DuckDB 中的内存管理

内存是处理大量数据时的重要资源。内存是一个快速缓存层,可以极大地加速查询处理。然而,内存是有限且昂贵的,在处理大型数据集时,通常没有足够的内存来缓存所有必要的数据结构。有效管理内存对于高性能查询引擎至关重要——因为必须利用内存才能提供高性能,但我们必须小心,不要使用过多的内存,这可能导致内存不足错误,或导致不祥的 OOM killer(内存不足杀手) 终止进程。
DuckDB 旨在有效利用可用内存,同时避免内存耗尽
- 流式执行引擎允许小块数据流经系统,而无需将整个数据集在内存中具体化。
- 中间结果数据可以临时溢写到磁盘,以释放内存空间,从而允许计算原本会超出可用内存的复杂查询。
- 缓冲区管理器会尽可能多地缓存来自任何附加数据库的页面,而不超过预设的内存限制。
在本博客文章中,我们将涵盖 DuckDB 内部内存管理的这些方面,并提供它们被利用的示例。
流式执行
DuckDB 使用流式执行引擎来处理查询。数据源(例如表、CSV 文件或 Parquet 文件)从不完全在内存中具体化。相反,数据一次读取和处理一个数据块。例如,考虑执行以下查询:
SELECT
UserAgent,
count(*)
FROM 'hits.csv'
GROUP BY UserAgent;
DuckDB 不会一次性读取整个 CSV 文件,而是分块从 CSV 文件中读取数据,并利用从这些数据块中读取的数据逐步计算聚合。这个过程持续进行,直到整个 CSV 文件被读取完毕,此时,整个聚合结果就被计算出来。
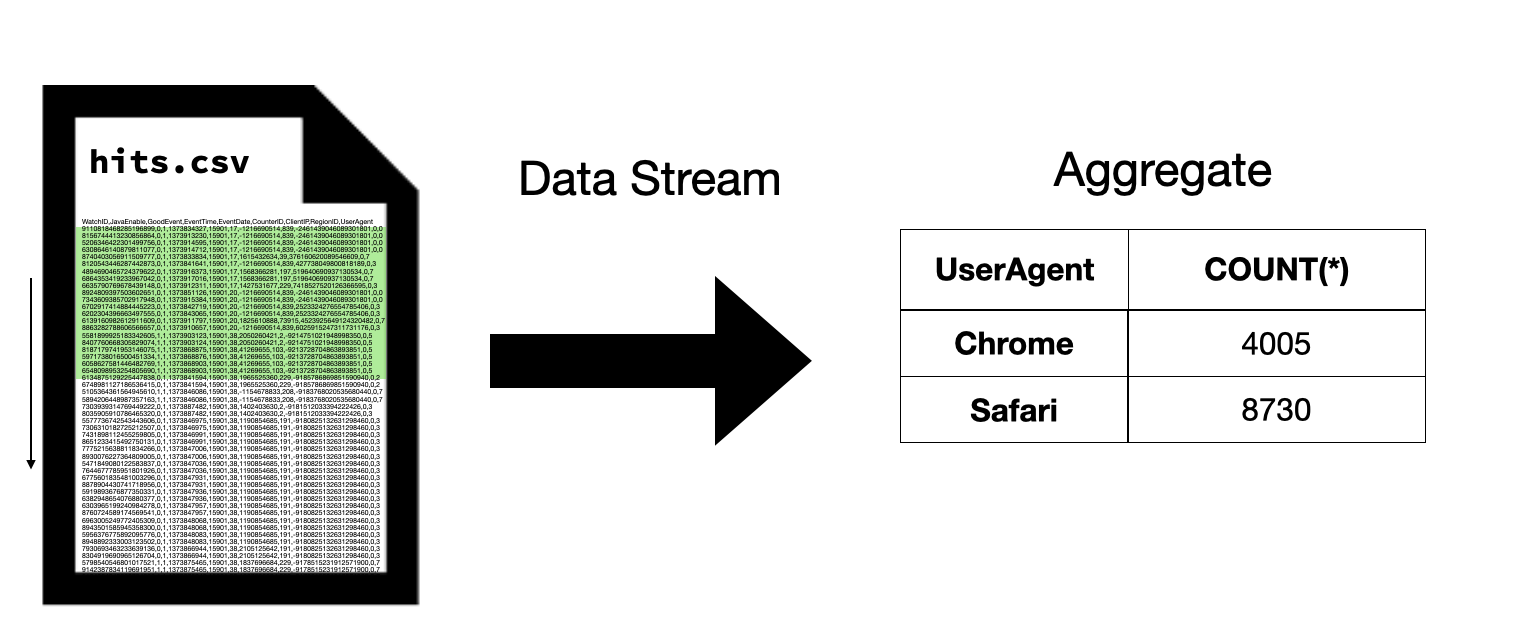
在上述示例中,我们只展示了单个数据流。实际上,DuckDB 使用多个数据流来实现多线程执行——每个线程执行自己的数据流。不同线程的聚合结果会合并以计算最终结果。
尽管流式执行在概念上很简单,但它功能强大,足以在许多简单用例中提供超出内存大小的支持。例如,流式执行支持超出内存大小的以下操作:
- 计算总组数较小的聚合
- 从一个文件读取数据并写入另一个文件(例如,从 CSV 读取并写入 Parquet)
- 计算数据的 Top-N(其中 N 较小)
请注意,无需进行任何操作即可启用流式执行——DuckDB 始终以这种方式处理查询。
中间结果溢写
虽然流式执行可以为简单查询提供超出内存大小的处理能力,但在许多情况下,仅凭流式执行是不够的。
在上一个示例中,流式执行能够支持超出内存大小的处理,因为计算出的聚合结果非常小——与网络请求总数相比,唯一的用户代理非常少。因此,聚合哈希表将始终保持较小,并且永远不会超过可用内存量。
如果处理查询所需的中间结果大于内存,则流式执行是不够的。例如,假设我们在上一个示例中按源 IP 进行分组:
SELECT
IPNetworkID,
count(*)
FROM 'hits.csv'
GROUP BY IPNetworkID;
由于有更多的唯一源 IP,我们需要维护的哈希表会显著增大。如果聚合哈希表的大小超出内存,流式执行引擎不足以防止内存不足问题。
