。
在下面的代码片段中,我们通过将文本按照一个或多个非单词字符(`[a-zA-Z0-9_]` 之外的任何字符)进行拆分来选择所有关键词
text_emotions_tokenized_rel = text_emotions_rel.select("""
text_id,
emotion,
regexp_split_to_table(text, '\\W+') as token
""")
在标记化步骤中,我们通常会排除常用词(例如 and、the),这些词被称为“停用词”。在 DuckDB 中,我们通过对 GitHub 上托管的一个精选 CSV 文件应用 ANTI JOIN 来实现排除
english_stopwords_rel = duckdb_conn.read_csv(
"https://raw.githubusercontent.com/stopwords-iso/stopwords-en/refs/heads/master/stopwords-en.txt",
header=False,
).select("column0 as token")
text_emotions_tokenized_rel.join(
english_stopwords_rel,
condition="token",
how="anti",
).to_table("text_emotion_tokens")
现在我们已经对文本进行了标记化和清理,可以通过使用相似度函数(如 Jaccard)对匹配进行排序来实现关键词搜索
text_token_rel = conn.table(
"text_emotion_tokens"
).select("token, emotion, jaccard(token, 'learn') as jaccard_score")
text_token_rel = text_token_rel.max(
"jaccard_score",
groups="emotion, token",
projected_columns="emotion, token"
)
text_token_rel.order("3 desc").limit(10)
┌──────────┬─────────┬────────────────────┐
│ emotion │ token │ max(jaccard_score) │
│ varchar │ varchar │ double │
├──────────┼─────────┼────────────────────┤
│ fear │ learn │ 1.0 │
│ surprise │ learn │ 1.0 │
│ love │ learn │ 1.0 │
│ joy │ lerna │ 1.0 │
│ sadness │ learn │ 1.0 │
│ fear │ learner │ 1.0 │
│ anger │ learn │ 1.0 │
│ joy │ leaner │ 1.0 │
│ fear │ allaner │ 1.0 │
│ anger │ learner │ 1.0 │
├──────────┴─────────┴────────────────────┤
│ 10 rows 3 columns │
└─────────────────────────────────────────┘
我们还可以可视化数据以获取洞察。一种简单有效的方法是绘制最常用词。通过计算数据集中标记的出现次数并将其显示在气泡图中,我们可以快速识别文本中的主导主题、重复关键词或异常模式。例如,我们按情感使用散点分面图绘制数据
