DuckDB 的 CSV 读取器与 Pollock 鲁棒性基准测试:深入 CSV 深渊
总结:DuckDB 内置了一个快速且鲁棒的 CSV 读取器,我们相信它可以处理大多数野外发现的 CSV 文件。为了经验性地评估这一点,我们使用了 Pollock 基准测试——一个旨在衡量 CSV 读取器在非标准文件上运行情况的最新测试套件,结果发现 DuckDB 位居榜首。

CSV 生态的困境
众所周知,CSV 文件形式多样。尽管存在一个明确定义的标准,但系统在导出数据时却常常不遵循 CSV 构建的基本规则。例如,荷兰最大的银行之一 Rabobank 在导出客户财务数据时,其引用值中包含未转义的引号。
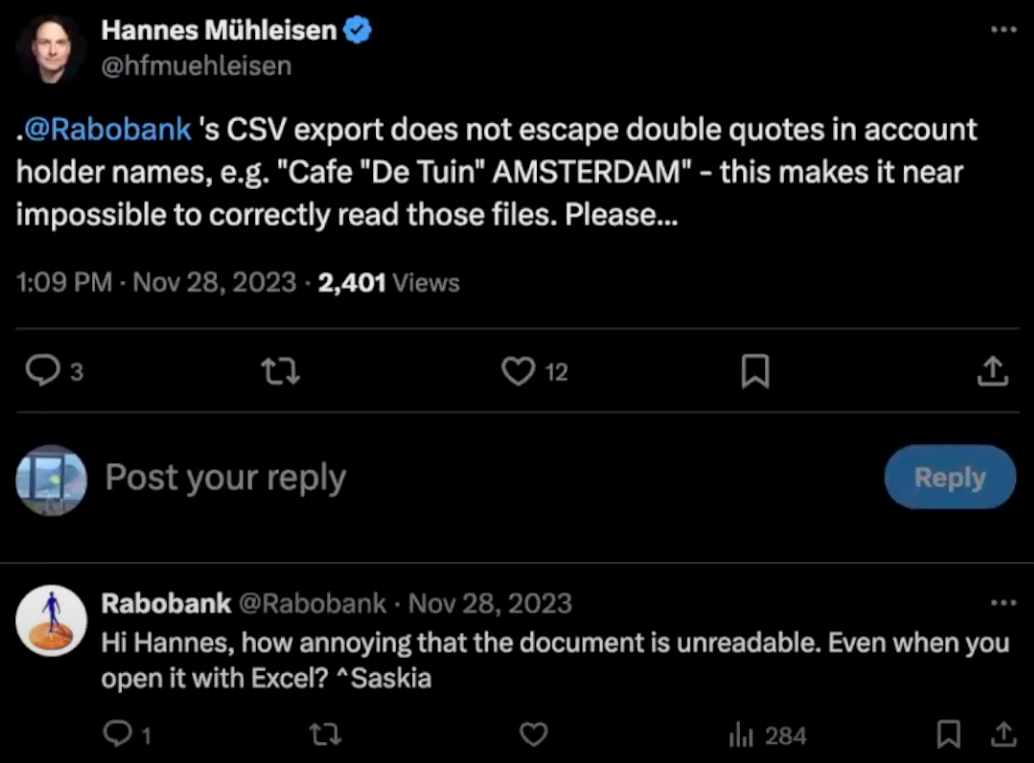
如果一个大型金融机构都无法编写正确的 CSV 文件,那么想想那些由几十年前的遗留软件导出、手写以及从电子表格软件导出的 CSV 文件中会发生多少错误!这类错误非常普遍,以至于电子表格软件、数据框库和专业的 CSV 工具都超常发挥,以挽救这些文件并将其整理成用户可以使用的表格。
DuckDB 的 CSV 解析器
在设计 DuckDB CSV 解析器时,我们力求确保它不仅易用、快速,而且极其可靠——甚至能够读取大多数抛给它的 CSV 文件。在这篇博客文章中,我们从两个角度探讨了这一点。首先,我们探讨了可以帮助您读取非标准 CSV 文件的主要选项,并通过一些简单示例展示它们对解析的影响。其次,我们通过使用 Pollock 基准测试来评估 DuckDB CSV 解析器的鲁棒性。
互联网上有很多关于系统是否应该不遗余力地读取不符合标准的文件。确实,非标准文件令人沮丧。我们都可以在网上抱怨它们,或者选择忽略它们。但我们坚信,忽视现实是要付出代价的。能够读取非标准文件——即使这可能导致歧义——也应该由用户决定。
运行示例
作为我们的运行示例,我们将使用一个名为 cafes.csv 的 CSV 文件。
ZIP,Name,Country
1014,"Cafe ""Gedoogt""",Netherlands
1015,"Cafe "De Tuin" Amsterdam",Netherlands
1095,Joost
1872,Cafe Gezellig,Netherlands,5
尽管文件很小,但它包含了许多不同的错误。我们来逐行检查它:
| 行 | 行内容 | 注释 |
|---|---|---|
| 1 | ZIP,Name,Country |
文件的头部。 |
| 2 | 1014,"Cafe ""Gedoogt""",Netherlands |
一行定义良好的数据,其中引用值包含转义引号 ("")。 |
| 3 | 1015,"Cafe "De Tuin" Amsterdam",Netherlands |
Name 的值包含未转义的引号。 |
| 4 | 1095,Joost |
这一行缺少 Country 的值。 |
| 5 | 1872,Cafe Gezellig,Netherlands,5 |
包含一个额外列,其值为 5。 |
简单加载示例
如果我们简单地尝试读取示例文件,我们将得到一个只包含一行数据的表格。
