DuckLake:SQL 作为湖仓一体格式
TL;DR: DuckLake 通过使用标准 SQL 数据库来管理所有元数据,而非复杂的基于文件的系统,从而简化了湖仓一体架构,同时数据仍以 Parquet 等开放格式存储。这使其更可靠、更快、更易于管理。
博客文章的第一部分与 DuckLake 宣言 共享。跳至 DuckLake 扩展部分 阅读其余内容。
背景
BigQuery 和 Snowflake 等创新数据系统表明,在存储已成为虚拟化商品的时代,分离存储和计算 是一个绝妙的主意。这样,存储和计算可以独立扩展,我们无需为了存储那些我们永远不会读取的表而购买昂贵的数据库机器。
与此同时,市场力量推动人们坚持数据系统使用 Parquet 等开放格式,以避免单一供应商对数据进行司空见惯的劫持。在这个新世界中,许多数据系统愉快地在基于 Parquet 和 S3 构建的原始“数据湖”中嬉戏,一切都很好。谁还需要那些老式数据库呢!
但很快就出现了一个令人震惊的事实——人们希望对他们的数据集进行更改。简单的追加操作通过将更多文件放入文件夹中即可很好地完成,但除此之外的任何操作都需要复杂且容易出错的自定义脚本,并且没有任何正确性概念,甚至没有——Codd 小心了——事务保证。
 一个真正的湖仓一体。也许更像湖边的小木屋。
一个真正的湖仓一体。也许更像湖边的小木屋。
Iceberg 和 Delta
