DuckDB 的 CSV Sniffer:自动检测类型和方言

要点:DuckDB 主要关注性能,充分利用现代文件格式的功能。同时,我们也关注灵活的、非性能驱动的格式,如 CSV 文件。为了在读取 CSV 文件时创造一个良好而愉快的体验,DuckDB 实现了一个 CSV sniffer,它可以自动检测 CSV 方言选项、列类型,甚至跳过脏数据。嗅探过程允许用户高效地探索 CSV 文件,而无需提供任何关于文件格式的输入。

用户在存储数据时可以选择许多不同的文件格式。例如,有面向性能的二进制格式,如 Parquet,其中数据以列式格式存储,划分为行组,并进行高度压缩。然而,Parquet 以其刚性而闻名,需要专门的系统来读取和写入这些文件。
另一方面,还有 CSV(逗号分隔值)格式的文件,我喜欢将其称为数据的“伍德斯托克”。CSV 文件具有灵活性的优势;它们被构造为文本文件,允许用户使用任何文本编辑器来操作它们,并且几乎任何数据系统都可以读取并对它们执行查询。
然而,这种灵活性是有代价的。读取 CSV 文件并非易事,因为用户需要大量关于该文件的先验知识。例如,DuckDB 的 CSV 读取器提供了超过 25 个配置选项。我发现,如果我不在每个版本中至少引入三个新选项,人们往往会认为我工作不够努力。开玩笑的。 这些选项包括指定分隔符、引号和转义字符,确定 CSV 文件中的列数,以及识别是否存在标题,同时定义列类型。这会减慢交互式数据探索过程,并使分析新数据集成为一项繁琐且不太令人愉快的任务。
DuckDB 的存在理由之一是易于使用,因此我们不希望用户必须手动摆弄 CSV 文件和输入选项。手动输入应该只保留给 CSV 方言选择相当不寻常的文件(其中方言包括用于创建该文件的分隔符、引号、转义符和换行符的组合),或者用于指定列类型。
自动检测 CSV 选项可能是一个令人生畏的过程。不仅有很多选项需要调查,而且它们的组合很容易导致搜索空间爆炸。对于结构不太好的 CSV 文件来说尤其如此。有些人可能会争辩说 CSV 文件有一个 规范,但事实是,一旦单个系统能够读取有缺陷的文件,“规范”就会发生变化。而且,天啊,在过去的几个月里,我遇到了相当多的半损坏的 CSV 文件,人们希望 DuckDB 读取它们。
DuckDB 实现了一个 多假设 CSV sniffer,它可以自动检测方言、标题、日期/时间格式、列类型,并识别要跳过的脏行。我们的最终目标是自动读取任何类似 CSV 的文件,永不放弃,永不让你失望!所有这些都是在读取 CSV 文件时不会产生大量初始成本的情况下实现的。在最新版本中,默认情况下,sniffer 在读取 CSV 文件时运行。请注意,sniffer 将始终优先考虑用户设置的任何选项(例如,如果用户将 , 设置为分隔符,sniffer 将不会尝试任何其他选项,并将假定用户输入是正确的)。
在这篇博文中,我将解释当前实现的原理,讨论其性能,并提供对未来发展的见解!
DuckDB 的自动检测
解析 CSV 文件的过程如下图所示。它目前由五个不同的阶段组成,将在接下来的章节中详细介绍。
概述示例中使用的 CSV 文件如下
Name, Height, Vegetarian, Birthday
"Pedro", 1.73, False, 30-07-92
... imagine 2048 consistent rows ...