超出内存大小的中间结果可能在许多场景中出现,特别是在执行更复杂的查询时。例如,以下场景可能导致超出内存大小的中间结果:
- 计算包含许多唯一组的聚合
- 计算具有许多不同值的列的精确去重计数
- 连接两个都超出内存大小的表
- 对超出内存大小的数据集进行排序
- 对超出内存大小的表计算复杂窗口函数
DuckDB 通过磁盘溢写来处理这些场景。当需要时,超出内存大小的中间结果会(部分)写入到临时目录的磁盘上。尽管功能强大,但磁盘溢写会降低性能——因为必须执行额外的 I/O 操作。因此,DuckDB 尽量减少磁盘溢写。只有当中间结果的大小超出内存限制时,才会自适应地使用磁盘溢写。即使在这些场景下,也会尽可能多地将数据保留在内存中以最大化性能。具体实现方式取决于操作符,并在其他博客文章中详细介绍(聚合、排序)。
memory_limit 设置控制 DuckDB 允许在内存中保留多少数据。默认情况下,它设置为系统物理内存的 80%(例如,如果您的系统有 16 GB 内存,则默认为 12.8 GB)。可以使用以下命令更改内存限制:
SET memory_limit = '4GB';
可以使用 temp_directory 设置选择临时目录的位置,默认情况下是带有 .tmp 后缀的连接数据库(例如 database.db.tmp),或如果连接到内存数据库,则仅为 .tmp。临时目录的最大大小可以使用 max_temp_directory_size 设置进行限制,该设置默认为存储临时文件的驱动器上剩余磁盘空间的 90%。这些设置可以按如下方式调整:
SET temp_directory = '/tmp/duckdb_swap';
SET max_temp_directory_size = '100GB';
如果内存限制被超出且无法使用磁盘溢写,无论是由于磁盘溢写被明确禁用、临时目录大小超出所提供的限制,还是由于系统限制导致无法对给定查询使用磁盘溢写——都会报告内存不足错误并取消查询。
缓冲区管理器
DuckDB 内存管理的另一个核心组件是缓冲区管理器。缓冲区管理器负责缓存来自 DuckDB 自身持久存储的页面。从概念上讲,缓冲区管理器的工作方式与中间结果溢写类似。页面会尽可能保留在内存中,当需要空间用于其他数据结构时,它们会被从内存中逐出。缓冲区管理器遵守与任何中间数据结构相同的内存限制。缓冲区管理器中的页面可以被释放,以为中间数据结构腾出空间,反之亦然。
缓冲区管理器和中间数据结构之间有两个主要区别:
- 由于缓冲区管理器缓存的是已存在于磁盘上(在 DuckDB 的持久存储中)的页面——因此在逐出时无需写入临时目录。相反,当再次需要它们时,可以直接从附加的存储文件中重新读取。
- 查询中间结果具有自然的生命周期,即当查询处理完成后,这些中间结果就不再需要了。而从持久存储中缓冲区管理的页面则在多个查询中都有用。因此,缓冲区管理器保留的页面会一直被缓存,直到持久化数据库关闭,或者直到必须为其他操作释放空间。
缓冲区管理器的性能提升取决于底层存储介质的速度。当数据存储在非常快的磁盘上时,读取数据速度很快,性能提升微乎其微。当数据存储在网络驱动器上或通过 HTTP/S3 读取时,读取需要执行网络请求,此时性能提升会非常显著。
