DuckDB 中的轻量级压缩

TL;DR: DuckDB 支持高效的轻量级压缩,该压缩会自动使用以减小数据大小,而不会产生高昂的压缩和解压缩成本。

处理大量数据时,压缩对于减少存储大小和出站成本至关重要。压缩算法通常能将数据集大小减少 75-95%,具体取决于数据的可压缩性。压缩不仅能减少数据集的存储占用空间,通常还能 提高性能,因为需要从磁盘或通过网络连接读取的数据更少。
列式存储格式,如 DuckDB 的原生文件格式或 Parquet,尤其受益于压缩。这是因为单个列内的数据通常非常相似,可以被压缩算法有效地利用。以行式格式存储数据会导致不同列的数据交错,从而降低压缩率。
DuckDB 在去年年底添加了对压缩的支持。如下表所示,DuckDB 的压缩比自那时以来持续改进,并且仍在积极改进中。在这篇博客文章中,我们将讨论 DuckDB 中的压缩工作原理,以及我们在为 DuckDB 存储格式实现压缩时所做的设计选择和各种权衡。
| 版本 | 出租车 | 准时 | 行项目 |
备注 | 日期 |
|---|---|---|---|---|---|
| DuckDB v0.2.8 | 15.3 GB | 1.73 GB | 0.85 GB | 未压缩 | 2021 年 7 月 |
| DuckDB v0.2.9 | 11.2 GB | 1.25 GB | 0.79 GB | RLE + 常量 | 2021 年 9 月 |
| DuckDB v0.3.2 | 10.8 GB | 0.98 GB | 0.56 GB | 位打包 | 2022 年 2 月 |
| DuckDB v0.3.3 | 6.9 GB | 0.23 GB | 0.32 GB | 字典 | 2022 年 4 月 |