为了解决数据湖中数据更改的基本任务,各种新的开放标准应运而生,其中最突出的是 Apache Iceberg 和 Linux Foundation Delta Lake。这两种格式的设计宗旨都是在不放弃基本前提(即在 Blob 存储上使用开放格式)的情况下,基本恢复对表进行更改的合理性。例如,Iceberg 使用 JSON 和 Avro 文件的迷宫来定义模式、快照以及在某个时间点哪些 Parquet 文件是表的一部分。其结果被称为 “湖仓一体”,这实际上是向数据湖添加了数据库功能,从而为数据管理带来了许多新的激动人心的用例,例如跨引擎数据共享。
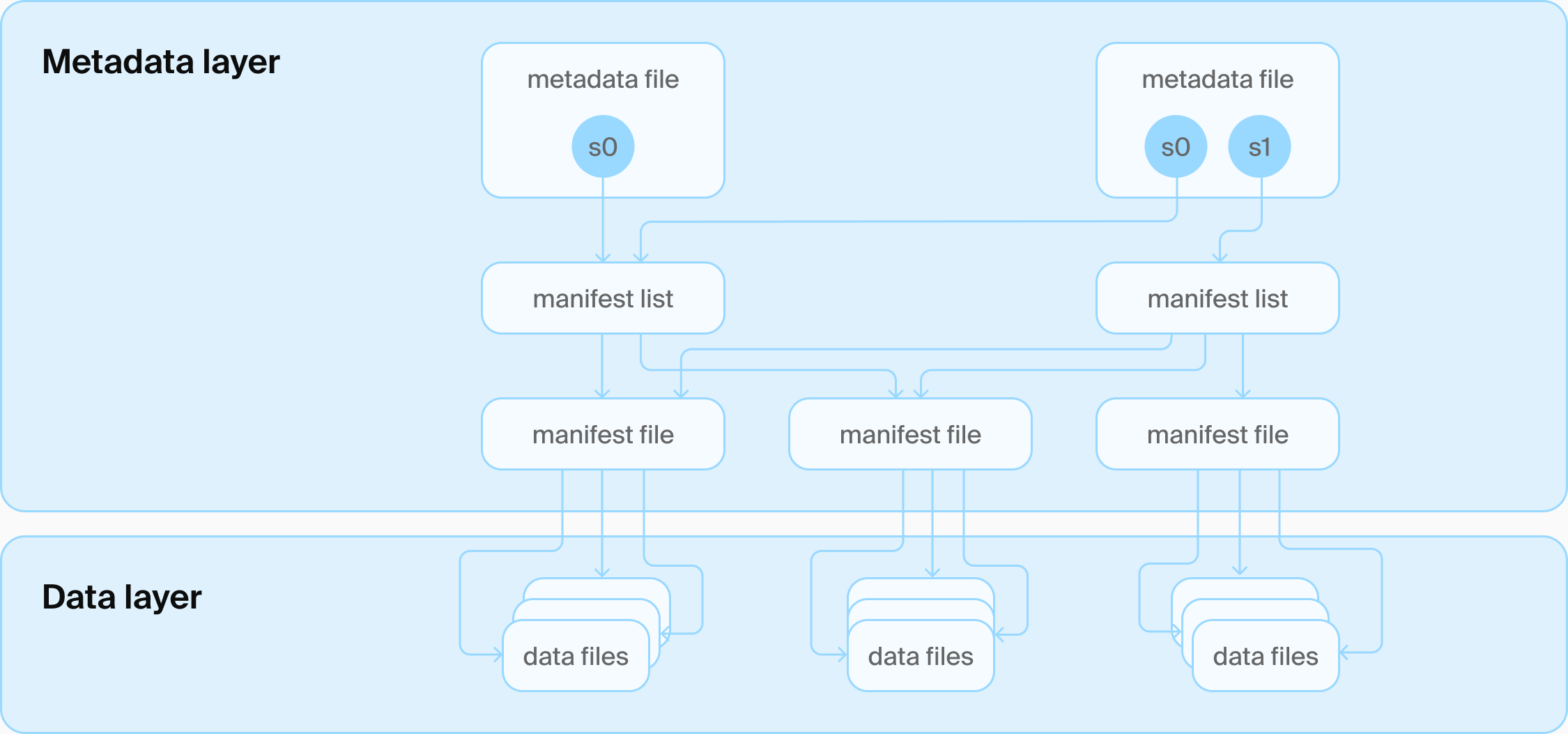
 Iceberg 表架构
Iceberg 表架构
但这两种格式都遇到了一个难题:在 Blob 存储中,由于其多变的一致性保证,查找表的最新版本非常棘手。原子地(ACID 中的“A”)交换指针以确保每个人都看到最新版本是很棘手的。Iceberg 和 Delta Lake 也只知道单个表,但人们——同样令人震惊的是——希望管理多个表。
目录
解决方案是另一层技术:我们在各种文件之上添加了一个目录服务。该目录服务反过来与一个数据库通信,该数据库管理所有表文件夹名称。它还管理着有史以来最悲伤的表,该表只为每个表包含一行,其中包含当前版本号。我们现在可以借用数据库在更新该数字方面的事务保证,这样每个人都会很高兴。
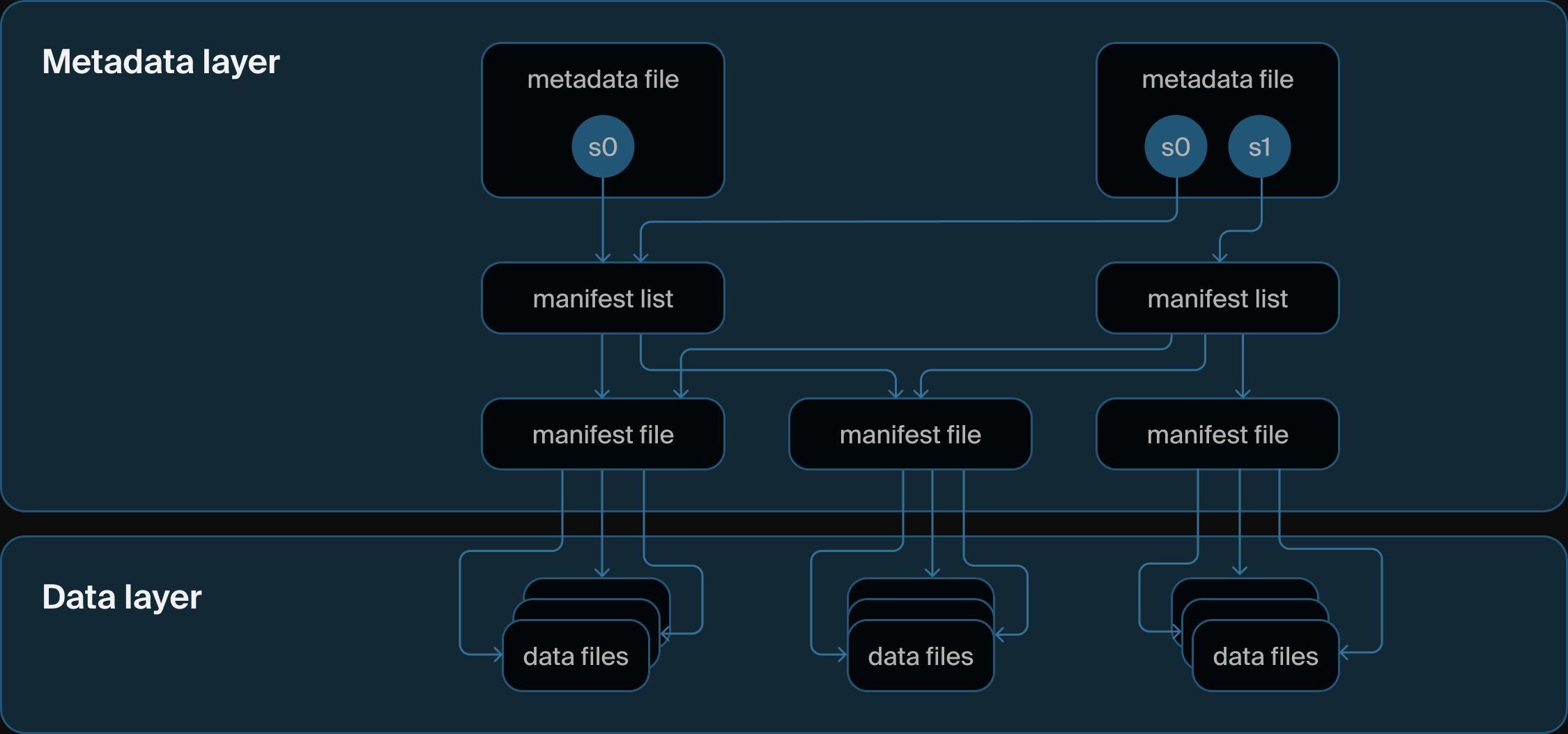
 Iceberg 目录架构
Iceberg 目录架构
你说,数据库?
