DuckDB 中使用流式窗口函数的时序分析
概要:DuckDB 可以使用具有不同语义的窗口(例如,滚动窗口、跳跃窗口和滑动窗口)执行基于时间的分析。 在这篇文章中,我们将通过检测阿姆斯特丹中央车站的铁路服务趋势和异常来演示这些功能。
介绍
在数据平台中,我们通常将数据分为维度数据和事实数据。 维度包含有关实体的信息(名称、地址、序列号等),而事实包含与这些实体相关的事件(点击、销售、银行交易、来自物联网设备的读数等)。 一般来说,事实数据包括一个时间戳属性,表示事件发生(或被观察到)的时刻。
当时间戳数据在流平台处理时,通常会使用流式窗口函数将其组织成时间窗口。 在这篇文章中,我们将展示如何在 DuckDB 中对静态时间戳事实数据应用流式窗口,作为数据分析任务的一部分,以计算阿姆斯特丹中央车站的列车服务摘要、趋势和中断。
在以后的文章中,我们将介绍 DuckDB 的流式设计模式。
对于当前的实现,我们将使用 dbt 项目中创建的 DuckDB 数据库,该项目在文章 “使用 dbt 和 DuckDB 进行完全本地数据转换” 中详细介绍,该项目基于 Rijden de Treinen (火车正在运行吗?) 应用程序的开放数据。 我们首先(在任何 DuckDB 会话中)附加来自我们存储位置的数据库。
ATTACH 'http://blobs.duckdb.org/data/dutch_railway_network.duckdb';
USE dutch_railway_network.main_main;
警告 该数据库相当大(约 1.2 GB),因此请确保具有稳定的互联网连接。 您也可以 下载数据库文件 并从命令行连接到它,而不是附加数据库。
duckdb dutch_railway_network.duckdb -cmd 'USE main_main'
滚动窗口
滚动窗口 是固定大小的 [左闭右开) 时间间隔,用于计算特定时间单位级别(年、日、小时等)的摘要。 滚动窗口也用于通过以规则的时间间隔聚合(不规则)事实数据,将其转换为时间序列数据。
实现滚动窗口的一种方法是使用 date_trunc 函数,它会将时间戳截断到指定的精度。 例如,在下面,我们检索 2024 年每小时和每天的服务数量
SELECT
date_trunc('hour', station_service_time) AS window_start,
window_start + INTERVAL 1 HOUR AS window_end,
count(*) AS number_of_services
FROM ams_traffic_v
WHERE year(station_service_time) = 2024
GROUP BY ALL
ORDER BY 1;
┌─────────────────────┬─────────────────────┬────────────────────┐
│ window_start │ window_end │ number_of_services │
│ timestamp │ timestamp │ int64 │
├─────────────────────┼─────────────────────┼────────────────────┤
│ 2024-01-01 01:00:00 │ 2024-01-01 02:00:00 │ 2 │
│ 2024-01-01 02:00:00 │ 2024-01-01 03:00:00 │ 3 │
│ 2024-01-01 03:00:00 │ 2024-01-01 04:00:00 │ 4 │
│ · │ · │ · │
│ · │ · │ · │