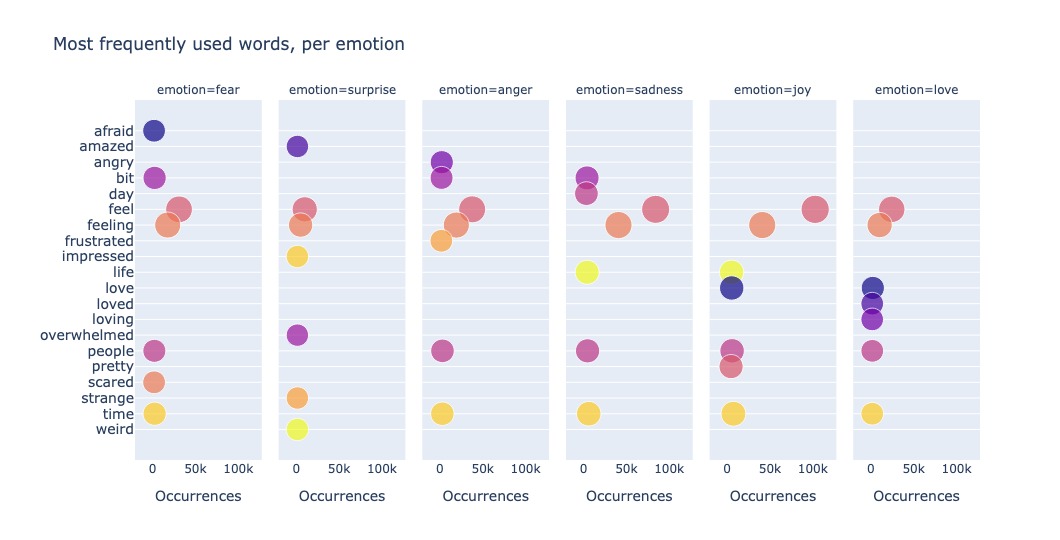
从上图中,我们观察到重复的关键词,例如 feel - feeling、love - loved - loving。为了对这类数据进行去重,我们需要查看词干而不是单词本身。这引导我们进入全文搜索。
全文搜索
DuckDB 全文搜索 (FTS) 扩展是一个实验性扩展,它实现了两个主要的全文搜索功能:
stem函数,用于检索词干;match_bm25函数,用于计算最佳匹配得分。
通过将 stem 应用于标记列,我们现在可以可视化数据中最常用的词干
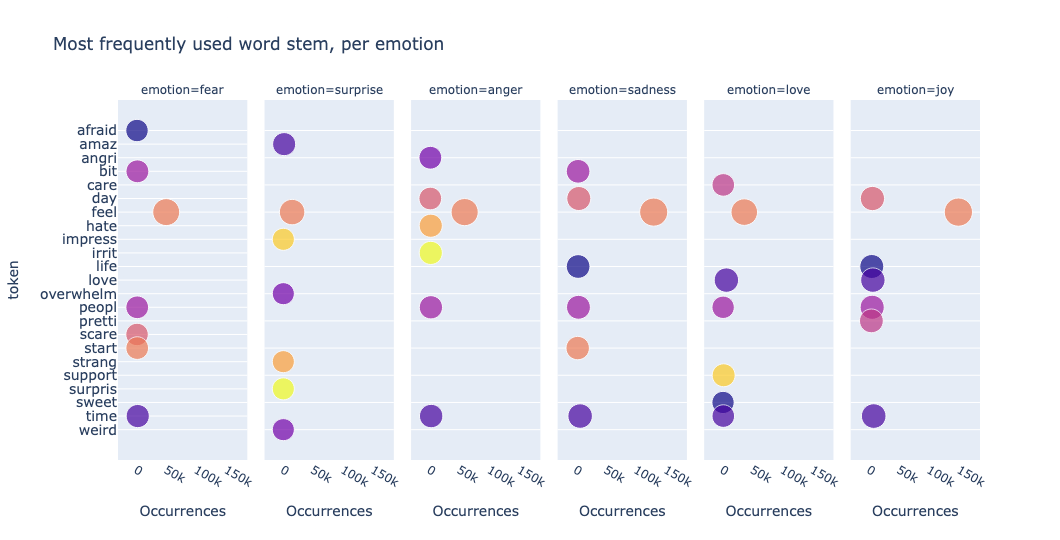
我们观察到 feel 和 love 只出现一次,并绘制了新的词干,例如 support、surpris。
虽然 stem 函数可以单独使用,但 match_bm25 函数需要构建一个 FTS 索引,这是一种特殊索引,通过对列中的单词(标记)进行索引,实现快速高效的文本搜索
conn.sql("""
PRAGMA create_fts_index(
"text_emotions",
text_id,
"text",
stemmer = 'english',
stopwords = 'english_stopwords',
ignore = '(\\.|[^a-z])+',
strip_accents = 1,
lower = 1,
overwrite = 1
)
""")
在 FTS 索引创建中,我们使用与标记化过程相同的英语停用词列表,将其保存到一个名为 english_stopwords 的表中。该索引由于 lower 参数的存在而对大小写不敏感,该参数会自动将文本转换为小写。
警告:该索引只能在表上创建,并且需要文本的唯一标识符。当底层数据被修改时,还需要重建索引。
索引创建完成后,我们可以对文本列与短语 excited to learn 之间的匹配进行排序
text_emotions_rel
.select("""
emotion,
text,
emotion_color,
fts_main_text_emotions.match_bm25(
text_id,
'excited to learn'
)::decimal(3, 2) as bm25_score
""")
.order("bm25_score desc")
.limit(10)
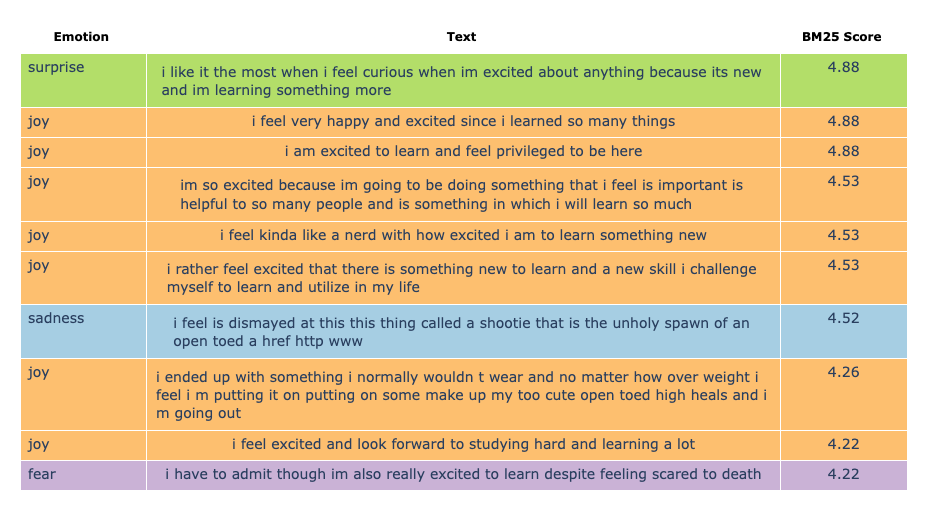
在上面以表格图形式显示的 10 个返回文本中,有 2 个与我们的搜索输入匹配度较差;这可能是由于 BM25 评分因常用词或文档长度差异而产生偏差。
语义搜索
与关键词和全文搜索相比,语义搜索考虑了文本的含义和上下文。它不仅仅寻找精确的单词,还使用向量嵌入等技术来捕捉底层概念。语义搜索不区分大小写,可以通过利用(同样是实验性的)向量相似度搜索扩展在 DuckDB 中实现。
文本(列表)的向量嵌入可以使用 sentence-transformers 库和预训练模型 all-MiniLM-L6-v2 进行计算
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def get_text_embedding_list(list_text: list[str]):
"""
Return the list of normalized vector embeddings for list_text.
"""