但问题来了:Iceberg 和 Delta Lake 的设计初衷是不需要数据库。他们的设计者竭尽全力将高效读取和更新表所需的所有信息编码到 Blob 存储上的文件中。为了实现这一点,他们做出了许多妥协。例如,Iceberg 中的每个根文件都包含所有现有的快照,以及完整的模式信息等。对于每一次更改,都会写入一个新文件,其中包含完整的历史记录。许多其他元数据必须批量处理,例如在两层清单文件中,以避免写入或读取过多小文件,这在 Blob 存储上效率不高。对数据进行小幅更改也是一个基本未解决的问题,需要复杂的清理程序,而这些程序仍未被很好地理解,也未得到开源实现的支持。为解决这种管理快速变化数据的问题,整个公司都存在并仍在成立。这几乎就像某种专门的数据管理系统会是个好主意。
但如上所述,Iceberg 和 Delta Lake 的设计已经不得不妥协,并添加了一个数据库作为目录的一部分以实现一致性。然而,他们从未重新审视其余的设计约束和技术栈,以适应这种根本性的设计变更。
DuckLake
在 DuckDB,我们实际上喜欢数据库。它们是安全高效管理相当大规模数据集的绝佳工具。既然数据库已经进入湖仓一体堆栈,那么将其用于管理其余的表元数据就非常有意义了!我们仍然可以利用 Blob 存储“无尽”的容量和“无限”的可扩展性来存储 Parquet 等开放格式的实际表数据,但我们可以在数据库中更高效、更有效地管理支持更改所需的元数据!巧合的是,这也是 Google BigQuery(与 Spanner 配合)和 Snowflake(与 FoundationDB 配合)所选择的方案,只是它们底层没有开放格式。
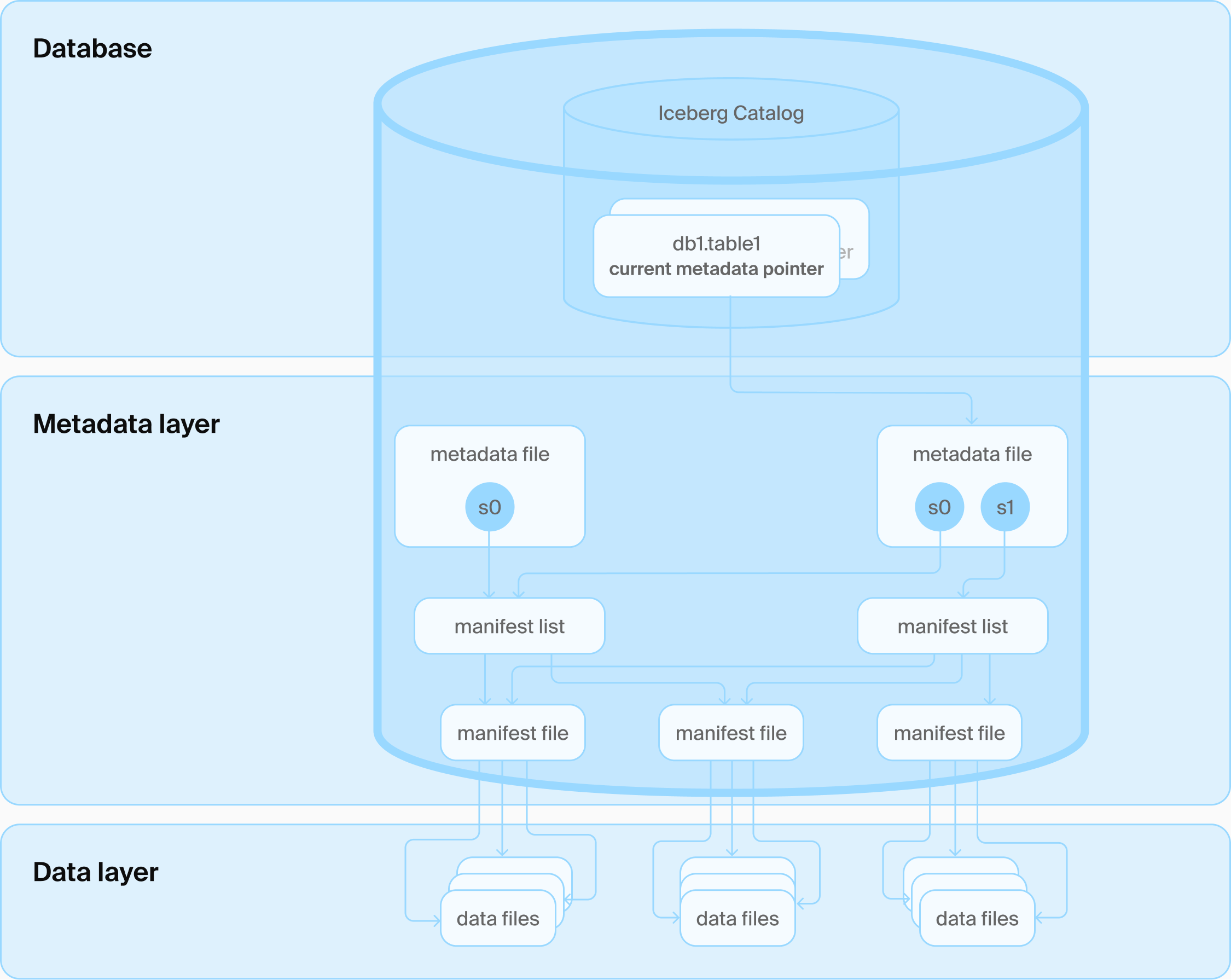
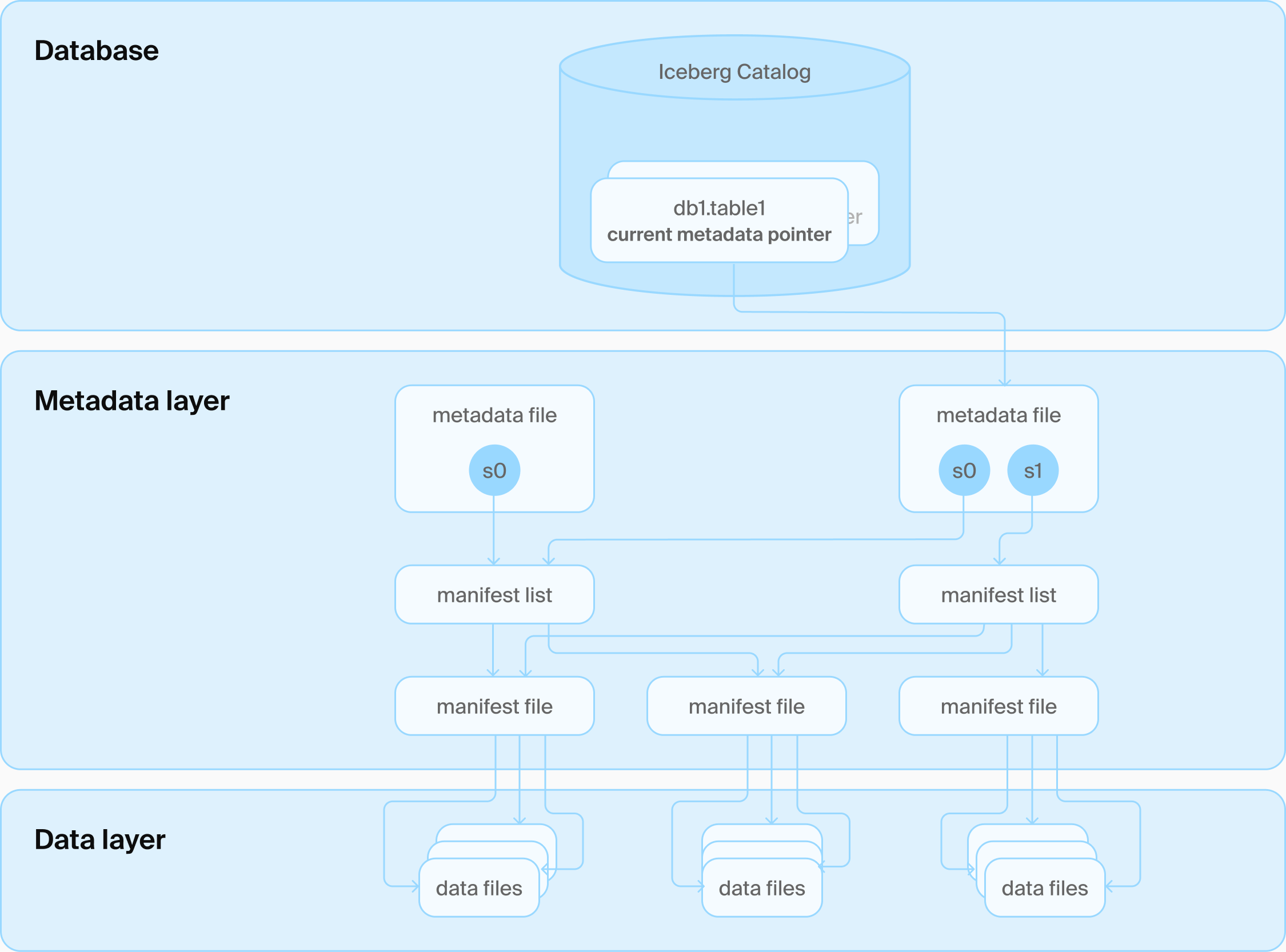
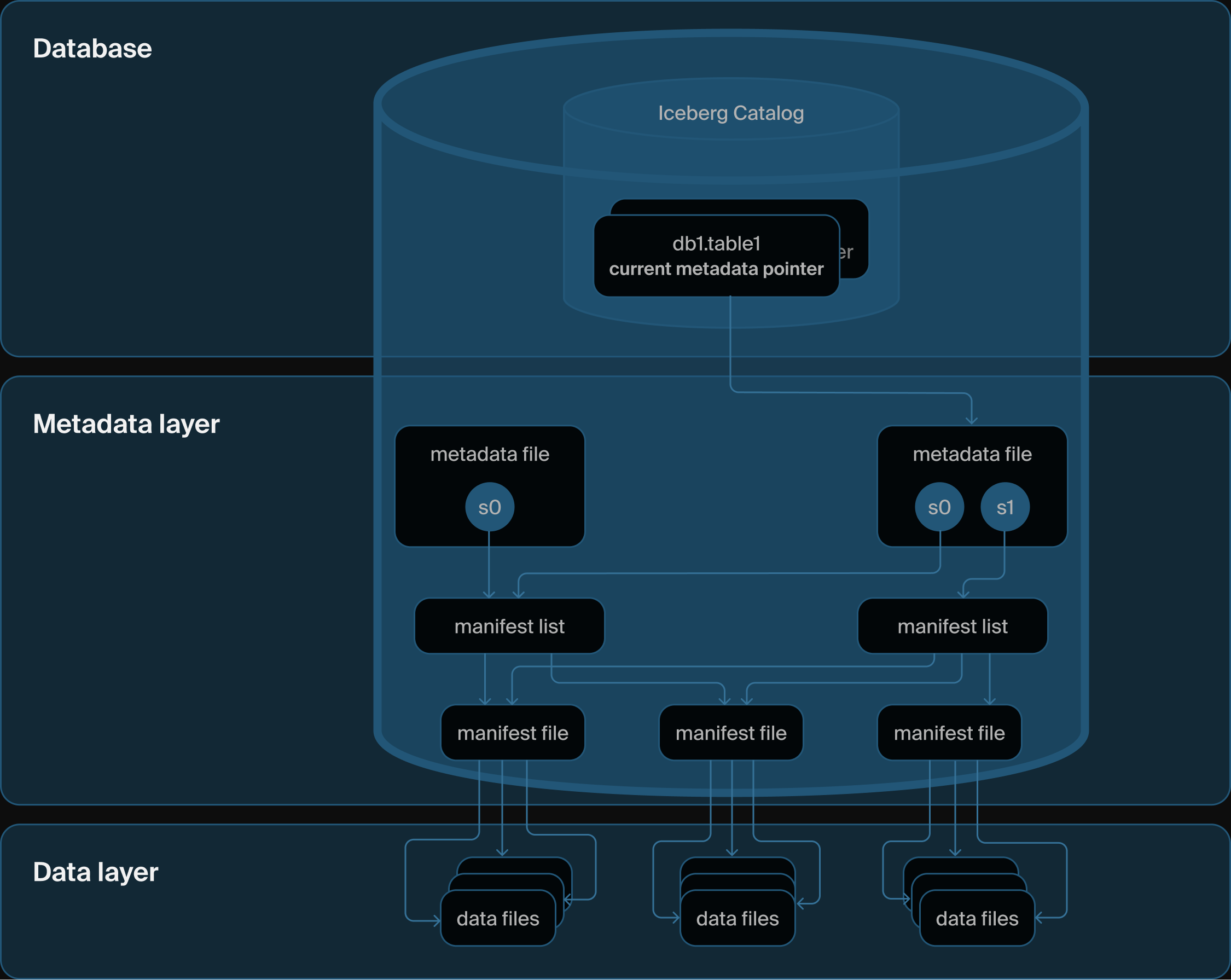 DuckLake 的架构:只有一个数据库和一些 Parquet 文件
DuckLake 的架构:只有一个数据库和一些 Parquet 文件
为了解决现有湖仓一体架构的根本问题,我们创建了一个名为 DuckLake 的新开放表格式。DuckLake 通过承认两个简单的真理,重新构想了“湖仓一体”格式应有的样子
- 在 Blob 存储上以开放格式存储数据文件是实现可扩展性和防止厂商锁定的绝佳主意。
- 管理元数据是一项复杂且相互关联的数据管理任务,最好交给数据库管理系统来完成。
DuckLake 的基本设计是将所有元数据结构移入 SQL 数据库,包括目录数据和表数据。该格式被定义为一组关系表及其上的纯 SQL 事务,这些事务描述了数据操作,如模式创建、修改,以及数据的添加、删除和更新。DuckLake 格式可以通过跨表事务管理任意数量的表。它还支持“高级”数据库概念,如视图、嵌套类型、事务性模式更改等;请参见下面的列表。这种设计的一个主要优点是,通过利用引用完整性(ACID 中的“C”),模式确保例如没有重复的快照 ID。
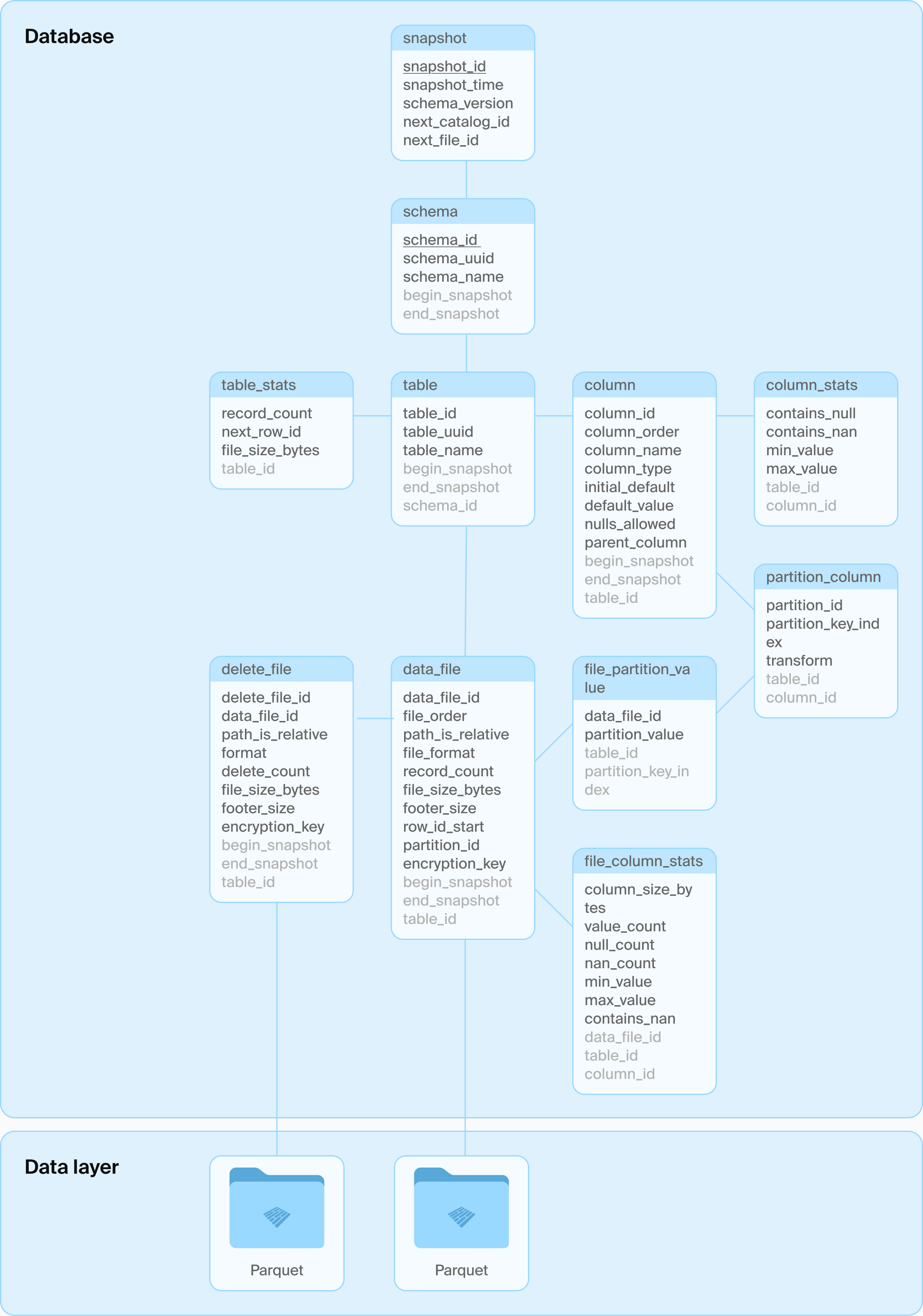
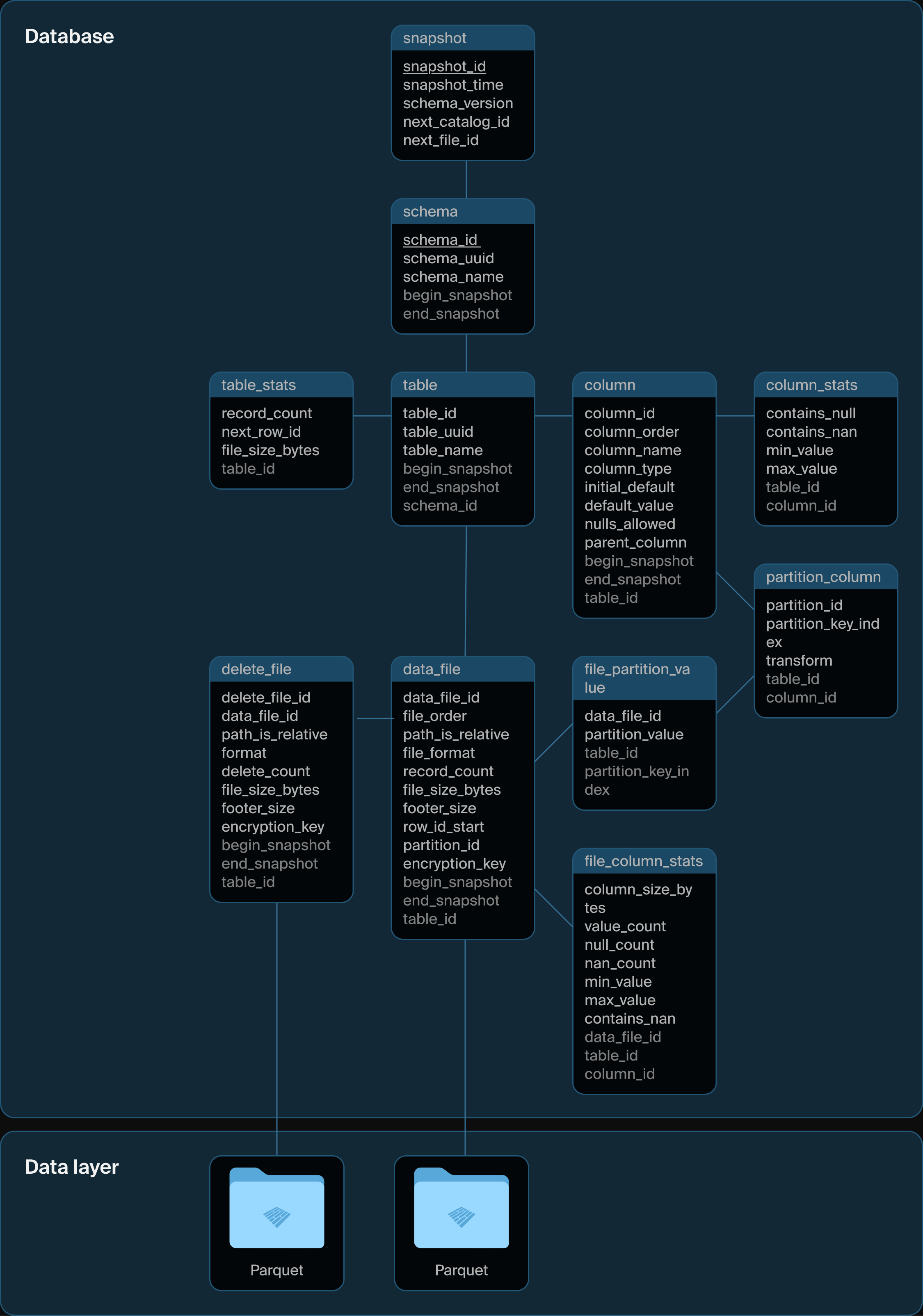 DuckLake 模式
DuckLake 模式
具体使用哪个 SQL 数据库由用户决定,唯一的要求是系统支持 ACID 操作和主键以及标准 SQL 支持。DuckLake 内部的表模式有意保持简单,以最大限度地兼容不同的 SQL 数据库。以下是核心模式的一个示例。
让我们来看看在新的空表上运行以下查询时,DuckLake 中发生的查询序列
INSERT INTO demo VALUES (42), (43);
BEGIN TRANSACTION;