FROM read_csv('cafes.csv');
┌─────────┬───────────────┬─────────────┬─────────┐
│ column0 │ column1 │ column2 │ column3 │
│ int64 │ varchar │ varchar │ int64 │
├─────────┼───────────────┼─────────────┼─────────┤
│ 1872 │ Cafe Gezellig │ Netherlands │ 5 │
└─────────┴───────────────┴─────────────┴─────────┘
我们可以看到读取器忽略了除最后一行之外的所有行。让我们查询 CSV 嗅探器,看看它检测到的方言。
SELECT Delimiter, Quote, Escape, SkipRows
FROM sniff_csv('cafes.csv');
┌───────────┬─────────┬─────────┬──────────┐
│ Delimiter │ Quote │ Escape │ SkipRows │
│ varchar │ int16 │ varchar │ uint16 │
├───────────┼─────────┼─────────┼──────────┤
│ , │ \0 │ \0 │ 4 │
└───────────┴─────────┴─────────┴──────────┘
我们可以看到嗅探器认定文件中不存在引号和转义字符(表示为 \0 值)。因此,它决定跳过前 4 行(包括头部),以便根据该方言读取文件。
提示:DuckDB 允许用户使用
reject_errors表检索读取 CSV 文件时发生的所有错误。这超出了本博客文章的范围,但您可以在“读取有缺陷的 CSV 文件”文档页面中找到更多详细信息。
使用用户定义的 CSV 方言加载示例
让我们尝试使用用户定义的 CSV 方言读取这些有缺陷的 CSV 文件。为此,我们将 auto_detect 选项设置为 false,并手动指定 header 的存在、delim(分隔符)、quote 和 escape 选项的值,以及使用 columns 选项指定模式。
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'}
);
运行此 SQL 语句将导致第 3 行因未转义的引号而报错:解析器无法确定 "De Tuin" 中的第一个引号是否标志着引用值的结束。
Invalid Input Error:
CSV Error on Line: 3
Original Line: 1015,"Cafe "De Tuin" Amsterdam",Netherlands
Value with unterminated quote found.
Possible fixes:
* Disable the parser's strict mode (strict_mode=false) to allow reading rows that do not comply with the CSV standard.