| DuckDB v0.5.0 | 6.6 GB | 0.21 GB | 0.29 GB | FOR | 2022 年 9 月 |
| DuckDB 开发版 | 4.8 GB | 0.21 GB | 0.17 GB | FSST + Chimp | 现在 |
| CSV | 17.0 GB | 1.11 GB | 0.72 GB | ||
| Parquet (未压缩) | 4.5 GB | 0.12 GB | 0.31 GB | ||
| Parquet (Snappy) | 3.2 GB | 0.11 GB | 0.18 GB | ||
| Parquet (ZSTD) | 2.6 GB | 0.08 GB | 0.15 GB |
压缩简介
从核心来看,压缩算法试图在数据集中找到模式,以便更巧妙地存储它。因此,数据集的 可压缩性 取决于是否可以找到这些模式,以及它们是否首先存在。遵循固定模式的数据可以显著压缩。没有模式的数据,例如随机噪声,则无法压缩。正式地,数据集的可压缩性被称为其熵。
作为这个概念的例子,让我们考虑以下两个数据集。
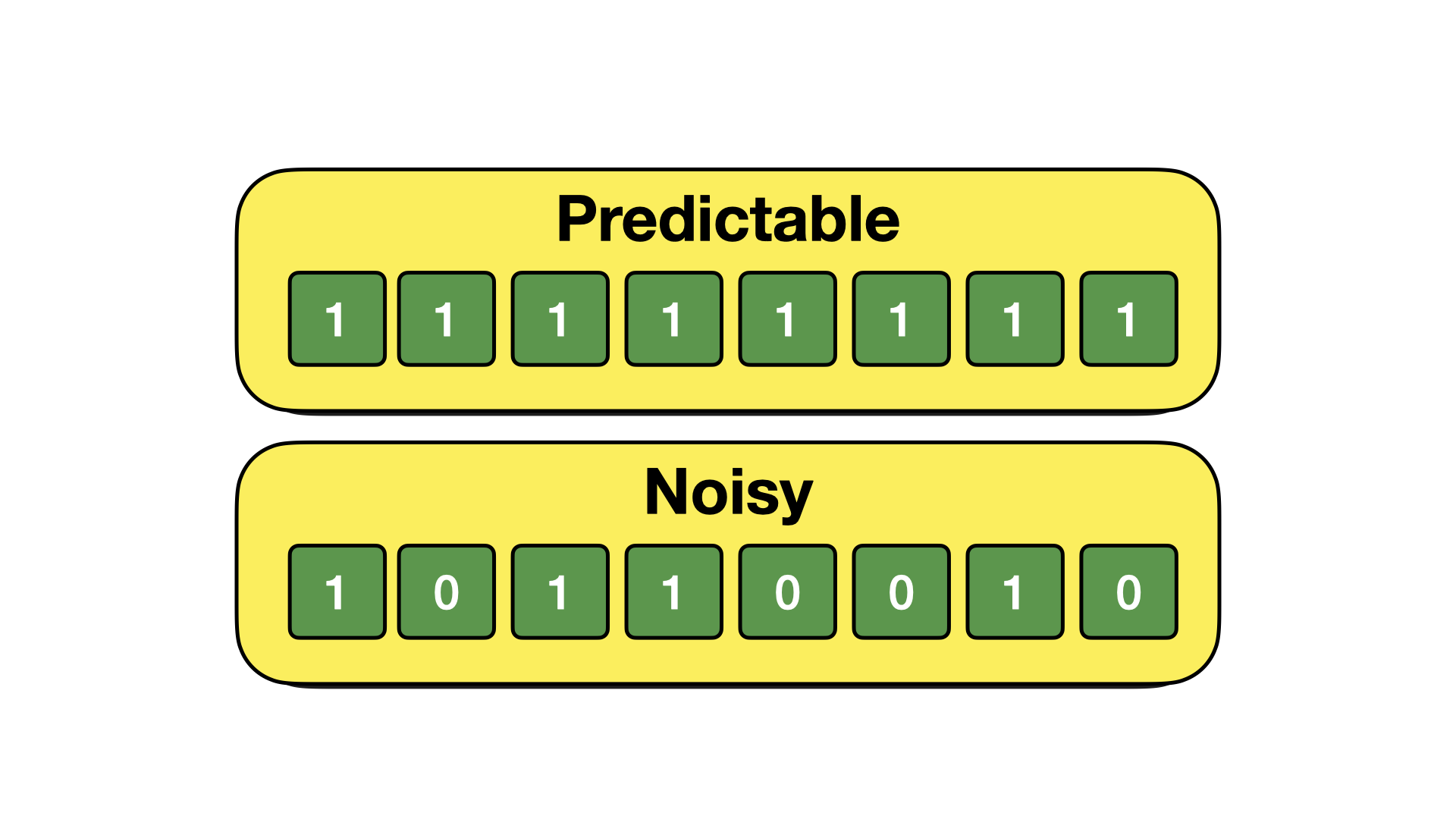
常量数据集可以通过简单地存储模式的值和模式重复的次数(例如,1x8)来压缩。另一方面,随机噪声没有模式,因此不可压缩。
通用压缩算法
大多数人熟悉的压缩算法是通用压缩算法,例如 zip、gzip 或 zstd。通用压缩算法通过查找比特中的模式来工作。因此,它们与数据类型无关,可以用于任何比特流。它们可以用于压缩文件,也可以应用于通过套接字连接发送的任意数据。