-- some metadata reads skipped here
INSERT INTO ducklake_data_file VALUES (0, 1, 2, NULL, NULL, 'data_files/ducklake-8196...13a.parquet', 'parquet', 2, 279, 164, 0, NULL, NULL);
INSERT INTO ducklake_table_stats VALUES (1, 2, 2, 279);
INSERT INTO ducklake_table_column_stats VALUES (1, 1, false, NULL, '42', '43');
INSERT INTO ducklake_file_column_statistics VALUES (0, 1, 1, NULL, 2, 0, 56, '42', '43', NULL)
INSERT INTO ducklake_snapshot VALUES (2, now(), 1, 2, 1);
INSERT INTO ducklake_snapshot_changes VALUES (2, 'inserted_into_table:1');
COMMIT;
我们看到一个连贯的 SQL 事务,它
- 插入新的 Parquet 文件路径
- 更新全局表统计信息(现在行数更多)
- 更新全局列统计信息(现在具有不同的最小值和最大值)
- 更新文件列统计信息(还记录最小值/最大值等)
- 创建新的模式快照 (#2)
- 记录快照中发生的更改
请注意,实际写入 Parquet 的操作不属于此序列,它发生在此之前。但无论添加多少值,此序列的成本都是相同的(低)。
让我们讨论 DuckLake 的三大原则:简洁性、可扩展性和速度。
简洁性
DuckLake 遵循 DuckDB 的设计原则,即保持事物简单和渐进。要在笔记本电脑上运行 DuckLake,只需安装带有 ducklake 扩展 的 DuckDB 即可。这对于测试、开发和原型设计非常有用。在这种情况下,目录存储只是一个本地 DuckDB 文件。
下一步是利用外部存储系统。DuckLake 数据文件是不可变的,它从不需要原地修改文件或重用文件名。这使其几乎可以与任何存储系统一起使用。DuckLake 支持与本地磁盘、本地 NAS、S3、Azure Blob Store、GCS 等任何存储系统集成。数据文件的存储前缀(例如 s3://mybucket/mylake/)在创建元数据表时指定。
最后,托管目录服务器的 SQL 数据库可以是任何支持 ACID 和主键约束的、半能干的 SQL 数据库。大多数组织已经拥有丰富的此类系统操作经验。这极大地简化了部署,因为除了 SQL 数据库之外,不需要额外的软件堆栈。此外,近年来 SQL 数据库已大量商品化,有无数的托管 PostgreSQL 服务,甚至托管 DuckDB 可以用作目录存储!再次强调,这里的锁定非常有限,因为迁移不需要任何表数据移动,并且模式简单且标准化。
没有 Avro 或 JSON 文件。没有额外的目录服务器或额外的 API 可供集成。一切都只是 SQL。我们都懂 SQL。
可扩展性
DuckLake 实际上将数据架构中的关注点分离为三个部分:存储、计算和元数据管理。存储仍然是专门的文件存储(例如 Blob 存储),DuckLake 在存储方面可以无限扩展。
任意数量的计算节点正在查询和更新目录数据库,然后独立地从存储中读取和写入。DuckLake 在计算方面可以无限扩展。
