DuckDB 随时间推移的性能基准测试

简而言之:在过去的 3 年里,DuckDB 的速度提高了 3-25 倍,并且可以在相同的硬件上分析大约 10 倍大的数据集。
DuckDB 的一个重要关注点是开发人员使用数据的体验。但是,在研究数据管理系统时,性能是一个重要的考虑因素。使用基准测试公平地比较数据处理系统非常困难。创建基准测试的人可能比其他人更了解一个系统,从而影响基准测试的选择、调整参数所花费的时间等等。
相反,这篇文章重点介绍随时间推移我们自己的性能基准测试。这种方法避免了许多比较陷阱,并且还提供了几个有价值的数据点,供选择系统时考虑。
-
它的改进速度有多快? 学习新工具是一种投资。选择一个充满活力、快速改进的数据库可以确保您的选择在未来几年内获得回报。此外,如果您有一段时间没有尝试过某个工具,您可以了解它自您上次检查以来变得有多快!
-
它特别擅长什么? 基准测试的选择表明了该工具适用于哪些类型的工作负载。基准测试中分析的多样性越高,该工具的用途就越广泛。
-
它可以处理什么规模的数据? 许多基准测试故意小于典型的工作负载。这允许基准测试在使用许多配置运行时在合理的时间内完成。但是,选择系统时要回答的一个重要问题是,您数据的大小是否可以在您的计算资源的大小范围内处理。
随着时间的推移,查看系统的性能存在一些限制。如果某个功能是全新的,则没有以前的性能可以比较!因此,这篇文章侧重于基本工作负载,而不是 DuckDB 不断增加的与不同湖仓一体数据格式、云服务等集成。
用于运行基准测试的代码也避免了 DuckDB 的许多更友好的 SQL添加,因为这些添加也是最近添加的。(在编写这些查询时,感觉就像回到了过去!)
基准测试设计摘要
这篇文章使用 H2O.ai 基准测试以及一些为导入、导出和使用窗口函数而添加的新基准测试来衡量 DuckDB 随时间推移的性能。有关我们为何认为 H2O.ai 基准测试是一种好方法的详细信息,请参阅我们之前的博客文章!基准测试设计的完整详细信息在附录中。
- H2O.ai,加上导入/导出和窗口函数测试
- Python 而不是 R
- 所有内容的规模为 5 GB,group by 和 join 的规模为 50 GB
- 3 次运行的中位数
- 使用配备 16 GB RAM 的 MacBook Pro M1
- DuckDB 版本 0.2.7 到 1.0.0
- 近 3 年,从 2021-06-14 到 2024-06-03
- 默认设置
- Pandas 0.5.1 之前的版本,Apache Arrow 0.5.1+
总体基准测试结果
最新的 DuckDB 可以在 35 秒内完成完整基准测试套件的一次运行,而 2021 年 6 月的版本 0.2.7 完成相同的任务需要近 500 秒。这在短短 3 年内快了 14 倍!
随时间推移的性能
注意:感谢 Plotly.js,这些图表是交互式的!随意过滤各种系列(单击隐藏,双击仅显示该系列)并单击并拖动以放大。单个基准测试结果在悬停时可见。
上面的图显示了所有测试的中位数运行时间(以秒为单位)。由于窗口函数的多种用途及其相对算法复杂性,16 个窗口函数测试比任何类别都需要花费最多的时间。
此图将性能标准化为最新版本的 DuckDB,以显示随时间推移的相对改进。如果您查看您最近衡量 DuckDB 性能的时间点,该数字将显示 DuckDB 现在快了多少倍!
