提升CSV性能:使用NYC出租车数据集对DuckDB进行基准测试

TL;DR: DuckDB 的基准测试套件现在包含了 NYC 出租车基准测试。我们解释了我们的 CSV 阅读器在出租车数据集上的表现,并提供了重现该基准测试的步骤。
NYC 出租车数据集是纽约市多年出租车行程的集合。这是一个非常有影响力的数据集,用于数据库基准测试、机器学习、数据可视化等。
2022年,数据提供商决定将数据集作为一系列 Parquet 文件而非 CSV 文件进行分发。从性能角度来看,这是一个明智的选择,因为 Parquet 文件比 CSV 文件小得多,并且其原生的列式格式允许直接在其上快速执行。然而,这一改变阻碍了能够原生加载这些文件的系统数量。
在“Redshift 中的十亿次出租车行程”博客文章中,提出了一种新的数据库基准测试,用于评估出租车数据集上聚合操作的性能。该数据集还与其他包含天气、出租车类型以及上车/下车位置信息的数据集进行连接和反范式化。然后,它以多个压缩的 gzipped CSV 文件形式存储,每个文件包含 2000 万行。
以CSV文件形式的出租车数据集
由于 DuckDB 以其CSV 阅读器性能而闻名,我们很想探索此基准测试的加载过程是否能帮助我们识别 CSV 加载器中的新性能瓶颈。这种好奇心促使我们着手生成这些数据集并分析它们在 DuckDB 中的性能。根据最近对 AWS RedShift 集群进行的研究,CSV 文件是 S3 中最常用的外部源数据类型,其中 99% 经过 gzip 压缩。因此,提议的基准测试也使用了分块的 gzip 压缩文件这一事实引起了我的注意。
在这篇博客文章中,我们将指导您如何在 DuckDB 中运行此基准测试,并讨论一些经验教训以及我们 CSV 阅读器未来的改进方向。本基准测试中使用的数据集是公开可用的。该数据集被分区并以 65 个 gzip 压缩的 CSV 文件集合形式分发,每个文件包含 2000 万行,每个文件总计高达 1.8 GB。整个数据集压缩后为 111 GB,未压缩时为 518 GB。我们还提供了关于如何生成此数据集的更多详细信息,并强调了我们分发的数据集与“Redshift 中的十亿次出租车行程”博客文章中描述的原始数据集之间的差异。
重现基准测试
进行公平的基准测试是一个难题,特别是当用于基准测试的数据、查询和结果不易访问和运行时。我们通过在taxi-benchmark GitHub 仓库中提供脚本,使得本文讨论的基准测试易于运行。
此仓库包含三个主要的 Python 脚本
generate_prepare_data.py:下载所有必要文件并为基准测试做准备。benchmark.py:运行基准测试并执行结果验证。analyse.py:分析基准测试结果并生成本文讨论的一些见解。
该基准测试并非旨在完美无缺——没有任何基准测试是完美的。然而,我们认为分享这些脚本是积极的一步,并且我们欢迎任何贡献,以使其更简洁和高效。
该仓库还包含一个 README 文件,其中详细说明了如何使用它。该仓库将作为本博客文章中进行实验的基础。
准备数据集
首先,您需要通过执行python generate_prepare_data.py来下载并准备文件。这会将所有 65 个文件下载到./data文件夹中。此外,文件将被解压缩并合并成一个大的单一文件。
因此,./data文件夹将包含 65 个 gzip 压缩的 CSV 文件(即从trips_xaa.csv.gz到trips_xcm.csv.gz)以及一个包含完整数据的单个大型未压缩 CSV 文件(即decompressed.csv)。
我们的基准测试在两种不同的设置下运行:
- 针对 65 个压缩文件。
- 针对单个未压缩文件。
文件准备好后,您可以通过运行python benchmark.py来运行基准测试。
加载
基准测试的加载阶段针对每种基准设置运行六次。我们取前五次运行的加载时间中位数。在第六次运行期间,我们收集资源使用数据(例如,CPU 使用率和磁盘读写)。
加载使用内存中的 DuckDB 实例执行,这意味着数据不会持久化到 DuckDB 存储中,并且仅在连接活动时存在。这一点很重要,因为数据集不适合内存,会被溢出到磁盘上的临时空间。不持久化数据的决定对性能有重大影响:它使得数据集加载速度显著加快,而查询速度会因为 DuckDB 使用未压缩表示而有所减慢。我们为基准测试做出此选择,因为我们的主要关注点是测试 CSV 加载器,而不是查询。
我们的表模式在schema.sql中定义。
schema.sql.