* Enable ignore errors (ignore_errors=true) to skip this row
* Set quote to empty or to a different value (e.g., quote='')
错误消息告诉我们,由于未转义的引号字符,存在一个带有未终止引号的值。它还提出了一些可能的修复方法,这将指导我们在接下来的章节中进行尝试。
禁用严格模式
正如错误消息所告知的,放松 DuckDB CSV 读取器约束以读取此文件的方法之一是使用 strict_mode 选项。具体来说,禁用 strict_mode 选项将允许 CSV 读取器处理以下常见错误:
-
未转义的引用值,例如第 3 行中的值。
-
列数过多的行。例如,对于行
1872,Cafe Gezellig,Netherlands,5,为了适应我们三列的模式,最后一列将被忽略。 -
混合使用换行符分隔符,例如,文件中同时包含
\n和\r\n作为换行符分隔符。此错误未在我们的运行示例中出现。
默认情况下,strict_mode 设置为 true,这意味着 DuckDB 不会尝试解析不符合方言的行。但是,将其设置为 false 允许 CSV 读取器尝试读取文件,即使在给定配置下无法正确读取。让我们回到我们的示例,并关闭严格模式。
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'}
);
我们可以看到读取器现在只在第 4 行报错,这表明之前的行都已正确读取。
Invalid Input Error:
CSV Error on Line: 4
Original Line: 1095,Joost
Expected Number of Columns: 3 Found: 2
Possible fixes:
* Enable null padding (null_padding=true) to replace missing values with NULL
* Enable ignore errors (ignore_errors=true) to skip this row
对于
strict_mode = false选项,有两点需要注意:
使用此选项时,不能保证结果是正确的。这是因为在解析非标准 CSV 文件时,无法定义什么是“正确的结果”。
DuckDB 运行的是一个尽力而为的解析器,它只会遇到无法合理猜测正确数据应该是什么样子的错误时才失败(例如,想象一个整数列,其中一些整数表示为拼写出来的字符串,这将导致类型转换错误)。虽然在给定错误组合的情况下,我们的解析器仍可能失败,但我们正在努力使其在面对深渊时更加鲁棒。
忽略错误
错误消息建议的另一个选项是设置 ignore_errors = true。此选项简单地意味着任何不符合所选方言或模式的行都将从结果中跳过。实际上,如果我们将它添加到我们的查询中:
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'},
ignore_errors = true
);
我们得到了一个几乎完整的结果!只缺少第 4 行 1095,Joost,因为它缺少一个列。
┌───────┬────────────────────────┬─────────────┐
│ ZIP │ Name │ Country │
│ int16 │ varchar │ varchar │
├───────┼────────────────────────┼─────────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │
│ 1872 │ Cafe Gezellig │ Netherlands │
└───────┴────────────────────────┴─────────────┘
ignore_errors选项也会影响嗅探器的行为,因为它会忽略在嗅探过程中产生错误的行。一般来说,导致错误最少的配置将被优先选择。
缺失值的空值填充
读取非标准 CSV 文件时,最后一个有用的选项是 null_padding 选项。当 CSV 文件中的行值数量不一致,某些列缺少值时,此选项非常有用。让我们使用 null_padding = true 选项读取文件。
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'},
null_padding = true
);
这将产生以下结果:
┌───────┬────────────────────────┬─────────────┐
│ ZIP │ Name │ Country │
│ int16 │ varchar │ varchar │
├───────┼────────────────────────┼─────────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │
│ 1095 │ Joost │ NULL │
│ 1872 │ Cafe Gezellig │ Netherlands │