│ · │ · │ · │
│ 2024-12-31 20:00:00 │ 2024-12-31 21:00:00 │ 9 │
│ 2024-12-31 21:00:00 │ 2024-12-31 22:00:00 │ 1 │
│ 2024-12-31 23:00:00 │ 2025-01-01 00:00:00 │ 2 │
├─────────────────────┴─────────────────────┴────────────────────┤
│ 8781 rows (6 shown) 3 columns │
└────────────────────────────────────────────────────────────────┘
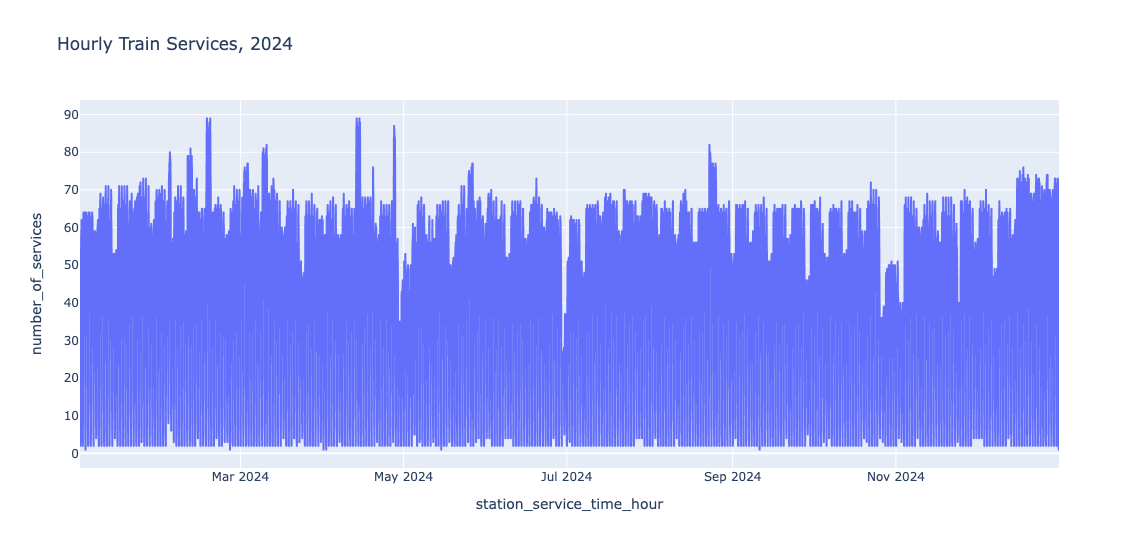
另一种方法是使用 time_bucket 函数,它会将时间戳截断到提供的桶宽度,从指定的偏移量开始。 例如,我们计算每隔一刻钟的服务数量,从 00 开始
SELECT
time_bucket(
INTERVAL 15 MINUTE, -- bucket width
station_service_time,
INTERVAL 0 MINUTE -- offset
) AS window_start,
window_start + INTERVAL 15 MINUTE as window_end,
count(*) AS number_of_services
FROM ams_traffic_v
WHERE year(station_service_time) = 2024
GROUP BY ALL
ORDER BY 1;
┌─────────────────────┬─────────────────────┬────────────────────┐
│ window_start │ window_end │ number_of_services │
│ timestamp │ timestamp │ int64 │
├─────────────────────┼─────────────────────┼────────────────────┤
│ 2024-01-01 01:30:00 │ 2024-01-01 01:45:00 │ 1 │
│ 2024-01-01 01:45:00 │ 2024-01-01 02:00:00 │ 1 │
│ 2024-01-01 02:15:00 │ 2024-01-01 02:30:00 │ 2 │
│ · │ · │ · │
│ · │ · │ · │
│ · │ · │ · │
│ 2024-12-31 20:45:00 │ 2024-12-31 21:00:00 │ 2 │
│ 2024-12-31 21:00:00 │ 2024-12-31 21:15:00 │ 1 │
│ 2024-12-31 23:45:00 │ 2025-01-01 00:00:00 │ 2 │
├─────────────────────┴─────────────────────┴────────────────────┤
│ 32932 rows (6 shown) 3 columns │
└────────────────────────────────────────────────────────────────┘
时间桶函数从时间戳列本身生成桶,时间序列数据中可能存在空白。 如上面的结果所示,第一个记录是
2024-01-01 01:30:00,因为在该时间戳之前没有记录。