总体改进的一部分是 DuckDB 添加了多线程,这在 2021 年 11 月的版本 0.3.1 中成为默认设置。DuckDB 也在该版本中迁移到基于推送的执行模型,以获得额外的收益。并行数据加载在 2022 年 12 月的版本 0.6.1 中提高了性能,核心 JOIN 算法的改进也是如此。我们将在本文后面详细探讨其他改进。
但是,我们看到系统的所有方面都得到了改进,而不仅仅是原始查询性能!DuckDB 专注于整个数据分析工作流程,而不仅仅是聚合或连接性能。CSV 解析取得了显着进展,导入和导出显着改进,并且窗口函数的改进最多。
从 2022 年 12 月到 2023 年 6 月的轻微倒退是什么?窗口函数获得了额外的功能,并且在此过程中经历了轻微的性能下降。但是,从 2023 年 6 月开始,我们看到窗口函数在各个方面的性能都得到了显着提高。如果从图表中过滤掉窗口函数,我们会看到一个更平滑的趋势。
您可能还会注意到,从 2023 年 9 月的版本 0.9 开始,性能似乎趋于稳定。这里发生了什么?首先,不要忘记放大!在过去的一年中,DuckDB 仍然改进了 3 倍以上!最近,DuckDB Labs 团队专注于可扩展性,开发了支持大于内存计算的算法。稍后我们将在规模部分看到这些劳动的成果!此外,DuckDB 专注于版本 0.10.1、0.10.2 和 0.10.3 中的错误修复,为特别强大的 DuckDB 1.0 做准备。既然这两个主要里程碑(大于内存的计算和 DuckDB 1.0)已经完成,性能改进将恢复!值得注意的是,迁移到多线程的提升只会发生一次,但未来仍有许多机会。
按版本划分的性能
我们还可以按版本而不是按时间重新创建总体图。这表明 DuckDB 最近发布了更频繁的版本。有关完整的版本历史记录,请参阅DuckDB 的发布日历。
如果您记得您上次测试的版本,您可以比较现在 1.0 的速度快多少!
按工作负载划分的结果
CSV 读取器
DuckDB 大量投资于构建快速而强大的 CSV 解析器。这通常是数据分析工作负载中的第一项任务,它往往被低估和基准测试不足。DuckDB 在自动处理更多 CSV 变体的同时,将 CSV 读取器性能提高了近 3 倍。
Group By
Group by 或聚合操作是 OLAP 工作负载中的关键步骤,因此在 DuckDB 中受到了大量关注,在过去 3 年中提高了 12 倍以上。
2021 年 11 月,版本 0.3.1 默认启用了多线程聚合,从而显着提高了速度。
2022 年 12 月,随着版本 0.6.1 的发布,数据加载到表中实现了并行化。这是改进整个数据工作流程的另一个示例,因为此 group by 基准测试实际上显着强调了插入性能。插入结果花费了大部分时间!
枚举也在版本 0.6.1 中用于代替分类列的字符串。这意味着 DuckDB 能够在操作这些列时使用整数而不是字符串,从而进一步提高性能。
尽管乍一看似乎是性能平台期,但放大到 2023 年和 2024 年会发现大约 20% 的改进。此外,最近的版本对聚合进行了大量关注,以实现大于内存的聚合。您可以看到,这是在继续提高小于内存的情况下的性能的同时实现的。
Join
Join 操作是分析数据库(尤其是 DuckDB)的另一个重点领域。Join 速度在过去 3 年中提高了 4 倍!
2022 年 12 月的版本 0.6.1 对核心外哈希连接进行了改进,实际上也改进了小于内存的情况。来自 0.6.1 的并行数据加载也对此基准测试有所帮助,因为某些结果的大小与输入表相同。
在最近的版本中,Join 也已升级为支持大于内存的功能。这种关注也使小于内存的情况受益,并导致了 2024 年 2 月推出的 0.10 中的改进。
窗口函数
在研究的时间范围内,窗口函数显着提高了 25 倍!
窗口函数性能在 2023 年 9 月发布的 0.9.0 版本中得到了显着提高。贡献了 14 种不同的性能优化。聚合计算已向量化(特别关注段树数据结构)。工作窃取实现了多线程处理,并且对排序进行了调整以并行运行。还注意以更大的批次预分配内存。
DuckDB 的窗口函数还能够处理大于内存的数据集。我们将为未来的工作留下该功能的基准测试!