"Mark", 1.72, N/A, 20-09-92
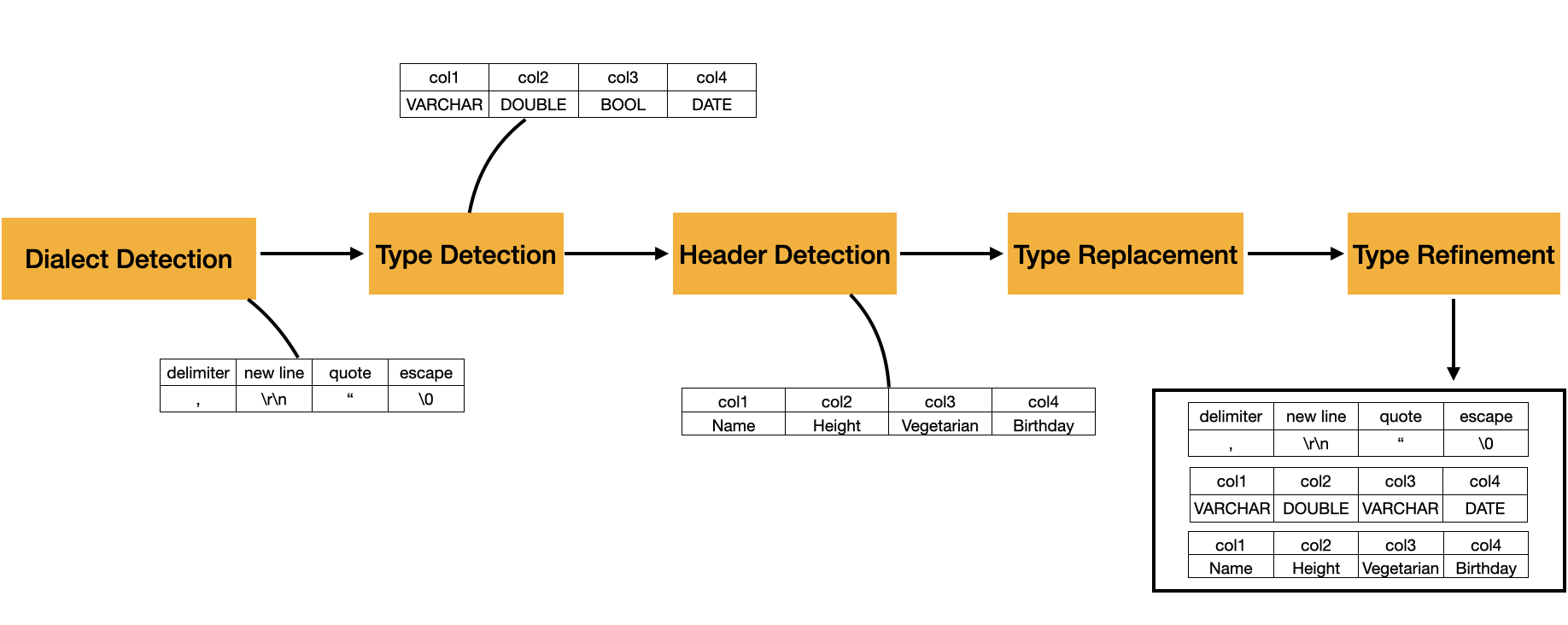
在第一阶段,我们执行方言检测,其中我们选择方言候选者,这些候选者在 CSV 文件中生成最多的每行列,同时保持一致性(即,在整个文件中列数没有显着变化)。在我们的示例中,我们可以观察到,在此阶段之后,sniffer 成功检测到分隔符、引号、转义符和换行分隔符的必要选项。
第二阶段,称为类型检测,涉及识别 CSV 文件中每列的数据类型。在我们的示例中,我们的 sniffer 识别出四种列类型:VARCHAR、DOUBLE、BOOL 和 DATE。
第三步,称为标题检测,用于确定我们的文件是否包含标题。如果存在标题,我们使用它来设置列名;否则,我们自动生成它们。在我们的示例中,存在标题,并且每列都在其中定义了其名称。
现在我们的列有了名称,我们进入第四个可选阶段:类型替换。DuckDB 的 CSV 读取器为用户提供了按名称指定列类型的选项。如果指定了这些类型,我们将检测到的类型替换为用户的规范。
最后,我们进入最后一个阶段,类型细化。在此阶段,我们分析文件的其他部分,以验证在初始类型检测阶段确定的类型的准确性。如有必要,我们对其进行细化。在我们的示例中,我们可以看到 Vegetarian 列最初被归类为 BOOL。然而,经过进一步检查,发现它包含字符串 N/A,导致列类型升级为 VARCHAR 以容纳所有可能的值。
自动检测仅在 CSV 文件的顺序样本上执行。默认情况下,样本的大小为 20,480 个元组(即 10 个 DuckDB 执行块)。这可以通过 sample_size 选项进行配置,如果用户想要嗅探整个文件,可以将其设置为 -1。由于相同的数据会使用各种选项重复读取,并且用户可以扫描整个文件,因此所有在嗅探期间生成的 CSV 缓冲区都会被缓存并有效管理,以确保高性能。
当然,在非常大的文件上运行 CSV Sniffer 会对整体性能产生巨大的影响(请参阅下面的 变化抽样大小 基准测试部分)。在这些情况下,样本大小应保持在合理的水平。
在接下来的小节中,我将详细描述每个阶段。
方言检测
在方言检测中,我们识别 CSV 文件的分隔符、引号、转义符和换行分隔符。
我们的分隔符搜索空间包括以下分隔符:,、|、;、\t。如果文件具有搜索空间之外的分隔符,则必须由用户提供(例如,delim='?')。我们的引号搜索空间是 "、' 和 \0,其中 \0 是一个字符串终止符,表示不存在引号;同样,用户可以提供搜索空间之外的自定义字符(例如,quote='?')。转义值的搜索空间取决于引号选项的值,但总而言之,它们与引号相同,并添加了 \,并且可以再次由用户提供(escape='?')。最后,检测到的最后一个选项是换行分隔符;它们可以是 \r、\n、\r\n,以及所有内容的混合(相信我,我见过一个真实的 CSV 文件,它使用了混合)。
默认情况下,方言检测在 24 种不同的方言配置组合上运行。为了确定最有希望的配置,我们计算每个 CSV 元组在每种配置下将产生的列数。将选择产生最多列且行最一致的配置。
一致行的计算取决于其他用户定义的选项。例如,null_padding 选项将使用 NULL 值填充缺少的列。因此,缺少列的行将使用 NULL 填充缺少的列。