通用压缩灵活且易于设置。有许多高质量的库可用(如 zstd、snappy 或 lz4),它们提供压缩功能,并且可以应用于以任何方式存储的任何数据集。
通用压缩的缺点是(解)压缩通常成本很高。虽然我们在从硬盘或通过慢速互联网连接进行读写时这并不重要,但当数据存储在 RAM 中时,(解)压缩的速度可能成为瓶颈。
另一个缺点是这些库作为黑盒操作。它们在比特流上操作,不向用户透露其内部状态的信息。虽然如果您只是想减小数据大小,这不是问题,但它阻止了系统在执行过程中利用压缩算法发现的模式。
最后,通用压缩算法在压缩大数据块时效果更好。如下表所示,当压缩少量数据时,压缩率会显著降低。为了获得良好的压缩率,必须使用至少 256 kB 的块。
| 压缩 | 1 kB | 4 kB | 16 kB | 64 kB | 256 kB | 1 MB |
|---|---|---|---|---|---|---|
| zstd | 1.72 | 2.1 | 2.21 | 2.41 | 2.54 | 2.73 |
| lz4 | 1.29 | 1.5 | 1.52 | 1.58 | 1.62 | 1.64 |
| gzip | 1.7 | 2.13 | 2.28 | 2.49 | 2.62 | 2.67 |
这很重要,因为块大小是从磁盘读取单行时必须解压缩的最小数据量。更糟的是,由于 DuckDB 是按列压缩数据,块大小将是每列必须解压缩的最小数据量。块大小为 256 kB 时,获取单行可能需要解压缩数兆字节的数据。这可能导致获取少量行的查询(例如 SELECT * FROM tbl LIMIT 5 或 SELECT * FROM tbl WHERE id = 42)产生显著成本,尽管表面上看起来非常廉价。