导出
通常,DuckDB 不是工作流程中的最后一步,因此导出性能会产生影响。现在的导出速度提高了 10 倍!直到最近,DuckDB 格式才向后兼容,因此推荐的长期持久性格式是 Parquet。Parquet 对于与许多其他系统(尤其是数据湖)的互操作性也至关重要。DuckDB 可以很好地用作工作流程引擎,因此导出到其他内存格式也很常见。
在 2022 年 9 月的版本(版本 0.5.1)中,我们看到由从 Pandas 切换到 Apache Arrow 作为推荐的内存导出格式所驱动的显着改进。DuckDB 的底层数据类型与 Arrow 有许多相似之处,因此数据传输非常快。
Parquet 导出性能在基准测试过程中提高了 4-5 倍,在版本 0.8.1(2023 年 6 月)和 0.10.2(2024 年 4 月)中有了显着改进。版本 0.8.1 添加了并行 Parquet 写入,同时继续保留插入顺序。
驱动 0.10.2 中改进的更改更加微妙。导出具有高基数的字符串时,DuckDB 会根据是否减少文件大小来决定是否进行字典压缩。从 0.10.2 开始,在将所有值添加到字典后,将在将值的样本插入到字典后测试压缩率。这可以防止对高基数列进行大量不必要的处理,在这种情况下,字典压缩没有帮助。
导出 Apache Arrow vs. Pandas vs. Parquet
此图显示了所有三种导出格式在整个时间范围内的性能(而不是选择 Pandas 和 Arrow 之间的优胜者)。它使我们可以看到 Apache Arrow 在什么时间点超过 Pandas 的性能。