如果 null_padding 设置为 true,则仍将考虑具有不一致行的 CSV 文件,但会优先考虑最小化填充行发生的配置。如果 null_padding 设置为 false,则方言检测器将在 CSV 文件开头跳过不一致的行。例如,考虑以下 CSV 文件。
I like my csv files to have notes to make dialect detection harder
I also like commas like this one : ,
A,B,C
1,2,3
4,5,6
在这里,sniffer 会检测到,如果将分隔符设置为 ,,则第一行有一列,第二行有两列,但其余行有 3 列。因此,如果 null_padding 设置为 false,它仍然会选择 , 作为分隔符候选者,通过假设顶部的行是脏数据。(相信我,CSV 注释是一回事!)。从而产生下表
A,B,C
1, 2, 3
4, 5, 6
如果 null_padding 设置为 true,则所有行都将被接受,从而产生下表
'I like my csv files to have notes to make dialect detection harder', None, None
'I also like commas like this one : ', None, None
'A', 'B', 'C'
'1', '2', '3'
'4', '5', '6'
如果设置了 ignore_errors 选项,则将选择产生最多列且不一致行最少的配置。
类型检测
在确定要使用的方言之后,我们检测每列的类型。我们的类型检测考虑以下类型:SQLNULL、BOOLEAN、BIGINT、DOUBLE、TIME、DATE、TIMESTAMP、VARCHAR。这些类型按特异性排序,这意味着我们首先检查一列是否为 SQLNULL;如果不是,它是否为 BOOLEAN,依此类推,直到它只能是 VARCHAR。DuckDB 具有比默认使用的类型更多的类型。用户还可以通过 auto_type_candidates 选项定义 sniffer 应考虑的类型。
在此阶段,类型检测算法遍历第一个数据块(即 2048 个元组)。此过程从文件的第二个有效行(即非注释)开始。第一行单独存储,不用于类型检测。稍后将检测第一行是否为标题。类型检测运行每列、每值的转换试验过程,以确定列类型。它从一个唯一的、每列的数组开始,其中包含要检查的所有类型。它尝试将列的值转换为该类型;如果失败,它会从数组中删除该类型,尝试使用新类型进行转换,并继续该过程,直到整个块完成。
在此阶段,我们还确定 DATE 和 TIMESTAMP 列的格式。以下格式被认为是 DATE 列的格式
%m-%d-%Y%m-%d-%y%d-%m-Y%d-%m-%y%Y-%m-%d%y-%m-%d
以下被认为是 TIMESTAMP 列的格式
%Y-%m-%dT%H:%M:%S.%f%Y-%m-%d %H:%M:%S.%f%m-%d-%Y %I:%M:%S %p%m-%d-%y %I:%M:%S %p%d-%m-%Y %H:%M:%S%d-%m-%y %H:%M:%S%Y-%m-%d %H:%M:%S%y-%m-%d %H:%M:%S