└───────┴────────────────────────┴─────────────┘
读取示例文件的最小配置
呼,我们加载了文件,但是 read_csv 调用大约有 200 个字符长!幸运的是,我们可以做得更好:如果我们同时设置 strict_mode = false 和 null_padding = true,我们只需要指定 quote 和 escape 值。这个调用只需要大约 80 个字符,就能从这个 CSV 文件中得到有效的结果。
FROM read_csv('cafes.csv',
strict_mode = false,
null_padding = true,
quote = '"',
escape = '"'
);
┌───────┬────────────────────────┬─────────────┬─────────┐
│ ZIP │ Name │ Country │ column3 │
│ int64 │ varchar │ varchar │ int64 │
├───────┼────────────────────────┼─────────────┼─────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │ NULL │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │ NULL │
│ 1095 │ Joost │ NULL │ NULL │
│ 1872 │ Cafe Gezellig │ Netherlands │ 5 │
└───────┴────────────────────────┴─────────────┴─────────┘
使用此配置,嗅探器实际上会创建一个新列 (column3) 以适应最后一行的额外值。这个例子表明,即使对于存在多个问题的 CSV 文件,DuckDB 的 CSV 嗅探器仍然可以对文件的方言和模式做出相当不错的判断。
提示:您可以通过例如在查询中使用
SELECT #1, #2, #3 FROM ...来删除最后一列。
Pollock 基准测试
Pollock 基准测试是一个 CSV 数据加载基准,旨在评估 CSV 系统在读取非标准 CSV 文件时的鲁棒性。该基准测试在 VLDB 2023 上发布,并且完全开源,其仓库最近添加了 DuckDB 条目。
Pollock 基准测试的作者分析了超过 245,000 个公共 CSV 数据集,以了解 RFC-4180 标准在实际 CSV 文件中最常见的违规方式。在识别出最常见的错误类型后,他们创建了一个带有污染机制的 CSV 文件生成器,该生成器会插入这些错误。总的来说,该基准测试工具生成了超过 2,200 个被污染的文件。它还会生成读取这些文件应使用的正确方言配置,以及文件的干净版本。
为了评估系统的鲁棒性,基准测试工具会使用为给定被测系统设置的配置读取被污染的文件。然后,它使用该系统写入一个包含答案的新文件,并将其与干净版本进行比较。这种比较会产生一个分数,反映系统读取文件的准确性。该基准测试主要产生两种分数:简单分数和加权分数,其中加权分数考虑了该类型错误在现实生活中出现的普遍程度。
在本节中,我们将描述论文中描绘的最常见错误,并分享添加 DuckDB 后的基准测试结果。
常见错误
论文描绘了 CSV 文件中出现的许多常见错误。在本节中,我们将简要讨论一些最常见的错误,但完整概述请参阅论文。
-
行中单元格数量不一致: RFC-4180 要求所有行(包括头部)都具有一致的列数,但许多文件每行包含过多或过少的分隔符。
-
非标准换行序列: RFC-4180 要求文件使用回车符后跟换行符 (
\r\n),但许多文件仅使用换行符、回车符或它们的混合。 -
多行头部: 标准允许一个可选的单行头部,但许多文件有多个头部。
-
引号错误或未转义的单元格: 当引用值中包含未转义的引号时,就会发生此错误。请参阅
file_escape_char_0x00.csv以获取示例。请注意,GitHub 的表格渲染器可以读取此文件的干净版本,但却无法解析它。 -
包含多字节分隔符的文件: 标准要求文件以逗号分隔。尽管单字节分隔符被广泛接受,但多字节分隔符也很常见。
-
包含多个表格的文件: 当一个 CSV 文件在同一文件中存储具有不同模式的多个表格时。
方法论
该基准测试包含了各种正在测试的系统,例如 CSV 解析框架(例如 CleverCSV)、关系数据库系统(例如 PostgreSQL)、电子表格软件(例如 LibreOffice Calc)、数据可视化工具(例如 Dataviz)和数据框库(例如 Pandas)。
该基准测试的一个重要方面是它为每个文件提供了方言和模式。如果没有这些信息,没有嗅探器的系统(例如 PostgreSQL)将无法读取文件。对于每个系统如何利用这些信息,没有特定的规则或区分。例如,Pandas 只部分利用了这些设置。为了将这些差异纳入我们对 DuckDB 的评估中,我们决定添加两种不同的配置:
-
DuckDB(基准测试配置)。在此配置下,配置文件中所有与 DuckDB 相关的选项——例如 CSV 方言和模式——都传递给读取器。此外,我们还设置了上一节中描述的所有选项(即