在基准测试过程中,Pandas 导出性能得到了显着提高。但是,Apache Arrow 已被证明是更有效的数据格式,因此 Arrow 现在是内存导出的首选。有趣的是,DuckDB 的 Parquet 导出现在非常高效,以至于写入持久性 Parquet 文件比写入内存 Pandas 数据帧更快!它甚至可以与 Apache Arrow 竞争。
扫描其他格式
在某些用例中,DuckDB 不需要存储原始数据,而只需读取和分析它。这使 DuckDB 可以无缝地融入其他工作流程。此基准测试衡量 DuckDB 可以扫描和聚合各种数据格式的速度。
为了实现随时间推移的比较,我们如前所述在版本 0.5.1 中从 Pandas 切换到 Arrow。DuckDB 在此工作负载中的速度提高了 8 倍以上,并且所需的绝对时间非常短。DuckDB 非常适合此类工作!
扫描 Apache Arrow vs. Pandas vs. Parquet
我们再次检查了整个时间范围内的所有三种格式。
扫描数据时,Apache Arrow 和 Pandas 在性能上更具可比性。因此,虽然 Arrow 显然是导出的首选,但 DuckDB 会以类似的速度愉快地读取 Pandas。但是,在这种情况下,Arrow 和 Pandas 的内存性质使它们的性能比 Parquet 快 2-3 倍。从绝对意义上讲,完成此操作所需的时间只是基准测试的一小部分,因此其他操作应成为决定因素。
规模测试
分析大于内存的数据是 DuckDB 的一项超能力,使其可以用于比以前更大的数据分析任务。