对于使用此搜索空间之外的格式的列,必须使用 dateformat 和 timestampformat 选项定义它们。
例如,让我们考虑以下 CSV 文件。
Name, Age
,
Jack Black, 54
Kyle Gass, 63.2
第一行 [Name, Age] 将单独存储,用于标题检测阶段。第二行 [NULL, NULL] 将允许我们将第一列和第二列转换为 SQLNULL。因此,它们的类型候选数组将相同:[SQLNULL, BOOLEAN, BIGINT, DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR]。
在第三行 [Jack Black, 54] 中,事情变得更有趣了。对于“Jack Black”,列 0 的类型候选数组将排除所有具有更高特异性的值,因为“Jack Black”只能转换为 VARCHAR。第二列不能转换为 SQLNULL 或 BOOLEAN,但它将成功转换为 BIGINT。因此,第二列的类型候选者将是 [BIGINT, DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR]。
在第四行中,我们有 [Kyle Gass, 63.2]。对于第一列,没有问题,因为它也是一个有效的 VARCHAR。然而,对于第二列,转换为 BIGINT 将失败,但转换为 DOUBLE 将成功。因此,第二列的新候选类型数组将是 [DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR]。
标题检测
标题检测阶段只是获取 CSV 文件的第一行有效行,并尝试将其转换为我们列中的候选类型。如果存在转换不匹配,我们将该行视为标题;如果没有,我们将第一行视为实际数据,并自动生成标题。
在我们之前的示例中,第一行是 [Name, Age],并且列候选类型数组是 [VARCHAR] 和 [DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR]。Name 是一个字符串,可以转换为 VARCHAR。Age 也是一个字符串,尝试将其转换为 DOUBLE 将失败。由于转换失败,自动检测算法将第一行视为标题,导致第一列命名为 Name,第二列命名为 Age。
如果未检测到标题,则将使用模式 column${x} 自动生成列名,其中 x 表示列在 CSV 文件中的位置(基于 0 的索引)。
类型替换
现在自动检测算法已经发现了标题名称,如果用户指定了列类型,则 sniffer 检测到的类型将在类型替换阶段中被替换为这些类型。例如,我们可以使用以下代码将 Age 类型替换为 FLOAT
SELECT *
FROM read_csv('greatest_band_in_the_world.csv', types = {'Age': 'FLOAT'});
此阶段是可选的,仅当存在手动定义的类型时才会触发。
类型细化
类型细化阶段执行与类型检测相同的任务;唯一的区别是转换运算符工作的数据的粒度,出于性能原因对其进行了调整。在类型检测期间,我们对每列、每值执行转换检查。
在此阶段,我们过渡到更高效的矢量化转换算法。验证过程与类型检测中的验证过程相同,如果转换失败,则消除类型候选数组中的类型。
嗅探有多快?