最后,目录数据库需要能够只运行计算节点请求的元数据事务。它们的数量比实际数据更改小几个数量级。但 DuckLake 不受限于单个目录数据库,因此可以根据需求增长从 PostgreSQL 迁移到其他数据库。最终,DuckLake 使用简单的表和基本、可移植的 SQL。但别担心,一个由 PostgreSQL 支持的 DuckLake 已经能够扩展到数百 TB 和数千个计算节点。
同样,这正是 BigQuery 和 Snowflake 成功管理海量数据集的设计。而且,如果需要,没有什么能阻止你使用 Spanner 作为 DuckLake 的目录数据库。
速度
就像 DuckDB 本身一样,DuckLake 非常注重速度。Iceberg 和 Delta Lake 最大的痛点之一是运行最小查询所需的复杂文件 IO 序列。遵循目录和文件元数据路径需要许多独立的顺序 HTTP 请求。因此,读取或事务运行的速度存在下限。事务提交的关键路径上花费了大量时间,导致频繁冲突和昂贵的冲突解决。虽然可以使用缓存来缓解其中一些问题,但这增加了额外的复杂性,并且仅对“热”数据有效。
SQL 数据库中统一的元数据也允许低延迟的查询规划。为了从 DuckLake 表中读取数据,会向目录数据库发送一个查询,该查询执行基于模式、基于分区和基于统计信息的修剪,以基本检索要从 Blob 存储中读取的文件列表。没有多次往返存储以检索和重构元数据状态。出错的可能性也更小,没有 S3 节流,没有失败的请求,没有重试,没有存储上尚未一致导致文件不可见的情况等。
DuckLake 还能够改善数据湖的两个最大性能问题:小改动和大量并发改动。
对于小改动,DuckLake 将大幅减少写入存储的小文件数量。不会有与前一个快照相比只有微小改动的新快照文件,也不会有新的清单文件或清单列表。DuckLake 甚至可选地允许将对表的小改动透明地内联到元数据存储中的实际表中!事实证明,数据库系统也可以用来管理数据。这允许亚毫秒级的写入,并通过减少必须读取的文件数量来提高整体查询性能。通过写入更少的文件,DuckLake 还极大地简化了清理和压缩操作。
在 DuckLake 中,表更改包括两个步骤:将数据文件(如果有)暂存到存储,然后在目录数据库中运行单个 SQL 事务。这大大减少了事务提交关键路径中花费的时间,因为只需运行一个事务。SQL 数据库非常擅长解决事务冲突。这意味着计算节点在可能发生冲突的关键路径上花费的时间大大减少。这使得冲突解决速度更快,并允许更多并发事务。本质上,DuckLake 支持与目录数据库可以提交的表更改数量一样多的更改。即使是受人尊敬的 Postgres 也能每秒运行数千个事务。可以在一秒的间隔内运行一千个计算节点向一个表追加数据,并且它会运行良好。
此外,DuckLake 快照只是元数据存储中添加的几行,允许许多快照同时存在。无需主动修剪快照。快照还可以引用 Parquet 文件的部分,这使得存在的快照数量远多于磁盘上的文件数量。综合起来,这使得 DuckLake 能够管理数百万个快照!
功能
DuckLake 拥有所有你喜欢的湖仓一体功能
- 任意 SQL: DuckLake 支持与 DuckDB 支持的 SQL 功能一样广泛的功能。
- 数据更改: DuckLake 支持对数据进行高效的追加、更新和删除。
- 多模式,多表: DuckLake 可以在相同的元数据表结构中管理任意数量的模式,每个模式包含任意数量的表。
- 多表事务: DuckLake 支持对所有托管模式、表及其内容进行完全符合 ACID 标准的事务。
- 复杂类型: DuckLake 支持所有你喜欢的复杂类型,如列表,可任意嵌套。
- 完整模式演进: 表模式可以任意更改,例如,可以添加、删除列,或更改其数据类型。
- 模式级时间旅行和回滚: DuckLake 支持完整的快照隔离和时间旅行,允许查询特定时间点的表。
- 增量扫描: DuckLake 支持仅检索指定快照之间发生的更改。