在 2023 年 9 月发布的版本 0.9.0 中,DuckDB 的哈希聚合已得到增强,可以处理核心外(大于内存)的中间体。有关该算法的详细信息以及一些基准测试,请参见此博客文章。即使 group by 中的唯一组数量很大,这也允许 DuckDB 在仅具有 16 GB RAM 的 MacBook Pro 上聚合 10 亿行数据(大小为 50 GB)。这代表了在基准测试的 3 年过程中,聚合处理规模至少提高了 10 倍。
自 2022 年 12 月的版本 0.6.1 以来,DuckDB 的哈希连接运算符已支持大于内存的连接。但是,此基准测试的规模(加上基准测试硬件的有限 RAM)意味着此基准测试仍然无法成功完成。在 2024 年 2 月发布的版本 0.10.0 中,DuckDB 的内存管理得到了显着升级,可以处理所有需要大量内存的多个并发运算符。的0.10.0 发布博客文章分享了有关此功能的更多详细信息。
因此,到版本 0.10.0 时,DuckDB 能够处理明显大于内存的数据的计算,即使中间计算的大小很大。支持所有运算符,包括排序、聚合、连接和窗口化。未来的工作可以进一步测试 DuckDB 的核心外支持的边界,包括窗口函数和更大的数据大小。
随时间推移的硬件功能
DuckDB 在相同硬件上的性能得到了显着提高,与此同时,硬件的功能也在迅速提高。
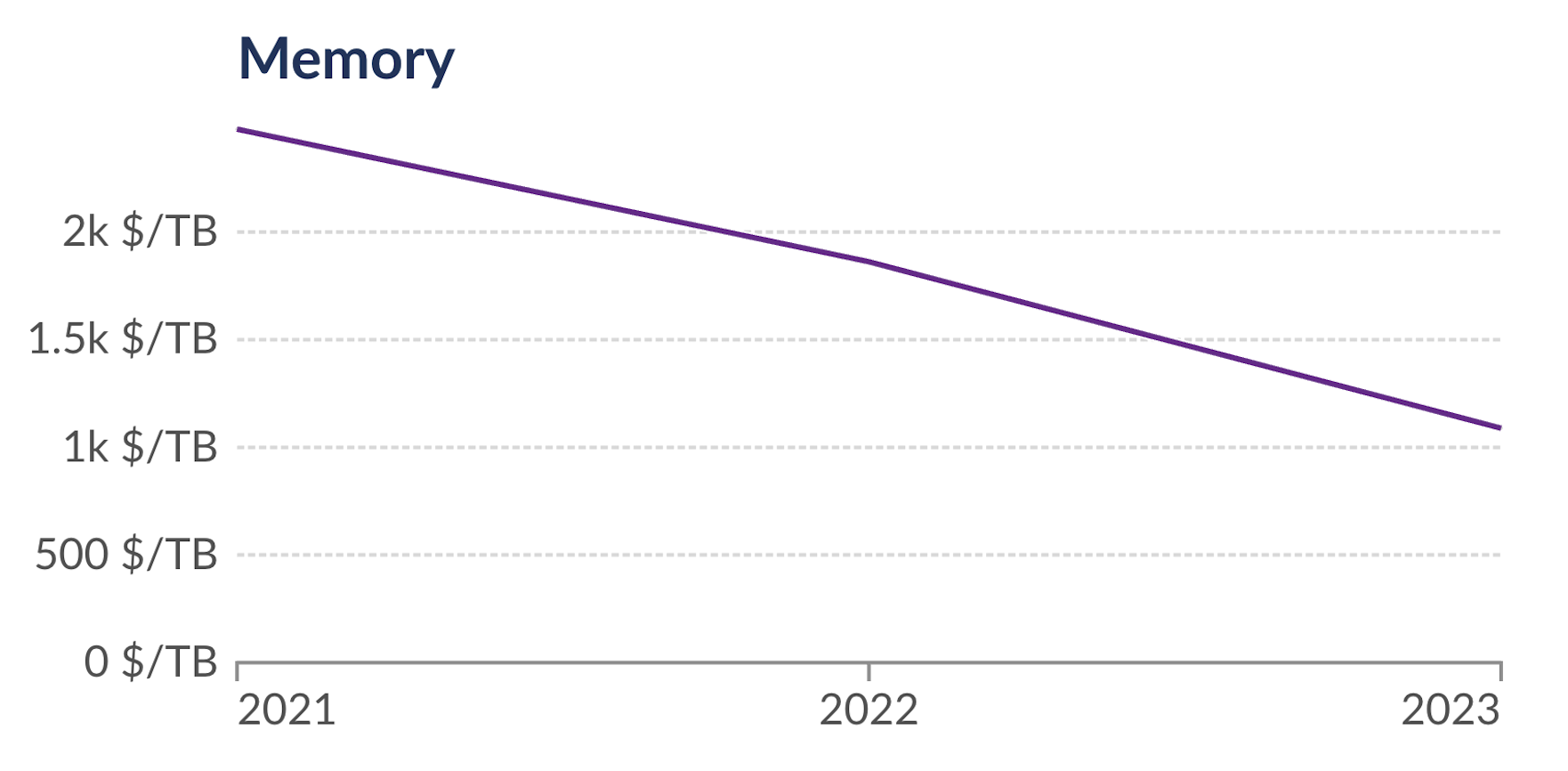
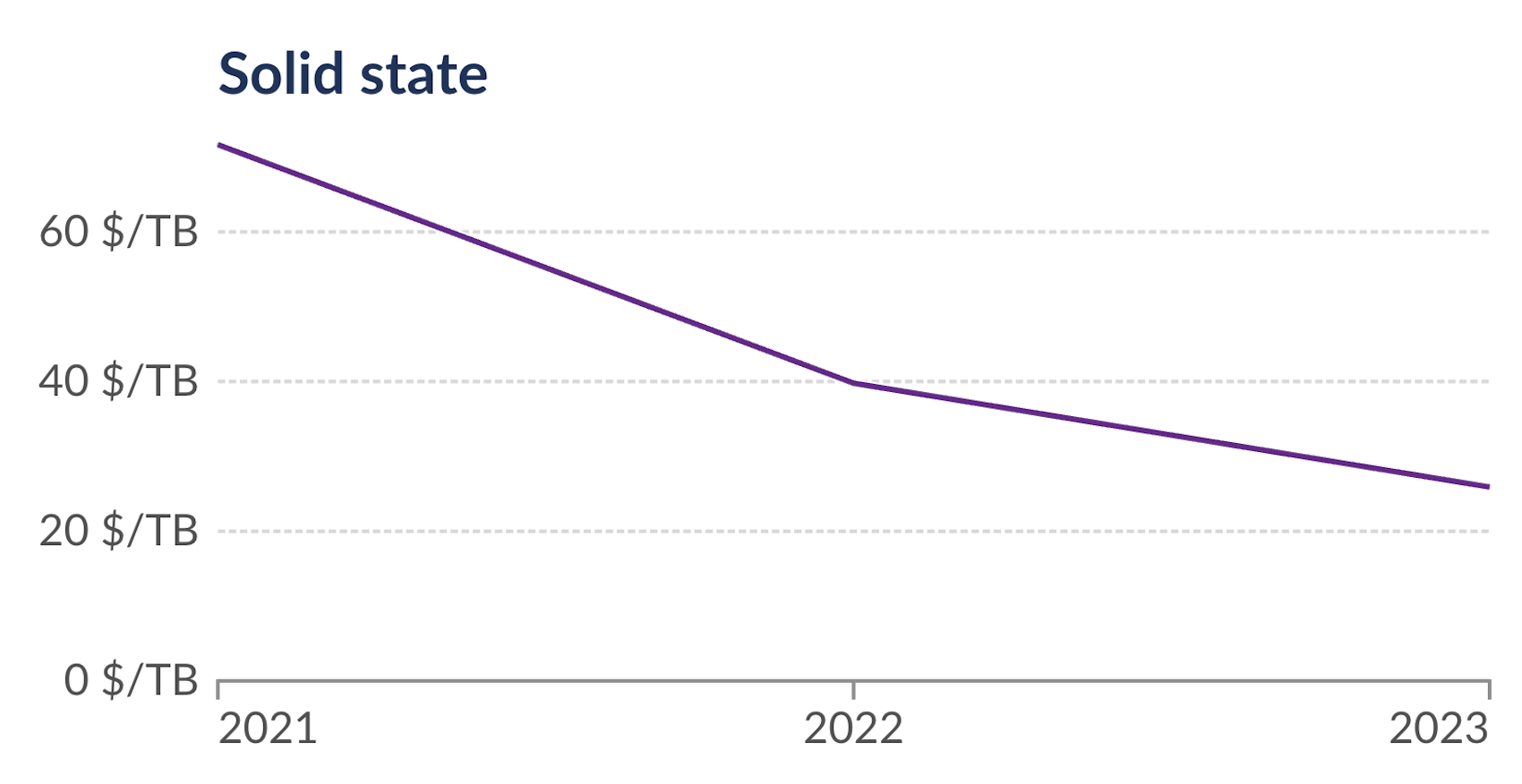
仅从 2021 年到 2023 年,RAM 的价格下降了 2.2 倍,SSD 存储的价格下降了 2.7 倍。由于 DuckDB 增强功能和硬件价格的结合,单节点上可能进行的分析规模在短短 3 年内增加了 10 倍以上!