为了分析运行 DuckDB 自动检测的影响,我们在 纽约市出租车数据集 上执行 sniffer。该文件包含 19 列,10,906,858 个元组,大小为 1.72 GB。
嗅探方言列名称和类型的成本约占加载数据总成本的 4%。
| 名称 | 时间 (秒) |
|---|---|
| 嗅探 | 0.11 |
| 加载 | 2.43 |
变化抽样大小
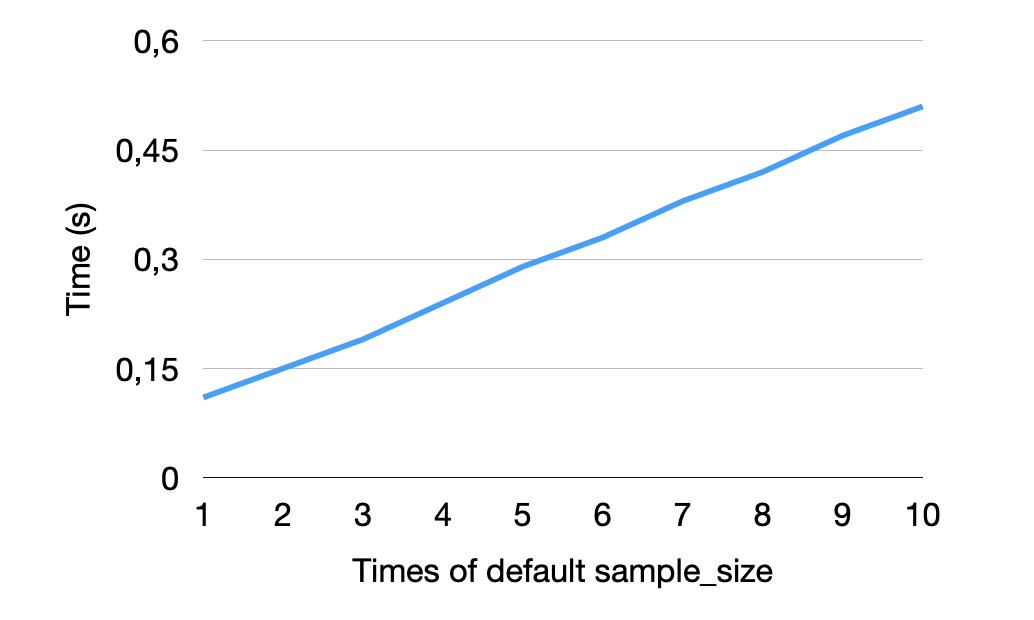
有时,CSV 文件可能具有仅在 CSV 文件后面出现的方言选项或更精细的类型。在这些情况下,sample_size 选项成为用户确保 sniffer 检查足够的数据以做出正确决策的重要工具。然而,增加 sample_size 也会导致 sniffer 的总运行时间增加,因为它使用更多的数据来检测所有可能的方言和类型。
在下面,您可以看到将默认样本大小增加倍数(参见 X 轴)如何影响 sniffer 在纽约市数据集上的运行时间。正如预期的那样,花费在嗅探上的总时间随着总样本大小线性增加。
变化的列数
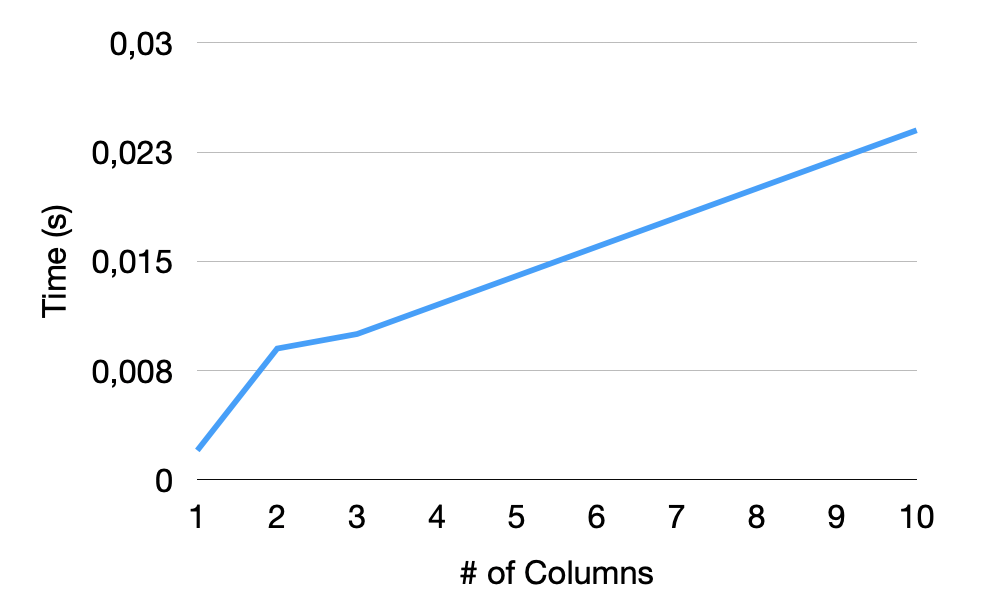
影响自动检测的 CSV 文件的另一个主要特征是文件具有的列数。在这里,我们针对具有 10,906,858 个元组的文件中不同数量的 INTEGER 类型列测试 sniffer。结果如下图所示。我们可以看到,从一列到两列,我们的运行时间增加得更快。那是因为,对于单列,由于缺少分隔符,我们简化了方言检测。对于其他列,正如预期的那样,我们的运行时间增加得更加线性,具体取决于列数。
结论与未来工作
如果您有不寻常的 CSV 文件并想要查询、清理或规范化它们,DuckDB 已经是可用的顶级解决方案之一。它非常容易上手。要使用 sniffer 读取 CSV 文件,您可以简单地
SELECT *
FROM 'path/to/csv_file.csv';
