插入时排序以实现快速选择性查询

TL;DR: 在加载数据时进行排序可以使选择性读取查询的速度提高一个数量级,这得益于DuckDB的自动最小-最大索引(也称为区域图)。这种方法也适用于大多数列式文件格式和数据库。本文将剖析DuckDB文件结构作为列式数据格式的示例,并提供关于如何使用排序来提高查询速度的实用建议。
读取数据的最快方式是不要读取数据。就这么简单!本文的重点是如何尽可能少地读取数据来响应选择性读取查询。
欢迎直接跳至最佳实践!
用例
这些技术最有用的场景是读取性能比写入性能更关键时。在这种情况下,我们可以有意识地添加排序步骤,这会减慢写入速度,但会极大地加快读取速度。这通常发生在数据在后台进行预处理,而读取查询则面向客户的仪表板或应用程序中。
在以下任何情况下,使用排序都将有所帮助
- 您的数据集很大,无法完全载入内存
- 您只想为每个查询读取数据集的一部分
- 您通过 HTTP(S) 访问数据
- 您的数据存储在云端的对象存储中,例如 AWS S3
本概述描述了DuckDB文件格式,但由于DuckDB的部分读取支持,这些技术通常可以应用于几乎任何列式文件格式或数据库。这是加速在远程端点(包括数据湖)上查询Apache Parquet文件的好方法!
敬请关注后续文章,该文章将涵盖高级多列排序!
DuckDB 格式如何提供帮助?
让我们对DuckDB文件格式的结构建立一些直观的认识!DuckDB将数据存储在一个文件中。每个文件都被称为数据库(DuckDB库是数据库引擎)。
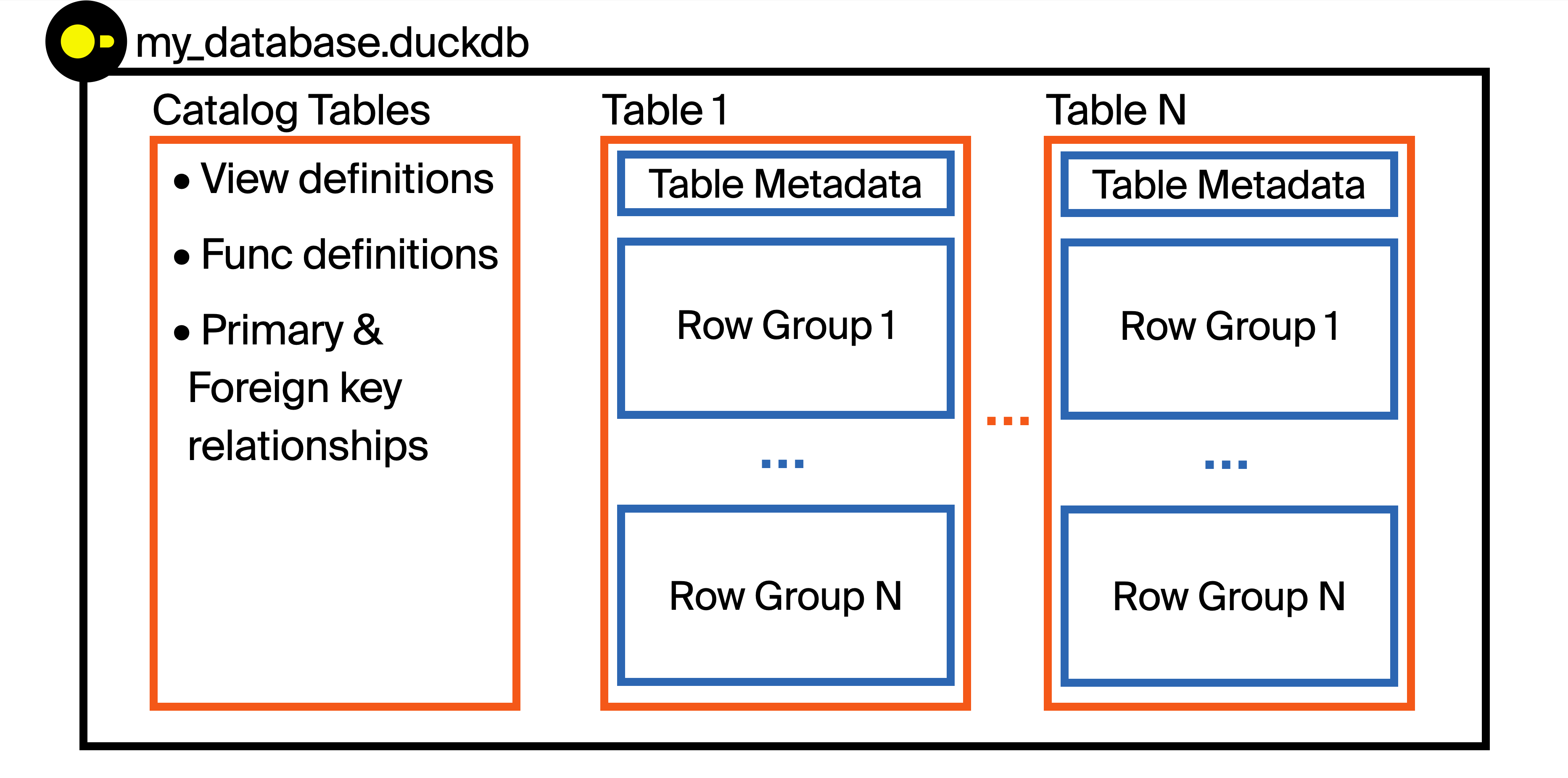
每个数据库文件都可以在同一个文件中存储多个表、视图、函数、索引以及主键/外键关系。这为可移植性带来了一些关键优势,但它也允许存储不仅仅是数据——元数据也可以存储。这些元数据允许DuckDB引擎根据请求选择性地只读取DuckDB文件的部分内容,这对于处理大于内存的数据集以及本文中的性能优化至关重要!