- SQL 视图: DuckLake 支持定义惰性求值的 SQL 级视图。
- 隐藏分区和剪枝: DuckLake 了解数据分区以及表级和文件级统计信息,从而允许对扫描进行早期剪枝以实现最高效率。
- 事务性 DDL: 模式、表和视图的创建、演进和删除是完全事务性的。
- 数据压缩规避: DuckLake 所需的压缩操作远少于同类格式。DuckLake 支持高效的快照压缩。
- 内联: 当对数据进行少量更改时,DuckLake 可以选择使用目录数据库直接存储这些少量更改,以避免写入许多小文件。
- 加密: DuckLake 可以选择性地加密所有写入数据存储的数据文件,从而实现零信任数据托管。密钥由目录数据库管理。
- 兼容性: DuckLake 写入存储的数据文件和(位置)删除文件与 Apache Iceberg 完全兼容,从而允许仅元数据的迁移。
ducklake DuckDB 扩展
凭空指定数据格式很容易,但让它实际工作很难。这就是为什么今天我们还以 ducklake DuckDB 扩展的形式发布了一个 DuckLake 计算节点实现。该扩展实现了上述 DuckLake 格式并支持所有描述的功能。该扩展是 MIT 许可下的免费开源软件,所有 IP 归 非营利性 DuckDB 基金会 所有。
从概念上讲,ducklake 扩展将 DuckDB 从其单节点起点大幅提升,使其能够支持集中式客户端-服务器数据仓库用例,而无需额外的支持基础设施。通过 DuckLake,组织可以设置一个集中式目录数据库和文件存储(例如 AWS RDS 和 S3 或自托管),然后在大量参与设备(例如员工工作站、手机、应用服务器或无服务器计算代码)上运行带有 ducklake 扩展的 DuckDB 实例。
该扩展能够独立运行 DuckLake,使用本地 DuckDB 文件作为其目录数据库。它还可以使用 DuckDB 可以与之通信的任何第三方数据库。目前,这包括 PostgreSQL、SQLite、MySQL 和 MotherDuck 作为外部集中式目录数据库。该扩展可以使用 DuckDB 支持的任何文件系统,目前包括本地文件、S3、Azure Blob Store、GCS 等。
当然,DuckLake 扩展的可用性是增强而非取代 DuckDB 对 Iceberg 和 Delta 以及相关目录的现有和持续支持。DuckLake 也非常适合作为这些格式的本地缓存或加速功能。
DuckLake 从 DuckDB v1.3.0 版(代号“Ossivalis”)开始提供。
安装
- 步骤 1:安装 DuckDB
- 步骤 2:启动 DuckDB
- 步骤 3:输入
INSTALL ducklake;
清单完成。
用法
可以通过 DuckDB 中的 ATTACH 命令初始化 DuckLake。例如
ATTACH 'ducklake:metadata.ducklake' AS my_ducklake;
这将在 DuckDB 中创建一个新的附加数据库 metadata.ducklake,并将其别名为 my_ducklake。在这个完全本地的案例中,元数据表存储在 metadata.ducklake 文件中,而包含数据的 Parquet 文件存储在当前工作目录的 metadata.ducklake.files 文件夹中。当然,绝对路径也同样有效。
接下来我们创建一个表并插入一些数据
CREATE TABLE my_ducklake.demo (i INTEGER);
INSERT INTO my_ducklake.demo VALUES (42), (43);
你可以使用
USE命令切换默认数据库,例如USE my_ducklake。
让我们再次查询该表