自己分析结果
包含这些基准测试结果的 DuckDB 1.0 数据库可在 https://blobs.duckdb.org/data/duckdb_perf_over_time.duckdb 获得。任何具有 httpfs 扩展名的 DuckDB 客户端都可以读取该文件。
您甚至可以使用 DuckDB Wasm 网络 shell 从您的浏览器直接查询文件(使用预先填充并自动执行的查询!)
LOAD httpfs;
ATTACH 'https://blobs.duckdb.org/data/duckdb_perf_over_time.duckdb' AS performance_results;
USE performance_results;
该文件包含两个表:benchmark_results 和 scale_benchmark_results。如果您发现任何有趣的发现,请告诉我们!
结论
总而言之,DuckDB 的功能集不仅在每次发布时都在显着增长,而且 DuckDB 的速度也在飞速提高!总体而言,性能在短短 3 年内提高了 14 倍!
但是,查询性能只是故事的一部分!得益于功能齐全的 SQL 方言(包括高性能窗口函数),DuckDB 可以处理的各种工作负载非常广泛并且还在不断增长。此外,数据导入、CSV 解析和数据导出等关键工作负载的性能也随着时间的推移而得到了显着提高。完整的开发人员体验对于 DuckDB 来说至关重要!
最后,DuckDB 现在支持所有运算符(排序、聚合、连接和窗口化)的内存以上计算。您可以在当前计算资源上处理的问题的大小刚刚增加了 10 倍或更多!
如果您已经走到这一步,欢迎来到鸭群!🦆 加入我们的 Discord,我们重视您的反馈!
附录
基准测试设计
H2O.ai 作为基础
这篇文章衡量 DuckDB 在 H2O.ai 基准测试中,对连接和 group by 查询随时间推移的性能。
每个 H2O.ai 查询的结果都写入到持久性 DuckDB 文件中的一个表中。与内存工作流程相比,这确实需要额外的工作(尤其是 SSD 而不是 RAM 的负担),但可以提高可扩展性,并且是更大分析的常用方法。
与当前的 H2O.ai 基准测试一样,分类类型列(具有低基数的 VARCHAR 列)已作为基准测试的一部分转换为 ENUM 类型。转换为 ENUM 列的时间包含在基准测试时间中,并导致总时间缩短(因此,前期转换是值得的)。但是,在版本 0.6.1(2022 年 12 月)之前,ENUM 数据类型在 DuckDB 中尚未完全运行,因此早期版本会跳过此步骤。
Python 客户端
为了衡量与其他数据帧格式的互操作性,我们已将 Python 而不是 R(由 H2O.ai 使用)用于此分析。为了与基准测试保持一致,我们继续使用 R 进行数据生成步骤。Python 是 DuckDB 最受欢迎的客户端,非常适合数据科学,并且也是作者最喜欢的此类工作语言。
导出和替换扫描
我们现在以几种重要方式扩展此基准测试。除了考虑原始查询性能外,我们还衡量使用几种格式的导入和导出性能:Pandas、Apache Arrow 和 Apache Parquet。连接和 group by 基准测试的结果都导出为每种格式。
导出到数据帧时,我们测量了两种情况下的性能。但是,在总结总性能时,我们选择了当时性能最佳的格式。这可能反映了对性能敏感的用户的行为(因为他们可能不会同时写入两种格式!)。在 2022 年 9 月发布的版本 0.5.1 中,DuckDB 在写入和读取 Apache Arrow 格式时的性能超过了 Pandas。因此,版本 0.2.7 到 0.4.0 使用 Pandas,而 0.5.1 之后的版本使用 Arrow。