DuckDB以列式方式存储数据(这意味着列中的值存储在同一组块中)。然而,列式并不意味着将整个列连续存储!在存储数据之前,DuckDB将表分解为称为行组的行块。每个行组默认为 122,880 行。
接下来,我们放大第一张图中的Table 1里的Row Group 1
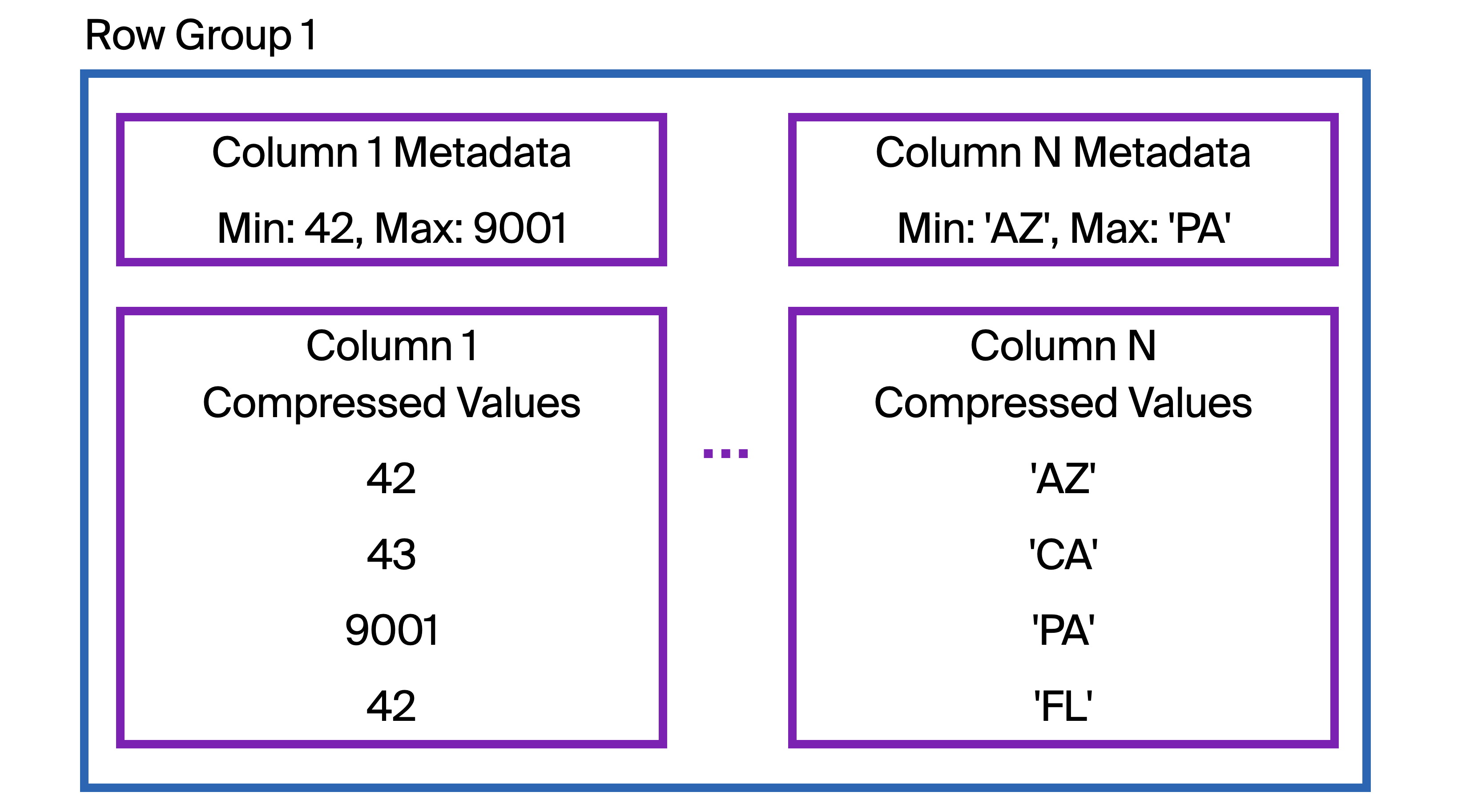
在每个行组中,与单个列相关的数据以一个或多个块的形式连续存储在磁盘上。DuckDB会压缩这些数据以减小文件大小。
使用区域图跳过数据读取
那么,将数据存储在列中有助于选择性读取查询吗?仅凭这一点,它并不能!然而,在每个行组中存储的列数据开始处,DuckDB还会存储有关所存储列数据的元数据。这包括该列在该行组内的最小值和最大值。我们称这些为区域图或最小-最大索引。
当DuckDB收到包含过滤条件的SQL查询时,在从磁盘读取列段之前,它会首先检查元数据。这个过滤值是否可能落在此列段的最小/最大范围内?如果不可能,那么DuckDB就可以跳过读取该整个行组中的数据。
例如,本例中的Column N存储的是美国各州的缩写。如果我们查询州VA(弗吉尼亚州)的数据,这个行组是否可能包含VA的任何数据?我们的查询可能是
FROM "Table 1"
WHERE "Column N" = 'VA';
DuckDB的友好型SQL使得传统的SQL
SELECT *成为可选!
DuckDB首先检查区域图(在图中标记为Column N Metadata)。VA是否落在AZ到PA的(按字母顺序)范围内?不,它不在!我们可以跳过整个行组。
如果我们将过滤条件设为NM(新墨西哥州),则区域图表明该行组中可能存在NM数据。因此,DuckDB将检索整个列的数据(可能来自远程位置),并检查每一行以查看是否存在任何NM数据。根据图示,此行组中没有NM数据,因此检索它并逐行检查匹配项将是不必要的开销。所有 122,880 行都需要检查!要是区域图索引没有覆盖这么大范围的州缩写就好了……