CREATE TABLE trips (
trip_id BIGINT,
vendor_id VARCHAR,
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR,
rate_code_id BIGINT,
pickup_longitude DOUBLE,
pickup_latitude DOUBLE,
dropoff_longitude DOUBLE,
dropoff_latitude DOUBLE,
passenger_count BIGINT,
trip_distance DOUBLE,
fare_amount DOUBLE,
extra DOUBLE,
mta_tax DOUBLE,
tip_amount DOUBLE,
tolls_amount DOUBLE,
ehail_fee DOUBLE,
improvement_surcharge DOUBLE,
total_amount DOUBLE,
payment_type VARCHAR,
trip_type VARCHAR,
pickup VARCHAR,
dropoff VARCHAR,
cab_type VARCHAR,
precipitation BIGINT,
snow_depth BIGINT,
snowfall BIGINT,
max_temperature BIGINT,
min_temperature BIGINT,
average_wind_speed BIGINT,
pickup_nyct2010_gid BIGINT,
pickup_ctlabel VARCHAR,
pickup_borocode BIGINT,
pickup_boroname VARCHAR,
pickup_ct2010 VARCHAR,
pickup_boroct2010 BIGINT,
pickup_cdeligibil VARCHAR,
pickup_ntacode VARCHAR,
pickup_ntaname VARCHAR,
pickup_puma VARCHAR,
dropoff_nyct2010_gid BIGINT,
dropoff_ctlabel VARCHAR,
dropoff_borocode BIGINT,
dropoff_boroname VARCHAR,
dropoff_ct2010 VARCHAR,
dropoff_boroct2010 BIGINT,
dropoff_cdeligibil VARCHAR,
dropoff_ntacode VARCHAR,
dropoff_ntaname VARCHAR,
dropoff_puma VARCHAR);
65 个文件的加载器使用以下查询:
COPY trips FROM 'data/trips_*.csv.gz' (HEADER false);
单个未压缩文件的加载器使用此查询:
COPY trips FROM 'data/decompressed.csv' (HEADER false);
查询
加载完成后,基准测试脚本将运行每个基准查询五次,以测量它们的执行时间。还需要注意的是,查询结果会根据其对应的答案进行验证。这使我们能够验证基准测试的正确性。此外,这些查询与原始“十亿次出租车行程”基准测试中使用的查询完全相同。
结果
加载时间
尽管我们谈论的是一个包含 51 列的 CSV 文件的许多行,但 DuckDB 可以相当快地摄取它们。
请注意,默认情况下,DuckDB 会保留数据的插入顺序,这会对性能产生负面影响。在以下结果中,所有数据集都已加载,并将此选项设置为false。
SET preserve_insertion_order = false;
所有实验均在我的 Apple M1 Max(64 GB RAM)上运行,我们比较了单个未压缩 CSV 文件和 65 个压缩 CSV 文件的加载时间。
| 名称 | 时间 (分钟) | CPU 使用率与 100% 的平均偏差 |
|---|---|---|
| 单文件 – 未压缩 | 11:52 | 31.57 |
| 多文件 – 已压缩 | 13:52 | 27.13 |
毫不奇怪,从多个压缩文件加载数据比从单个未压缩文件加载更具 CPU 效率。这从多个压缩文件的 CPU 使用率平均偏差较低可以看出,这表明浪费的 CPU 周期更少。这主要有两个原因:(1) 压缩文件比未压缩文件小大约八倍,大大减少了需要从磁盘加载的数据量,从而最大程度地减少了等待数据处理时 CPU 的停顿。(2) 并行加载多个文件比加载单个文件容易得多,因为每个线程都可以处理一个文件。
CPU 效率的差异也反映在执行时间上:从单个未压缩文件读取比从多个压缩文件读取快 2 分钟。造成这种情况的原因在于我们的解压缩算法,它确实没有经过优化设计。读取压缩文件涉及三个任务:(1) 将数据从磁盘加载到压缩缓冲区,(2) 将该数据解压缩到解压缩缓冲区,以及 (3) 处理解压缩缓冲区。在我们当前的实现中,任务 1 和 2 合并为一个操作,这意味着在当前缓冲区完全解压缩之前,我们无法继续读取,从而导致空闲周期。
幕后原理
我们还可以查看内部情况,以验证我们关于加载时间的结论。
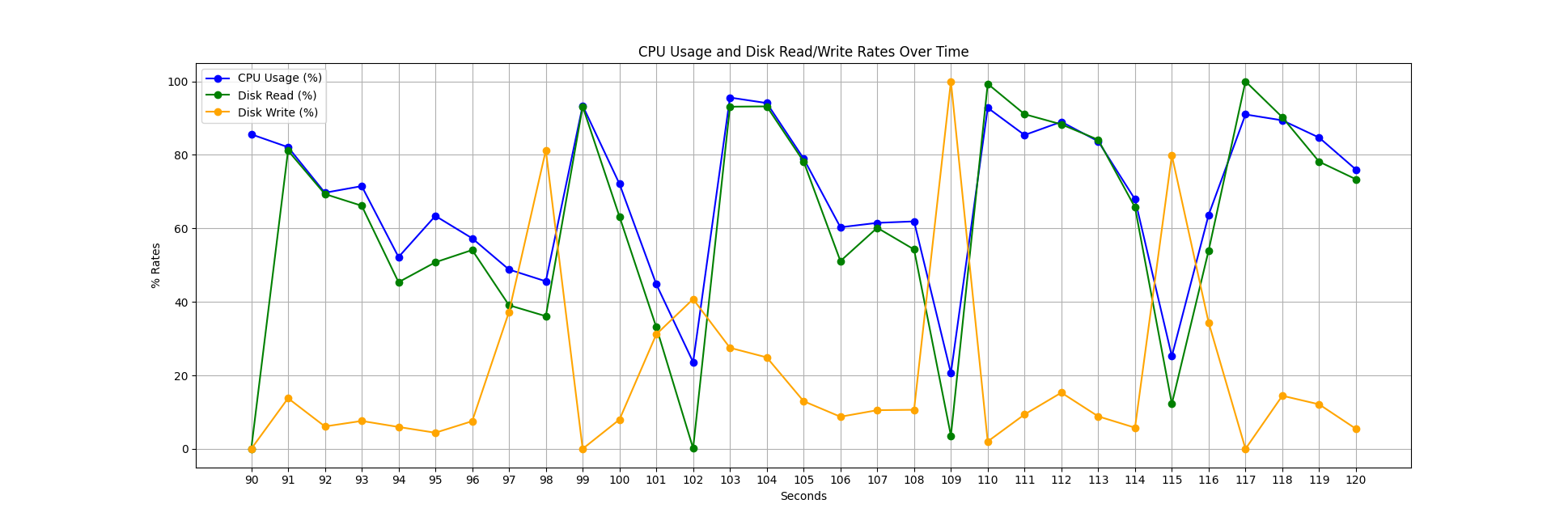