return model.encode(list_text, normalize_embeddings=True)
例如,get_text_embedding_list(['excited to learn']) 将返回
array([[ 3.14795598e-02, -6.66208193e-02, 1.05058309e-02,
4.12571728e-02, -8.67664907e-03, -1.79746319e-02,
...
-2.50727013e-02, -3.00881546e-03, 1.55055271e-02]], dtype=float32)
我们将模型推理函数注册为 Python 用户定义函数,并创建一个包含 FLOAT[384] 类型列的表,以便将嵌入加载到其中
conn.create_function(
"get_text_embedding_list",
get_text_embedding_list,
return_type='FLOAT[384][]'
)
conn.sql("""
create table text_emotion_embeddings (
text_id integer,
text_embedding FLOAT[384]
)
""")
借助 Python UDF,我们批量保存模型输出到 text_emotion_embeddings 中
for i in range(num_batches):
selection_query = (
duckdb_conn.table("text_emotions")
.order("text_id")
.limit(batch_size, offset=batch_size*i)
.select("*")
)
(
selection_query.aggregate("""
array_agg(text) as text_list,
array_agg(text_id) as id_list,
get_text_embedding_list(text_list) as text_emb_list
""").select("""
unnest(id_list) as text_id,
unnest(text_emb_list) as text_embedding
""")
).insert_into("text_emotion_embeddings")
我们在文章《使用 DuckDB 和 scikit-learn 进行机器学习原型开发》中介绍了 DuckDB 中的模型推理。
现在,我们可以通过使用搜索文本 excited to learn 的向量嵌入与 text 字段的嵌入之间的余弦距离来执行语义搜索
input_text_emb_rel = conn.sql("""
select get_text_embedding_list(['excited to learn'])[1] as input_text_embedding
""")
text_emotions_rel
.join(conn.table("text_emotion_embeddings"), condition="text_id")
.join(input_text_emb_rel, condition="1=1")
.select("""
text,
emotion,
emotion_color,
array_cosine_distance(
text_embedding,
input_text_embedding
)::decimal(3, 2) as cosine_distance_score
""")