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
│ 43 │
└───────┘
目前一切顺利。
FROM glob('metadata.ducklake.files/*');
┌───────────────────────────────────────────────────────────────────────────────┐
│ file │
│ varchar │
├───────────────────────────────────────────────────────────────────────────────┤
│ metadata.ducklake.files/ducklake-019711dd-6f55-7f41-ab99-6ac7d9de6ef3.parquet │
└───────────────────────────────────────────────────────────────────────────────┘
我们可以看到已经创建了一个包含两行的 Parquet 文件。现在,让我们再次删除一行
DELETE FROM my_ducklake.demo WHERE i = 43;
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
└───────┘
我们可以看到该行已消失。如果再次检查该文件夹,我们会看到一个新文件出现
FROM glob('metadata.ducklake.files/*');
┌──────────────────────────────────────────────────────────────────────────────────────┐
│ file │
│ varchar │
├──────────────────────────────────────────────────────────────────────────────────────┤
│ metadata.ducklake.files/ducklake-019711dd-6f55-7f41-ab99-6ac7d9de6ef3.parquet │
│ metadata.ducklake.files/ducklake-019711e0-16f7-7261-9d08-563a48529955-delete.parquet │
└──────────────────────────────────────────────────────────────────────────────────────┘
出现了第二个文件名中带有 -delete 的文件,这也是一个 Parquet 文件,其中包含被删除行的标识符。
当然,DuckLake 支持时间旅行,我们可以使用 ducklake_snapshots() 函数查询可用的快照。
FROM ducklake_snapshots('my_ducklake');
┌─────────────┬────────────────────────────┬────────────────┬──────────────────────────────┐
│ snapshot_id │ snapshot_time │ schema_version │ changes │
│ int64 │ timestamp with time zone │ int64 │ map(varchar, varchar[]) │
├─────────────┼────────────────────────────┼────────────────┼──────────────────────────────┤