在下图中,您可以看到“单文件 – 未压缩”运行的 CPU 和磁盘利用率快照。我们观察到实现 100% CPU 利用率具有挑战性,并且由于数据写入磁盘,我们经常遇到停顿,因为我们正在从不适合我们内存的数据集中创建表。另一个关键点是 CPU 利用率与磁盘读取密切相关,表明我们的线程在处理数据之前经常等待数据。为 CSV 阅读器/写入器实现异步 I/O 可以显著提高并行处理的性能,因为单个线程可以处理我们大部分的磁盘 I/O,而不会对 CPU 利用率产生负面影响。
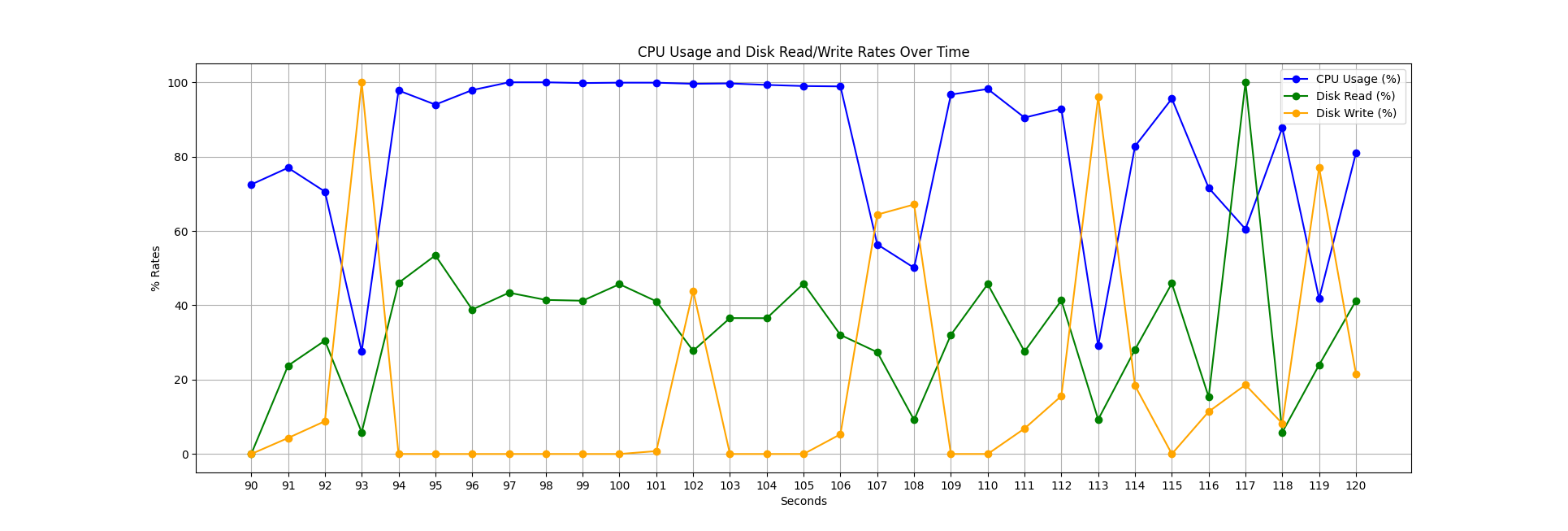
下面,您可以看到加载 65 个压缩文件的类似快照。我们通过数据写入经常遇到停顿;然而,CPU 利用率明显更好,因为我们等待数据加载的时间更少(请记住,数据大约比未压缩情况下小 8 倍)。在这种情况下,并行化也容易得多。与未压缩情况类似,通过异步 I/O 以及分解的解压缩算法,可以缓解 CPU 利用率的这些空白。
查询时间
为了完整性,我们还提供了在配备 M1 Pro CPU 的 MacBook Pro 上运行四个查询的结果。此比较展示了在内存不足的数据库上,使用纯内存连接(即不带存储)进行查询与数据首先加载并持久化到数据库中的查询之间的时间差异。
| 名称 | 时间 – 无存储 (秒) | 时间 – 有存储 (秒) |
|---|---|---|
| 查询 01 | 2.45 | 1.45 |
| 查询 02 | 3.89 | 0.80 |
| 查询 03 | 5.21 | 2.20 |
| 查询 04 | 11.2 | 3.12 |
这些时间之间的主要区别在于,当 DuckDB 使用存储文件时,数据会高度压缩,从而在查询数据集时实现更快的访问。相反,当我们不使用持久存储时,我们的内存数据库会将数据临时存储在未压缩的.tmp文件中,以允许内存溢出,这会增加磁盘 I/O 并导致查询结果变慢。这一观察提出了一个潜在的探索领域:确定对临时数据应用压缩是否会有益。
该数据集是如何生成的
原始博客文章使用 NYC 出租车和豪华轿车委员会分发的 CSV 文件生成数据集。最初,这些文件包含精确的上车和下车经纬度坐标。然而,从 2016 年年中开始,为了解决隐私问题,这些精确坐标通过上车和下车几何对象进行了匿名化。(甚至有故事讲述因检查出租车的实际目的地而导致婚姻破裂。) 此外,近年来,TLC 决定将数据重新分发为 Parquet 文件,并完全匿名化这些数据点,包括 2016 年年中之前的数据。
这是一个问题,因为“Redshift 中的十亿次出租车行程”博客文章中的数据集依赖于这些详细信息。让我们来看一下以下数据片段:
649084905,VTS,2012-08-31 22:00:00,2012-08-31 22:07:00,0,1,-73.993908,40.741383000000006,-73.989915,40.75273800000001,1,1.32,6.1,0.5,0.5,0,0,0,0,7.1,CSH,0,0101000020E6100000E6CE4C309C7F52C0BA675DA3E55E4440,0101000020E610000078B471C45A7F52C06D3A02B859604440,yellow,0.00,0.0,0.0,91,69,4.70,142,54,1,Manhattan,005400,1005400,I,MN13,Hudson Yards-Chelsea-Flatiron-Union Square,3807,132,109,1,Manhattan,010900,1010900,I,MN17,Midtown-Midtown South,3807
我们看到精确的经纬度数据点:-73.993908, 40.741383000000006, -73.989915, 40.75273800000001,以及由此经纬度信息创建的 PostGIS 几何六进制大对象:0101000020E6100000E6CE4C309C7F52C0BA675DA3E55E4440, 0101000020E610000078B471C45A7F52C06D3A02B859604440(生成方式为ST_SetSRID(ST_Point(longitude, latitude), 4326))。
由于此信息对数据集至关重要,因此由于缺少详细的位置数据,无法再按照“Redshift 中的十亿次出租车行程”博客文章中描述的方式生成文件。然而,互联网从不遗忘。因此,我们找到了由各种来源分发的原始数据集实例,例如[1]、[2]和[3]。利用这些来源,我们将原始 CSV 文件与“Redshift 中的十亿次出租车行程”博客文章中引用的脚本中的天气信息结合起来。
该数据集与原始数据集有何不同?
我们分发的数据集与“Redshift 中的十亿次出租车行程”博客文章中的数据集之间存在两个显著差异:
- 我们的数据集包含截至经纬度信息可用日期(2016 年 6 月 30 日)的所有数据,而原始文章只包含截至 2015 年底的数据(可以理解,因为该文章写于 2016 年 2 月)。
- 我们还包含了 Uber 行程,这在原始文章中是被排除的。
如果您希望使用尽可能接近原始数据集的数据集来运行基准测试,您可以通过筛选掉额外数据来生成一个新表。例如:
CREATE TABLE trips_og AS
FROM trips
WHERE pickup_datetime < '2016-01-01'
AND cab_type != 'uber';
结论
在这篇博客文章中,我们讨论了如何在 DuckDB 上运行出租车基准测试,并且我们已经提供了所有脚本,以便您也可以对您偏好的系统进行基准测试。我们还展示了如何使用这个高度相关的基准测试来评估我们的运算符,并深入了解需要进一步改进的领域。