鉴于滚动窗口是非重叠的时间间隔,我们可以计算摘要,例如 15 分钟间隔内的平均服务数量。 有趣的是,火车服务数量在白天相当稳定,但在夜间则低得多——即使在阿姆斯特丹也是如此。
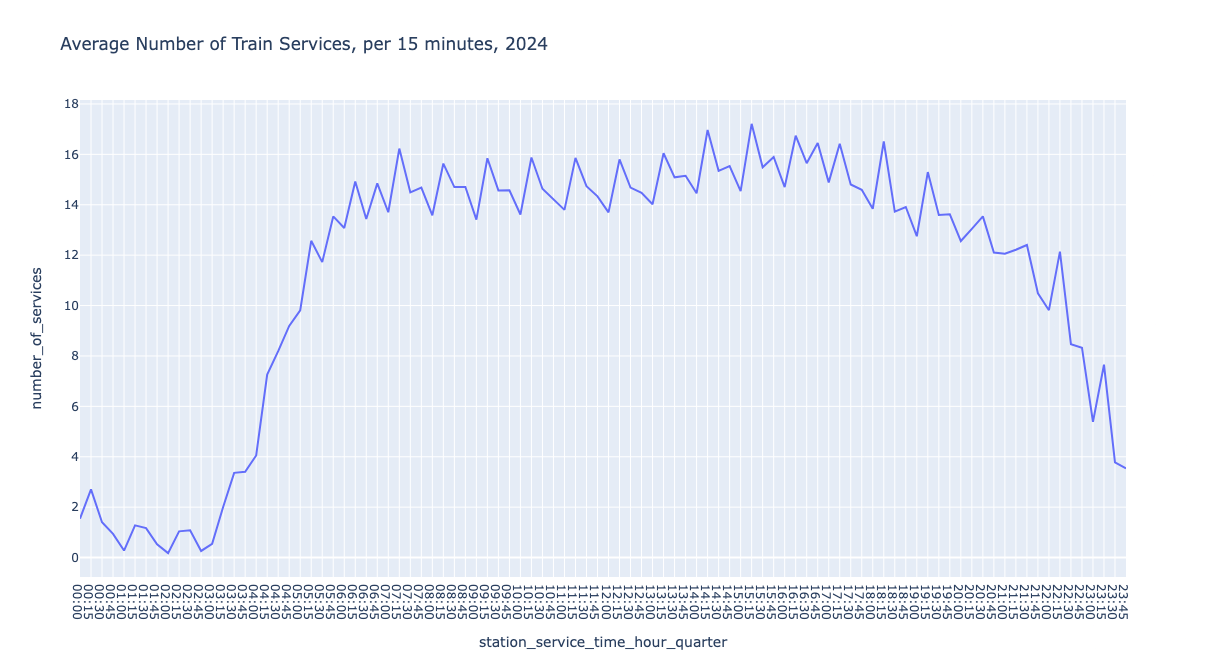
跳跃窗口
跳跃窗口 是固定大小的时间间隔,但与滚动窗口相反,它们是重叠的。 跳跃窗口由以下内容定义
- 窗口开始时间之间应经过多长时间,称为跳跃大小;
- 一个窗口应包含多长时间,称为窗口大小。
跳跃窗口的一个用例是识别 2024 年中最繁忙的五个 15 分钟周期(窗口大小),每 5 分钟(跳跃大小)开始一次。 我们首先为我们感兴趣的所有日期生成人工跳跃窗口
WITH time_range AS (
SELECT
range AS window_start,
window_start + INTERVAL 15 MINUTE AS window_end
FROM range(
'2024-01-01 00:00:00'::TIMESTAMP,
'2025-01-01 00:00:00'::TIMESTAMP,
INTERVAL 5 MINUTE -- hopping size
)
)
┌─────────────────────┬─────────────────────┐
│ window_start │ window_end │
│ timestamp │ timestamp │
├─────────────────────┼─────────────────────┤
│ 2024-01-01 00:00:00 │ 2024-01-01 00:15:00 │
│ 2024-01-01 00:05:00 │ 2024-01-01 00:20:00 │
│ 2024-01-01 00:10:00 │ 2024-01-01 00:25:00 │
│ · │ · │
│ · │ · │
│ · │ · │
│ 2024-12-31 23:45:00 │ 2025-01-01 00:00:00 │
│ 2024-12-31 23:50:00 │ 2025-01-01 00:05:00 │
│ 2024-12-31 23:55:00 │ 2025-01-01 00:10:00 │
├─────────────────────┴─────────────────────┤
│ 105408 rows (6 shown) 2 columns │
└───────────────────────────────────────────┘
然后,我们将上述时间间隔与列车服务数据连接,以便计算每个 [左闭右开) 时间间隔的服务数量
SELECT
window_start,
window_end,
count(service_sk) AS number_of_services
FROM ams_traffic_v
INNER JOIN time_range AS ts
ON station_service_time >= ts.window_start
AND station_service_time < ts.window_end
GROUP BY ALL
ORDER BY 3 DESC, 1 ASC
LIMIT 5;
导致
┌─────────────────────┬─────────────────────┬────────────────────┐
│ window_start │ window_end │ number_of_services │
│ timestamp │ timestamp │ int64 │
├─────────────────────┼─────────────────────┼────────────────────┤