轻量级压缩算法
实现压缩的另一个选择是使用专门的轻量级压缩算法。这些算法也通过查找数据中的模式来工作。然而,与通用压缩不同,它们不试图在比特流中找到通用模式。相反,它们通过在数据集中查找 特定模式 来操作。
通过检测特定模式,专门的压缩算法可以显著更轻量级,提供更快的压缩和解压缩速度。此外,它们可以在更小的数据量上有效工作。这允许我们一次解压缩几行,而不是需要一次解压缩大量数据块。这些专门的压缩算法还可以提供对随机查找的有效支持,从而显著加快通过索引进行的数据访问。
轻量级压缩算法还为我们提供了对压缩过程更精细的控制。这尤其与我们相关,因为 DuckDB 的文件格式使用固定大小的块,以避免涉及删除和更新的工作负载的碎片化。精细控制允许我们更有效地填充这些块,并避免猜测多少压缩数据将适合缓冲区。
另一方面,如果数据中没有出现它们设计的特定模式,这些算法就会失效。因此,单独来看,这些轻量级压缩算法不能替代通用算法。相反,必须结合多个专用算法,以捕获数据集中许多不同的常见模式。
压缩框架
由于上述优点,DuckDB 只使用专门的轻量级压缩算法。由于这些算法在数据的不同模式下都能最佳地工作,DuckDB 的压缩框架必须首先决定使用哪种算法来存储每列的数据。
DuckDB 的存储将表分割成行组(Row Groups)。这些是包含 120K 行的组,以称为列段(Column Segments)的列式块存储。这种存储布局类似于 Parquet – 但有一个重要的区别:列被分割成固定大小的块。做出此设计决策是因为 DuckDB 的存储格式支持对存储格式进行原地 ACID 修改,包括删除和更新行,以及添加和删除列。通过将数据划分为固定大小的块,这些块在不再需要时可以轻松重复使用,从而避免碎片化。