分析内存使用情况
DuckDB 包含许多可用于分析内存使用情况的工具。
duckdb_memory() 函数可用于检查系统哪些组件正在使用内存。缓冲区管理器使用的内存被标记为 BASE_TABLE,而查询中间结果则分为不同的组。
FROM duckdb_memory();
┌──────────────────┬────────────────────┬─────────────────────────┐
│ tag │ memory_usage_bytes │ temporary_storage_bytes │
│ varchar │ int64 │ int64 │
├──────────────────┼────────────────────┼─────────────────────────┤
│ BASE_TABLE │ 168558592 │ 0 │
│ HASH_TABLE │ 0 │ 0 │
│ PARQUET_READER │ 0 │ 0 │
│ CSV_READER │ 0 │ 0 │
│ ORDER_BY │ 0 │ 0 │
│ ART_INDEX │ 0 │ 0 │
│ COLUMN_DATA │ 0 │ 0 │
│ METADATA │ 0 │ 0 │
│ OVERFLOW_STRINGS │ 0 │ 0 │
│ IN_MEMORY_TABLE │ 0 │ 0 │
│ ALLOCATOR │ 0 │ 0 │
│ EXTENSION │ 0 │ 0 │
├──────────────────┴────────────────────┴─────────────────────────┤
│ 12 rows 3 columns │
└─────────────────────────────────────────────────────────────────┘
duckdb_temporary_files 函数可用于检查临时目录的当前内容。
FROM duckdb_temporary_files();
┌────────────────────────────────┬───────────┐
│ path │ size │
│ varchar │ int64 │
├────────────────────────────────┼───────────┤
│ .tmp/duckdb_temp_storage-0.tmp │ 967049216 │
└────────────────────────────────┴───────────┘
结论
内存管理对于高性能分析引擎至关重要。DuckDB 旨在利用任何可用内存来加速查询处理,同时通过中间结果溢写优雅地处理超出内存大小的数据集。内存管理仍然是一个活跃的开发领域,并且在 DuckDB 的各个版本中持续改进。除此之外,我们正在努力改进涉及多个操作符且具有超出内存大小中间结果的复杂查询的内存管理。