在导入方面,替换扫描允许 DuckDB 读取这些相同的格式,而无需先进行导入步骤。在替换扫描基准测试中,扫描的数据是最终 H2O.ai group by 基准测试查询的输出。在 5 GB 的规模下,它是 1 亿行的数据集。仅读取一列,并计算单个聚合。这会将基准测试的重点放在扫描数据的速度上,而不是 DuckDB 的聚合算法或输出结果的速度上。使用的查询遵循以下格式
SELECT
sum(v3) AS v3
FROM dataframe_or_Parquet_file;
窗口函数
我们还添加了一整套窗口函数基准测试。窗口函数是现实世界数据分析场景中的一项关键工作负载,并且可以通过其他方式来测试系统。DuckDB 已实施最先进的算法来快速处理即使是最复杂的窗口函数。我们使用连接基准测试中最大的表作为这些新测试的原始数据,以帮助与基准测试的其余部分进行比较。
窗口函数基准测试远不如传统的连接和聚合那么常见,我们无法找到合适的现成套件。这些查询旨在展示窗口函数的各种用途,但肯定可以添加更多。我们欢迎您提出要添加的查询建议,并希望这些查询可以证明对其他系统有用!
由于窗口函数基准测试是新的,因此每个包含的查询中的窗口函数都显示在帖子末尾的附录中。
工作负载大小
我们仅测试上述工作负载的中间 5 GB 数据集大小,主要是因为某些与外部格式(如 Pandas)的导入和导出操作必须适合内存(并且我们使用了仅具有 16 GB RAM 的 MacBook Pro M1)。此外,由于旧版本的性能,即使在该规模下,运行 21 个 DuckDB 版本的测试也很耗时。
规模测试
仅使用 5 GB 的数据无法回答我们的第二个关键问题:“它可以处理什么规模的数据?!”。我们还在 5 GB 和 50 GB 的规模下仅运行了与 group by 和连接相关的操作(避免内存导入和导出)。旧版本的 DuckDB 在连接或聚合时无法处理 50 GB 的数据集,但现代版本可以处理两者,即使在内存受限的 16 GB RAM 笔记本电脑上也是如此。我们没有衡量性能,而是衡量了能够在给定版本上完成的基准测试的大小。
摘要指标
除了规模测试外,每个基准测试都运行 3 次,并使用中位数时间来报告结果。规模测试运行一次,并在每个测试的数据大小处生成一个二进制指标:成功或失败。由于旧版本无法正常失败,因此规模指标是在多个部分运行中累积的。
计算资源
所有测试都使用配备 16 GB RAM 的 MacBook Pro M1。在 2024 年,这远非最先进的!如果您有更强大的硬件,您将看到性能和可扩展性都得到提高。
DuckDB 版本
2021 年 6 月发布的版本 0.2.7 是第一个包含为 ARM64 编译的 Python 客户端的版本,因此它是第一个可以在基准测试计算资源上轻松运行的版本。版本 1.0.0 是发布时(2024 年 6 月)可用的最新版本,尽管我们还提供了正在开发的功能分支的抢先预览。
默认设置
所有版本都使用默认设置运行。因此,只有在新功能成为默认设置并准备好用于生产工作负载后,新功能的改进才会出现在这些结果中。
窗口函数基准测试
每个基准测试查询都遵循以下格式,但在 window_function(s) 占位符中使用不同的窗口函数集。使用的表是 H2O.ai 连接基准测试中最大的表,在这种情况下,使用了 5 GB 的规模。
DROP TABLE IF EXISTS windowing_results;
CREATE TABLE windowing_results AS
SELECT
id1,
id2,
id3,
v2,
window_function(s)
FROM join_benchmark_largest_table;
替换占位符的各种窗口函数如下所示,并标记为与结果图表匹配。选择这些是为了展示窗口函数的各种用例,以及支持全部范围的语法所需的各种算法。DuckDB 文档包含可用语法的完整铁路图。如果此基准测试中没有很好地涵盖窗口函数的常见用例,请告诉我们!