策略性地跳过数据
我们的目标是排序数据,使区域图对于我们感兴趣的过滤列尽可能具有选择性。如果该行组的最小-最大索引只从AZ延伸到CA,那么数据被跳过的可能性就会大得多。换句话说,我们想要检索的每个数据子集应该只存储在少数几个行组中。我们不希望拉取每个行组并检查每一行!例如,希望按字母顺序靠前的州都分组在同一个行组中。
在执行选择性查询时,您可以目标是只拉取一个行组!然而,由于DuckDB的多线程模型是基于行组的,只要行组的数量少于DuckDB正在使用的线程数(≈CPU核心数),您应该仍然能看到高性能。
排序最佳实践
关于如何最好地利用最小-最大索引,有许多经验法则,因为它们的有效性高度依赖于数据和工作负载。这些在DuckDB以及其他列式格式(如Apache Parquet)或其他列式数据库中都很有用。以下是几种值得考虑的方法!
在决定对哪些列进行排序时,检查任何读取工作负载的WHERE子句至关重要。通常最重要的因素是哪些列最常用于过滤。一个基本的方法是按照所有用作过滤条件的列进行排序,从最常用的列开始。
如果工作负载涉及通过多个不同列进行过滤,另一种选择是首先考虑按基数最低(唯一值最少)的列进行排序。例如,在按唯一的customer_id排序之前,先按范围较广的customer_type排序可能会有所帮助。
通常只读取最新数据很有用,因此确保最新数据不分散在整个表中可以提高性能。然而,在按时间戳排序时,请注意时间戳通常具有非常高的基数。因此,首先按基数较低的列进行排序可能会有所帮助。您可能会很想先按时间戳排序——请抵制这种诱惑!(或者至少尝试其他替代方案)。按四舍五入到最近的周、月或年的时间戳,然后按其他列进行排序可能更有益。
为了受益于最小-最大索引,
WHERE子句必须直接过滤特定列,而不是计算表达式。如果使用表达式,则必须对每一行进行评估,因此无法跳过任何行组!