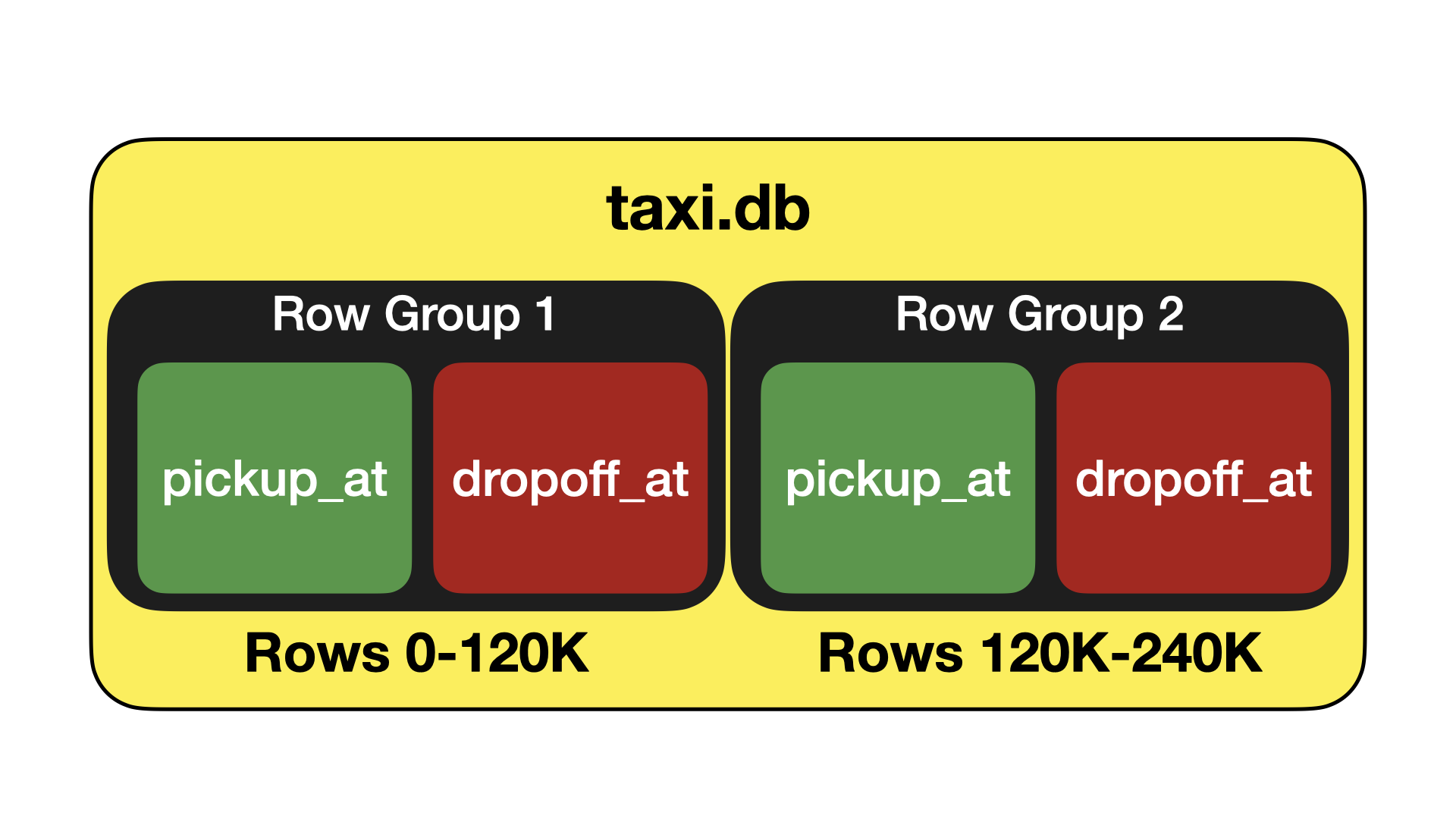
压缩框架在单个列段的上下文中操作。它分为两个阶段。首先,对列段中的数据进行分析。在此阶段,我们扫描段中的数据并找出该特定段的最佳压缩算法。之后,执行压缩,并将压缩后的数据写入磁盘上的块中。
虽然这种方法需要对段内数据进行两次遍历,但这并不会产生显著的成本,因为一个段中存储的数据量通常足够小,可以放入 CPU 缓存中。分析步骤也可以考虑采样方法,但总的来说,我们更看重选择最佳压缩算法和减少文件大小,而不是压缩速度的微小提升。
压缩算法
DuckDB 实现了几种轻量级压缩算法,我们正在向系统中添加更多算法。我们将在以下部分介绍其中的一些压缩算法及其工作原理。
常量编码
常量编码是 DuckDB 中最直接的压缩算法。当列段中的每个值都相同时,使用常量编码。在这种情况下,我们只存储那个单一值。此编码如下所示。
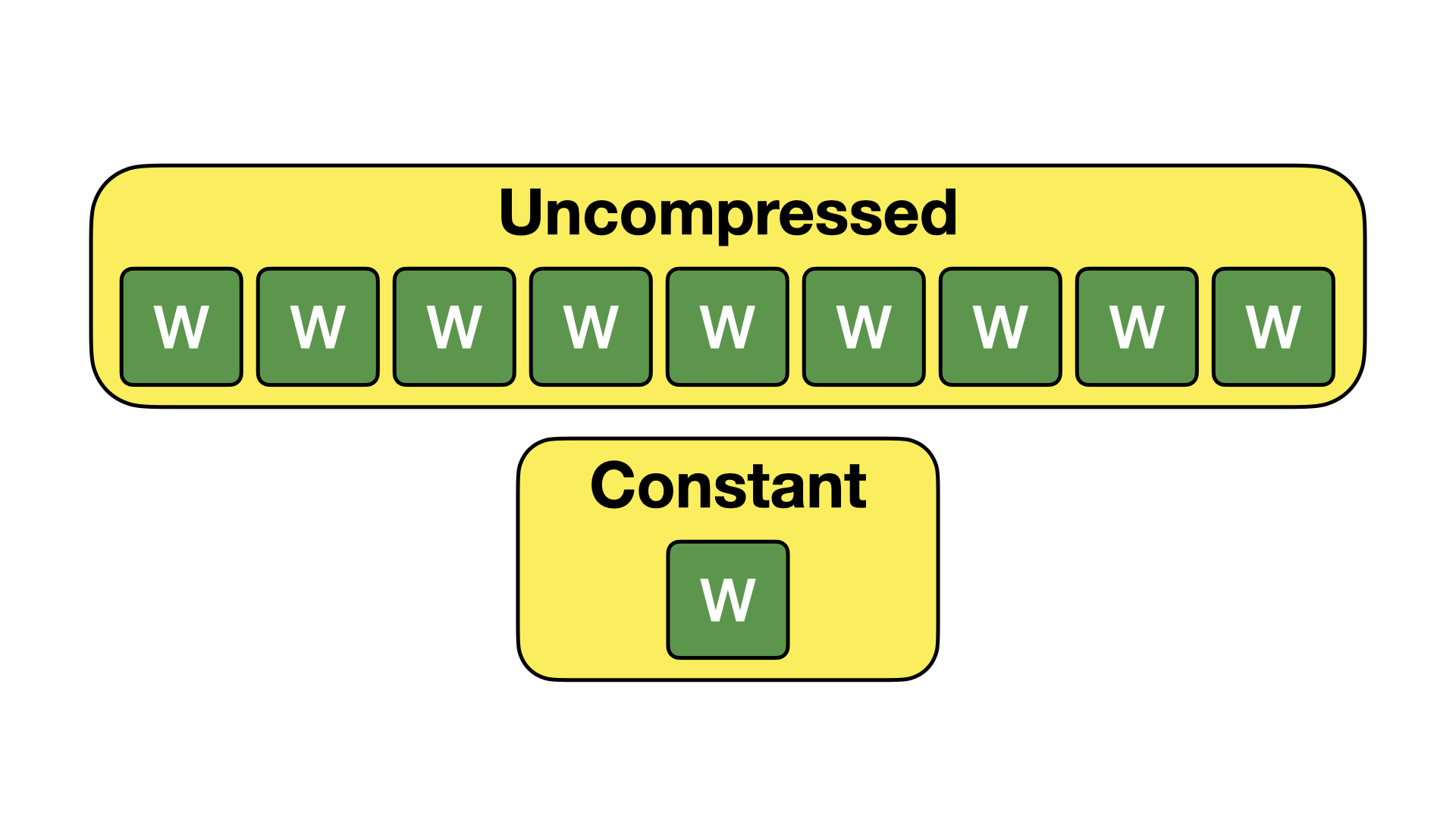
在适用情况下,这种编码技术能带来巨大的空间节省。虽然这种技术可能看起来很少适用——但实际上它发生的频率相对较高。列可能充满 NULL 值,或者具有很少更改的值(例如,传感器数据流中的 year 列)。由于这种压缩算法,此类列在 DuckDB 中几乎不占用空间。
游程编码 (RLE)
游程编码 (RLE) 是一种利用数据集中重复值进行压缩的算法。它不是存储单个值,而是将数据集分解成一对(值,计数)元组,其中计数表示该值重复的次数。此编码如下所示。