DuckDB 的 CSV 自动检测算法是促进 CSV 文件探索的重要工具。使用其默认选项,它对加载和读取 CSV 文件的总成本影响很小。它的主要目标是始终能够读取文件,即使在定义不明确的文件上也能尽最大努力。
我们有一个与 sniffer 相关的要点列表,我们希望在将来改进。
- 高级标题检测。 我们目前通过识别 CSV 文件的第一行有效行与其余部分之间的类型不匹配来确定 CSV 是否具有标题。但是,例如,如果 CSV 的所有列都是
VARCHAR类型,则这可能会产生误报。我们计划增强我们的标题检测,以执行与常用标题名称的匹配。 - 添加准确性和速度基准。 我们目前实现了许多准确性和回归测试;然而,由于 CSV 固有的灵活性,手动创建测试用例非常令人生畏。未来的计划是使用 Pollock 基准 实施整个准确性和回归测试套件
- 改进的抽样。 我们目前在顺序数据样本上执行自动检测算法。然而,通常情况下,新设置仅在文件稍后才引入(例如,引号可能仅在文件的最后 10% 中使用)。因此,能够 distinct 文件中执行 sniffer 可以提高准确性。
- 多表 CSV 文件。 同一个 CSV 文件中可能存在多个表,这是将电子表格导出到 CSV 时的常见情况。因此,我们希望能够识别并支持这些。
- 空字符串检测。 我们目前没有算法来识别空字符串的表示形式。
- 十进制精度检测。 我们尚未自动检测十进制精度。这是我们将来要解决的问题。
- 并行化。 尽管 DuckDB 的 CSV 读取器已完全并行化,但 sniffer 仍然仅限于单个线程。以类似于 CSV 读取器的方式(描述将在以后的博文中提供)对其进行并行化将显着提高嗅探性能并启用全文件嗅探。
- Sniffer 作为独立函数。 目前,用户可以利用
DESCRIBE查询从 sniffer 获取信息,但它仅返回列名和类型。我们的目标是将嗅探算法公开为独立函数,该函数提供来自 sniffer 的完整结果。这将允许用户轻松地使用完全相同的选项配置文件,而无需重新运行 sniffer。