其他技术
还有更多方法可以充分利用DuckDB中的最小-最大索引!
避免小批量插入
如果工作负载以小批量或一次一行的方式插入数据,那么在插入时没有机会有效地对数据进行排序。相反,数据将主要按插入时间排序,这只能为基于时间的过滤器提供有效的剪枝。如果可能,批量插入或批处理将使排序对其他列更有效。作为替代方案,可以有一个定期的重新排序任务,这类似于事务系统中的重新索引任务。
分块排序
排序对于大型表来说可能是一个计算成本高昂的操作。减少排序所需内存量(或磁盘溢出)的一种方法是分块处理表,通过循环执行多个SQL语句,每个语句都过滤到特定的数据块。由于SQL没有循环结构,这需要通过宿主语言(Python、Jinja模板等)来处理。伪代码如下:
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
WITH NO DATA;
for chunk in chunks:
INSERT INTO sorted_table
FROM unsorted_table
WHERE chunking_column = chunk
ORDER BY other_columns...;
这将产生先按分块列排序,然后按other_columns排序的效果。运行时间也可能更长(因为数据必须对每个块扫描一次),但内存使用量可能会大大降低。
对字符串的前几个字符进行排序
近似排序对于提高读取性能效果很好。在VARCHAR列的区域图中,DuckDB只存储字符串最小值和最大值的前8个字节。因此,没有必要对超过前8个字节(8个ASCII字符)的内容进行排序!
这还有一个额外的好处是排序更快,因为DuckDB的基数排序算法的运行时间对字符串长度很敏感(这是设计使然!)。该算法的时间复杂度为O(nk),其中n是行数,k是排序键的宽度。只对VARCHAR的前几个字符进行排序可以更快,计算强度更低,同时获得相似的读取性能。DuckDB的VARCHAR数据类型在字符串小于12字节时也会内联字符串,因此处理短字符串也更快。例如
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
ORDER BY varchar_column_to_sort[:8];
DuckDB的友好型SQL允许使用方括号表示法进行字符串切片!
按更多列过滤
如果被过滤的列具有某种近似顺序,则向WHERE子句添加过滤器可能会有所帮助。例如,如果表已按customer_type排序,则除了按customer_id过滤外,还在查询中包含该列。通常,如果在查询时已知customer_id,也可能知道其他元数据。
调整行组大小
针对特定工作负载可以调整的一个参数是行组中的行数(即ROW_GROUP_SIZE)。如果被过滤的列中存在许多唯一值,那么每个行组的行数较少可以减少必须扫描的总行数。然而,当行组较小时,更频繁地检查元数据会带来开销,因此存在一个权衡。
如果表特别大且查询选择性非常高,那么较大的行组大小实际上可能更受欢迎。例如,如果查询一个包含多年历史的大型事实表,但只过滤最近一周的数据。较大的行组大小减少了访问最新数据所需的元数据检查次数。然而,每个行组也更大,因此在那里也存在一个权衡。
要调整行组大小,请在附加数据库时传入一个参数。请注意,行组大小应为2的幂。最小行组大小为 2,048,即DuckDB的向量大小。
ATTACH './smaller_row_groups.duckdb' (ROW_GROUP_SIZE 8192);
系列下一篇文章的预告
本系列的后续文章将涵盖高级排序技术。如果具有不同过滤条件的多个读取器工作负载正在查询相同数据集,这些技术可以提高性能。例如,如果某些查询需要按美国州过滤,而另一些需要按客户姓氏过滤,该怎么办?此外,当只需要最新数据时,按四舍五入的时间桶(日、月或年)然后按其他列进行排序可能会很有帮助。
微基准测试将展示本文开头提到的10倍性能提升!文章还将提供衡量表在各种列上排序效率的方法。
结论
在插入时对数据进行排序可以显著加快包含过滤条件的读取查询的速度。一旦您的数据集变大或远程存储时,请考虑应用这些技术。此外,这些方法几乎可以用于任何列式文件格式或数据库!
祝您分析愉快!