│ 0 │ 2025-05-27 15:10:04.953+02 │ 0 │ {schemas_created=[main]} │
│ 1 │ 2025-05-27 15:10:14.079+02 │ 1 │ {tables_created=[main.demo]} │
│ 2 │ 2025-05-27 15:10:14.092+02 │ 1 │ {tables_inserted_into=[1]} │
│ 3 │ 2025-05-27 15:13:08.08+02 │ 1 │ {tables_deleted_from=[1]} │
└─────────────┴────────────────────────────┴────────────────┴──────────────────────────────┘
假设我们想读取包含 43 的行被删除之前的表,我们可以使用 DuckDB 中新的 AT 语法
FROM my_ducklake.demo AT (VERSION => 2);
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
│ 43 │
└───────┘
版本 2 仍然包含这一行,所以它在这里。这也适用于快照时间戳而非版本号:只需使用 TIMESTAMP 而非 VERSION。
我们还可以使用 ducklake_table_changes() 函数查看版本之间的变化,例如
FROM ducklake_table_changes('my_ducklake', 'main', 'demo', 2, 3);
┌─────────────┬───────┬─────────────┬───────┐
│ snapshot_id │ rowid │ change_type │ i │
│ int64 │ int64 │ varchar │ int32 │
├─────────────┼───────┼─────────────┼───────┤
│ 2 │ 0 │ insert │ 42 │
│ 2 │ 1 │ insert │ 43 │
│ 3 │ 1 │ delete │ 43 │
└─────────────┴───────┴─────────────┴───────┘
我们可以看到在版本二中,我们在快照 2 中添加了值 42 和 43,然后在快照 3 中再次删除了 43。
DuckLake 中的更改当然是事务性的,之前我们运行在“自动提交”模式下,每个命令都是其自身的事务。但是我们可以使用 BEGIN TRANSACTION 和 COMMIT 或 ROLLBACK 来改变这一点。
BEGIN TRANSACTION;
DELETE FROM my_ducklake.demo;
FROM my_ducklake.demo;
┌────────┐
│ i │
│ int32 │
├────────┤
│ 0 rows │
└────────┘
ROLLBACK;
FROM my_ducklake.demo;
┌───────┐
│ i │
│ int32 │
├───────┤
│ 42 │
└───────┘
在这里,我们开始一个事务,然后从 my_table 中删除所有行,该表随后确实显示为空。然而,由于我们随后进行了 ROLLBACK,未提交的删除操作被撤销了。
总结:在这篇文章中,我们介绍了基于纯 SQL 构建的新湖仓一体格式的原理和设计。如果你想使用一种简单、可扩展、快速的湖仓一体格式来处理数据,不妨一试!我们期待看到你的用例!
ducklake扩展目前仍处于实验阶段。如果你遇到任何错误,请在ducklake扩展仓库 中提交问题。
媒体咨询
如需媒体咨询,请联系 Gabor Szarnyas。