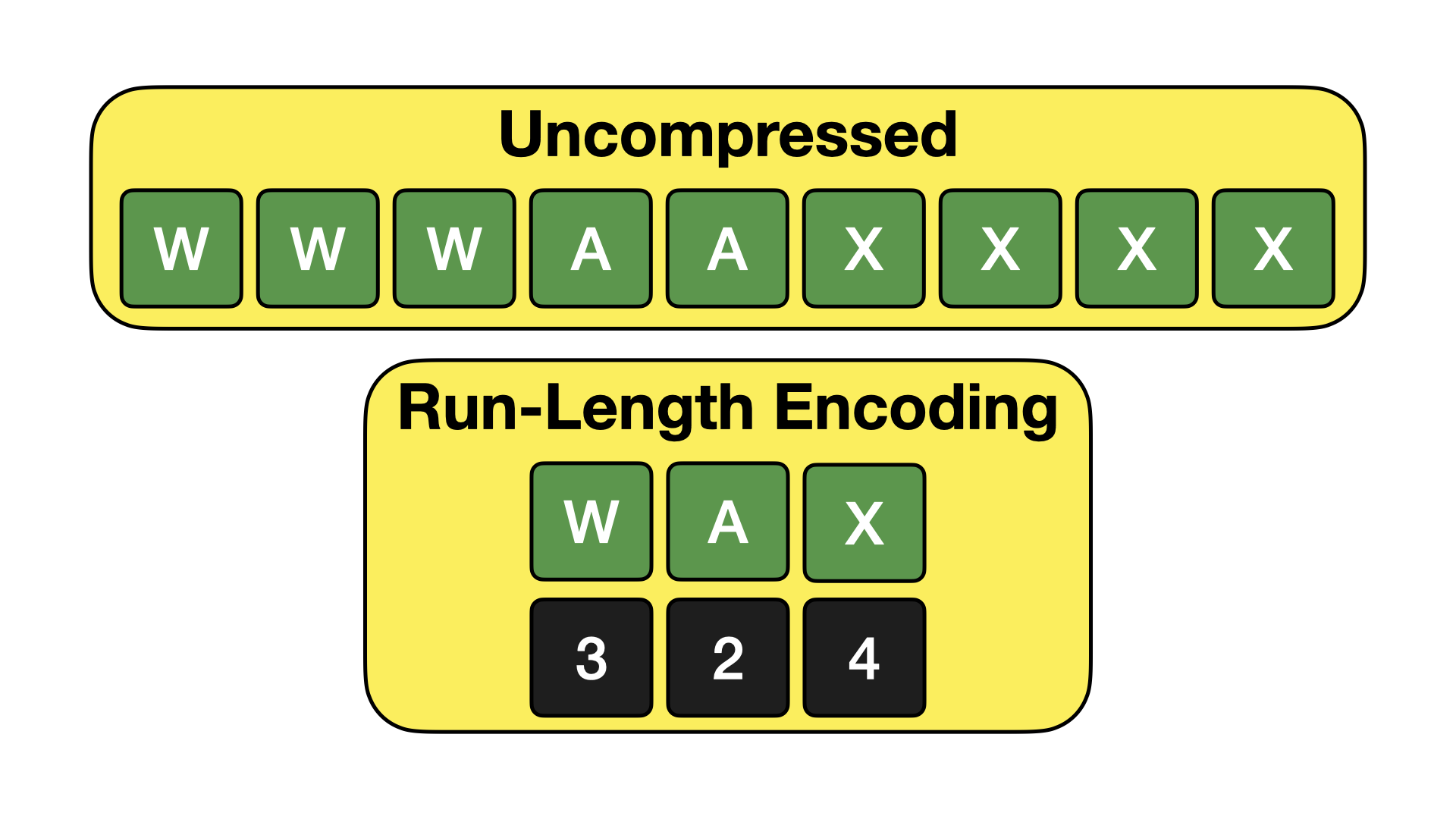
当数据中存在大量重复值时,RLE 非常强大。当数据按特定属性排序或分区时,可能会出现这种情况。它也适用于包含许多缺失(NULL)值的列。
位打包
位打包是一种压缩技术,它利用了整数值很少跨越其数据类型完整范围的事实。例如,四字节整数值可以存储从负二十亿到正二十亿的值。通常不会使用此数据类型的完整范围,而是只存储小数字。位打包通过在存储值时删除所有不必要的开头零来利用这一点。下面提供了一个示例(十进制)。

对于位打包压缩,我们跟踪每 1024 个值的最大值。最大值决定了位打包宽度,即存储该值所需的位数。例如,当存储一组最大值为 32 的值时,位打包宽度为 5 位,低于存储未压缩的四字节整数所需的每值 32 位。
位打包在实践中非常强大。它也方便用户——因为由于这项技术,使用各种整数类型之间没有存储大小差异。一个 BIGINT 列将与一个 INTEGER 列占用完全相同的空间。这减轻了用户担心选择哪种整数类型的烦恼。
参考帧
参考帧编码是位打包的扩展,其中我们还包含一个帧。帧是值集中找到的最小值。值以相对于该帧的偏移量存储。下面给出了一个示例。
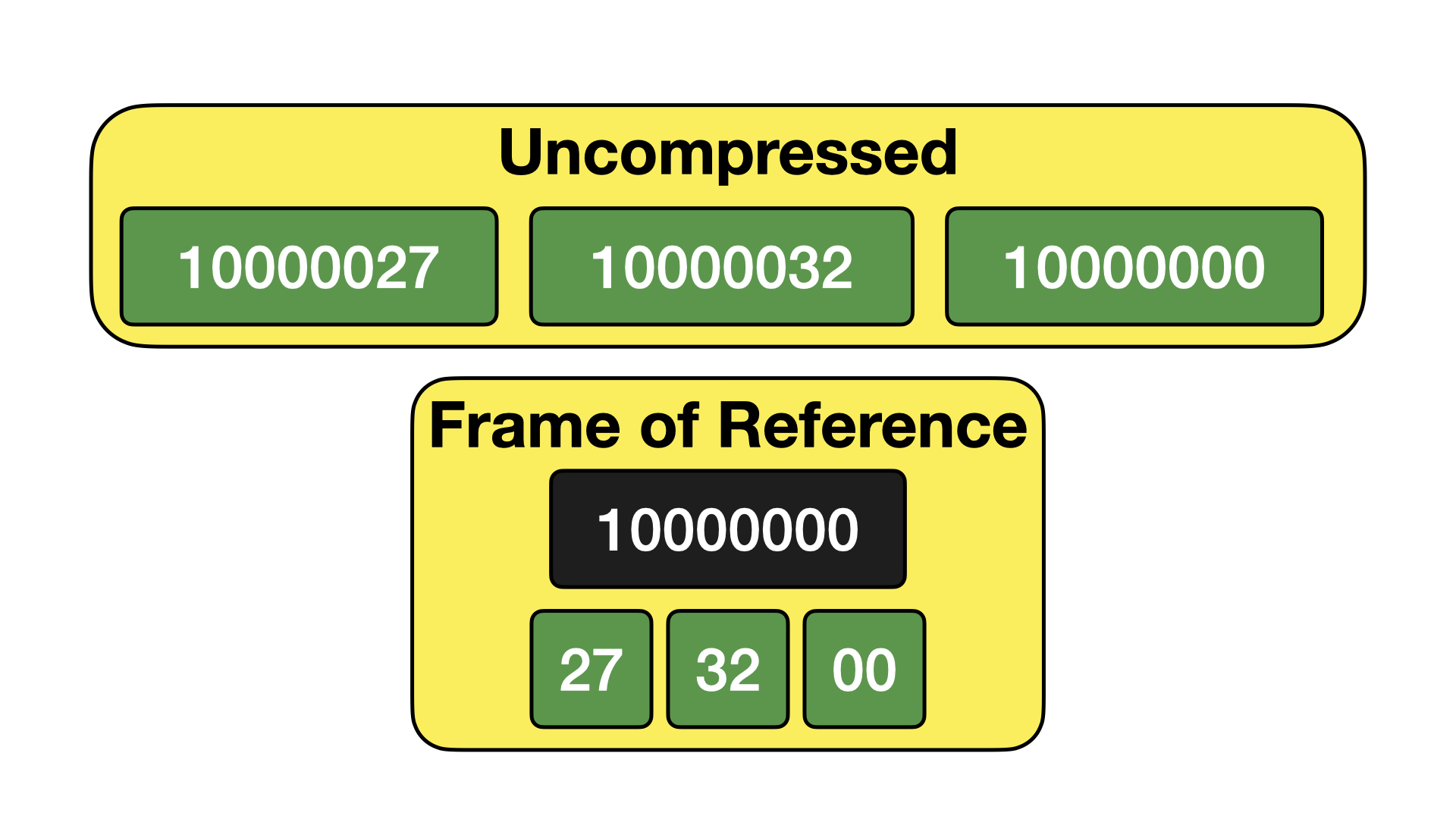
虽然这乍一看可能不那么有用,但在存储日期和时间戳时却非常强大。这是因为日期和时间戳在 DuckDB 中存储为 Unix 时间戳,即自 1970-01-01 以来的偏移量,可以是天数(日期)或微秒数(时间戳)。当我们有一组日期或时间戳值时,绝对数字可能非常高,但这些数字彼此之间都非常接近。通过在位打包之前应用一个帧,我们通常可以极大地提高压缩比。