/* 302 Basic Window */
sum(v2) OVER () AS window_basic
/* 303 Sorted Window */
first(v2) OVER (ORDER BY id3) AS first_order_by,
row_number() OVER (ORDER BY id3) AS row_number_order_by
/* 304 Quantiles Entire Dataset */
quantile_cont(v2, [0, 0.25, 0.50, 0.75, 1]) OVER ()
AS quantile_entire_dataset
/* 305 PARTITION BY */
sum(v2) OVER (PARTITION BY id1) AS sum_by_id1,
sum(v2) OVER (PARTITION BY id2) AS sum_by_id2,
sum(v2) OVER (PARTITION BY id3) AS sum_by_id3
/* 306 PARTITION BY ORDER BY */
first(v2) OVER
(PARTITION BY id2 ORDER BY id3) AS first_by_id2_ordered_by_id3
/* 307 Lead and Lag */
first(v2) OVER
(ORDER BY id3 ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING)
AS my_lag,
first(v2) OVER
(ORDER BY id3 ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING)
AS my_lead
/* 308 Moving Averages */
avg(v2) OVER
(ORDER BY id3 ROWS BETWEEN 100 PRECEDING AND CURRENT ROW)
AS my_moving_average,
avg(v2) OVER
(ORDER BY id3 ROWS BETWEEN id1 PRECEDING AND CURRENT ROW)
AS my_dynamic_moving_average
/* 309 Rolling Sum */
sum(v2) OVER
(ORDER BY id3 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS my_rolling_sum
/* 310 RANGE BETWEEN */
sum(v2) OVER
(ORDER BY v2 RANGE BETWEEN 3 PRECEDING AND CURRENT ROW)
AS my_range_between,
sum(v2) OVER
(ORDER BY v2 RANGE BETWEEN id1 PRECEDING AND CURRENT ROW)
AS my_dynamic_range_between
/* 311 Quantiles PARTITION BY */
quantile_cont(v2, [0, 0.25, 0.50, 0.75, 1])
OVER (PARTITION BY id2)
AS my_quantiles_by_id2
/* 312 Quantiles PARTITION BY ROWS BETWEEN */
first(v2) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING)
AS my_lag_by_id2,
first(v2) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING)
AS my_lead_by_id2
/* 313 Moving Averages PARTITION BY */
avg(v2) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN 100 PRECEDING AND CURRENT ROW)
AS my_moving_average_by_id2,
avg(v2) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN id1 PRECEDING AND CURRENT ROW)
AS my_dynamic_moving_average_by_id2
/* 314 Rolling Sum PARTITION BY */
sum(v2) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS my_rolling_sum_by_id2
/* 315 RANGE BETWEEN PARTITION BY */
sum(v2) OVER
(PARTITION BY id2 ORDER BY v2 RANGE BETWEEN 3 PRECEDING AND CURRENT ROW)
AS my_range_between_by_id2,
sum(v2) OVER
(PARTITION BY id2 ORDER BY v2 RANGE BETWEEN id1 PRECEDING AND CURRENT ROW)
AS my_dynamic_range_between_by_id2
/* 316 Quantiles PARTITION BY ROWS BETWEEN */
quantile_cont(v2, [0, 0.25, 0.50, 0.75, 1]) OVER
(PARTITION BY id2 ORDER BY id3 ROWS BETWEEN 100 PRECEDING AND CURRENT ROW)
AS my_quantiles_by_id2_rows_between