null_padding = true, strict_mode = false, ignore_errors = true)。这基本上告诉我们,如果用户手动设置了必要的选项,我们可以从这些文件中读取多少数据。 -
DuckDB(仅自动检测)。在此配置下,我们不利用提供自定义配置文件。唯一设置的选项是那些允许读取非标准文件的选项(即
null_padding = true, strict_mode = false, ignore_errors = true)。因此,此选项还评估了我们的嗅探器在不确定情况下的全部能力。
Pollock 分数
下表展示了包含 DuckDB 的结果。我们还将原始表格限制为只显示每个类别中得分最高的系统(例如,解析框架、关系系统等)。对于简单分数和加权分数,设置了所有选项的 DuckDB(Pollock 基准测试的默认配置)都是明显的赢家。就简单分数而言,这意味着 DuckDB 正确读取了所有文件中 99.61% 的数据。它还能正确处理最常见的错误,这反映在加权分数中。
Pollock 分数按加权分数排序(满分 10 分)
| 被测系统 | Pollock 分数(加权) | Pollock 分数(简单) |
|---|---|---|
| DuckDB 1.2(基准测试配置) | 9.599 | 9.961 |
| “SpreadDesktop” | 9.597 | 9.929 |
| Pandas 1.4.3 | 9.431 | 9.895 |
| “SpreadWeb” | 9.431 | 9.721 |
| SQLite 3.39.0 | 9.375 | 9.955 |
| DuckDB 1.2(仅自动检测) | 8.439 | 9.075 |
| UniVocity 2.9.1 | 7.936 | 9.939 |
| LibreOffice Calc 7.3.6 | 7.833 | 9.925 |
| Dataviz | 5.152 | 5.003 |
根据基准测试网站的说法,“SpreadDesktop”是一款桌面商业电子表格软件,“SpreadWeb”是一款基于网络的电子表格软件。它们的真实名称因许可原因被省略。
点击此处查看完整结果表格
| 被测系统 | Pollock 分数(加权) | Pollock 分数(简单) |
|---|---|---|
| DuckDB 1.2(基准测试配置) | 9.599 | 9.961 |
| “SpreadDesktop” | 9.597 | 9.929 |
| CleverCSV 0.7.4 | 9.453 | 9.193 |
| Python 原生 csv 3.10.5 | 9.436 | 9.721 |
| Pandas 1.4.3 | 9.431 | 9.895 |
| “SpreadWeb” | 9.431 | 9.721 |
| SQLite 3.39.0 | 9.375 | 9.955 |
| CSVCommons 1.9.0 | 9.253 | 6.647 |
| DuckDB 1.2(仅自动检测) | 8.439 | 9.075 |
| UniVocity 2.9.1 | 7.936 | 9.939 |
| LibreOffice Calc 7.3.6 | 7.833 | 9.925 |
| OpenCSV 5.6 | 7.746 | 6.632 |
| MySQL 8.0.31 | 7.484 | 9.587 |
| MariaDB 10.9.3 | 7.483 | 9.585 |
| PostgreSQL 15.0 | 6.961 | 0.136 |
| R 原生 csv 4.2.1 | 6.405 | 7.792 |
| Dataviz | 5.152 | 5.003 |
| Hypoparsr 0.1.0 | 4.372 | 3.888 |
正如预期的那样,在完全自动模式下运行 DuckDB 得分较低,因为嗅探器必须自行检测方言和模式。有些文件甚至具有多字节分隔符,尽管 DuckDB 支持,但这不在嗅探器的搜索空间内,因此得分较低。在这些情况下,DuckDB 仍然成功正确读取了大约 90.75% 的数据,总分达到 9.075,总加权分达到 8.439。再次强调,这个结果仅仅通过调用 read_csv('file_path', null_padding = true, strict_mode = false, ignore_errors = true) 获得,用户无需输入任何实际数据配置,这表明 DuckDB 的 CSV 读取器确实可以读取大多数非标准 CSV 文件,即使只进行最小配置!
为基准测试做贡献
您最喜欢的 CSV 读取器系统可能尚未包含在基准测试结果中。例如,DuckDB 最初并未包含在内,但我们发现添加它非常容易!我们希望 DuckDB 拉取请求能为那些希望添加自己喜欢的系统的人提供灵感。结果的复现也非常简单。与大多数专注于性能和正确性的基准测试不同,Pollock 基准测试衡量的是准确性,这使得它易于独立于所使用的机器进行复现。
祝您编程愉快!