字典编码
字典编码通过将常见值提取到单独的字典中,然后用对该字典的引用替换原始值来工作。下面提供了一个示例。
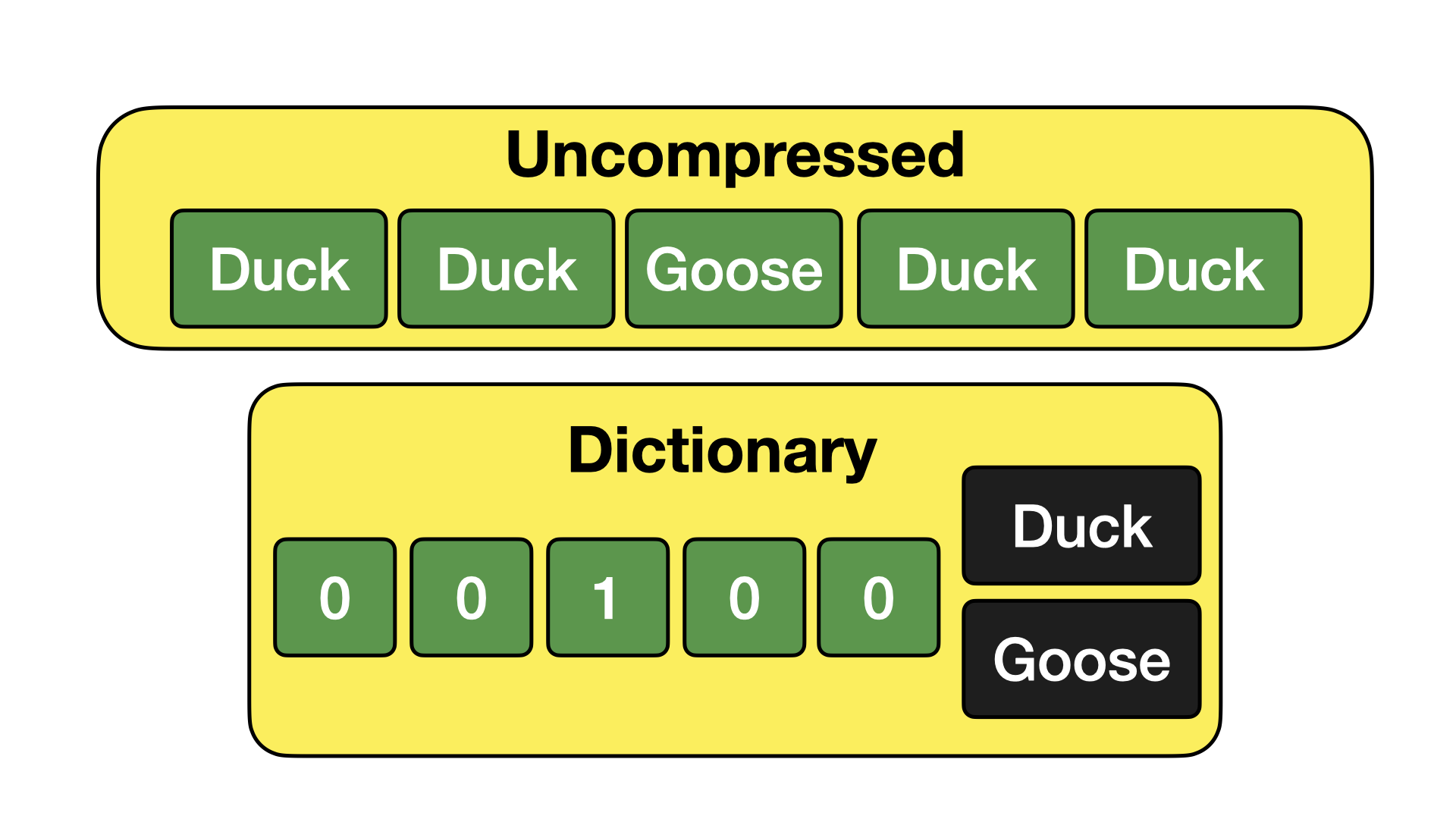
字典编码在存储包含许多重复条目的文本列时特别高效。大得多的文本值可以被小的数字代替,这些小数字又可以有效地进行位打包。
FSST
快速静态符号表压缩是字典压缩的扩展,它不仅提取整个字符串的重复,还提取字符串内部的重复。当存储本身是唯一的但字符串内部有大量重复(例如 URL 或电子邮件地址)的字符串时,这种方法很有效。下面是说明其工作原理的图像。

有兴趣了解更多信息的人,请在此处观看 Peter Boncz 的演讲。
Chimp & Patas
Chimp 是一种非常新的压缩算法,旨在压缩浮点值。它基于 Gorilla 压缩。Gorilla 和 Chimp 的核心思想是,浮点值进行异或运算后,似乎会产生带有许多尾随和前导零的小值。然后这些算法致力于寻找一种有效存储尾随和前导零的方法。
在实现了 Chimp 之后,我们受到了启发并着手实现 Patas,它采用了许多相同的思想,但进一步优化以获得更高的解压缩速度。敬请期待未来的博客文章,很快会更详细地解释这些内容!
检查压缩
可以使用 PRAGMA storage_info 来检查表和列的存储布局。这可以用来检查 DuckDB 为压缩表的特定列选择了哪种压缩算法。
SELECT * EXCLUDE (column_path, segment_id, start, stats, persistent, block_id, block_offset, has_updates)