.order("cosine_distance_score asc")
.limit(10)
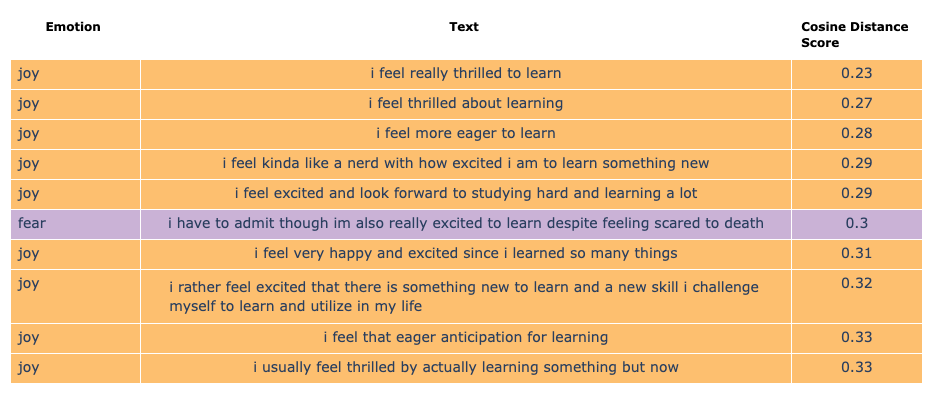
有趣的是,短语 i am excited to learn and feel privileged to be here 并未进入我们语义搜索的前 10 名结果!
相似度连接
向量嵌入最广为人知的是它们在搜索引擎中的可用性,但它们也可用于各种文本分析用例,例如主题分组、分类或文档间的语义匹配。VSS 扩展提供了向量相似度连接,可用于执行这些类型的分析。
例如,我们在下面的热力图表中显示了每种情感标签组合的文本数量,其中 x 轴对应文本与情感之间的语义匹配,y 轴对应分类的情感,颜色则表示分配给每对组合的文本计数

特别值得注意的是,在 6 种情感中,只有 sadness 与被归类为相同标签的文本有很强的语义匹配。与全文搜索一样,语义搜索也受到文档长度差异的影响(在此例中是情感关键词与文本之间的差异)。
混合搜索
尽管每种搜索类型都有其适用性,但我们观察到某些结果并未如预期
- 关键词搜索和全文搜索不考虑词义;
- 语义搜索将同义词的得分高于搜索文本。
实践中,这三种搜索方法被结合起来,用于执行“混合搜索”,以提高搜索相关性和准确性。我们首先通过实现自定义逻辑(例如对情感进行检查)来计算每种搜索类型的得分
if(
emotion = 'joy' and contains(text, 'excited to learn'),
1,
0
) exact_match_score,
fts_main_text_emotions.match_bm25(
text_id,
'excited to learn'
)::decimal(3, 2) as bm25_score,
array_cosine_similarity(
text_embedding,
input_text_embedding
)::decimal(3, 2) as cosine_similarity_score
BM25 分数按降序排序,余弦距离按升序排序。在混合搜索中,我们使用 array_cosine_similarity 分数来确保相同的排序顺序(在此例中为降序)。
余弦相似度 = 1 - 余弦距离
由于 BM25 分数理论上可以是无界的,我们需要通过实现最小-最大归一化将分数缩放到 [0, 1] 区间
max(bm25_score) over () as max_bm25_score,
min(bm25_score) over () as min_bm25_score,
(bm25_score - min_bm25_score) / nullif((max_bm25_score - min_bm25_score), 0) as norm_bm25_score
混合搜索得分通过对 BM25 和余弦相似度得分应用权重来计算
if(
exact_match_score = 1,
exact_match_score,
cast(
0.3 * coalesce(norm_bm25_score, 0) +
0.7 * coalesce(cosine_similarity_score, 0)
as
decimal(3, 2)
)
) as hybrid_score
结果如下!是不是好多了?

结论
在本文中,我们展示了 DuckDB 如何通过结合关键词、全文和语义搜索技术用于文本分析。利用实验性的 fts 和 vss 扩展以及 sentence-transformers 库,我们演示了 DuckDB 如何同时支持传统和现代文本分析工作流。