FROM pragma_storage_info('taxi')
USING SAMPLE 10 ROWS
ORDER BY row_group_id;
| 行组 ID | 列名 (column_name) | 列 ID | 段类型 | 计数 | 压缩 |
|---|---|---|---|---|---|
| 4 | 额外信息 (extra) | 13 | FLOAT | 65536 | Chimp |
| 20 | 小费金额 | 15 | FLOAT | 65536 | Chimp |
| 26 | 上车纬度 | 6 | 有效性 | 65536 | 常量 |
| 46 | 过路费金额 | 16 | FLOAT | 65536 | RLE |
| 73 | 存储转发标记 | 8 | 有效性 | 65536 | 未压缩 |
| 96 | 总金额 | 17 | 有效性 | 65536 | 常量 |
| 111 | 总金额 | 17 | 有效性 | 65536 | 常量 |
| 141 | 上车时间 | 1 | 时间戳 | 52224 | 位打包 |
| 201 | 上车经度 | 5 | 有效性 | 65536 | 常量 |
| 209 | 乘客数量 | 3 | TINYINT | 65536 | 位打包 |
结论与未来目标
压缩在 DuckDB 中取得了巨大的成功,我们在降低系统存储需求方面取得了长足进步。我们仍在积极努力扩展 DuckDB 内的压缩功能,并希望通过改进现有技术和实现其他几种技术,进一步提高系统的压缩比。我们的目标是实现在使用 Parquet 和 Snappy 时同等水平的压缩,同时仅使用操作速度非常快的轻量级专用压缩技术。