│ 2024-02-17 10:25:00 │ 2024-02-17 10:40:00 │ 28 │
│ 2024-02-17 11:25:00 │ 2024-02-17 11:40:00 │ 28 │
│ 2024-02-17 16:25:00 │ 2024-02-17 16:40:00 │ 28 │
│ 2024-02-17 09:25:00 │ 2024-02-17 09:40:00 │ 27 │
│ 2024-02-17 12:25:00 │ 2024-02-17 12:40:00 │ 27 │
└─────────────────────┴─────────────────────┴────────────────────┘
你能想象在控制室里,15 分钟内有 28 趟列车到达或离开一个有 15 条轨道的车站是什么样子吗?
通过在上面的查询中应用
RIGHT OUTER JOIN,空白处将填充 0 个服务。
滑动窗口
滑动窗口 是重叠的时间间隔,但与跳跃窗口相比,它们是从分析的时间列动态生成的,因此在插入新记录时会发生变化。 可以使用 RANGE 窗口框架来实现滑动窗口
SELECT
station_service_time - INTERVAL 15 MINUTE AS window_start, -- window size
station_service_time AS window_end,
count(service_sk) OVER (
ORDER BY station_service_time
RANGE
BETWEEN INTERVAL 15 MINUTE PRECEDING -- window size
AND CURRENT ROW
) AS number_of_services
FROM ams_traffic_v
ORDER BY 3 DESC, 1
LIMIT 5;
┌─────────────────────┬─────────────────────┬────────────────────┐
│ window_start │ window_end │ number_of_services │
│ timestamp │ timestamp │ int64 │
├─────────────────────┼─────────────────────┼────────────────────┤
│ 2024-02-17 11:25:00 │ 2024-02-17 11:40:00 │ 29 │
│ 2024-02-17 10:24:00 │ 2024-02-17 10:39:00 │ 28 │
│ 2024-02-17 11:18:00 │ 2024-02-17 11:33:00 │ 28 │
│ 2024-02-17 11:18:00 │ 2024-02-17 11:33:00 │ 28 │
│ 2024-02-17 11:23:00 │ 2024-02-17 11:38:00 │ 28 │
└─────────────────────┴─────────────────────┴────────────────────┘
由于当前行包含在计算中,因此滑动窗口是 [左闭右闭]。
会话窗口
会话窗口 将在时间上紧密发生的事件分组在一起,并以不活动间隔分隔。 当两个事件之间的时间超过定义的超时时间时,将开始一个新的会话。 会话窗口最常见的用例是检测时间戳数据中的空白。
我们继续数据分析,方法是识别哪些天数中有大于 10 分钟的时间段,在此期间,没有火车到达/离开阿姆斯特丹中央车站。 在这种情况下,会话窗口是在列车服务运行期间没有超过 10 分钟的服务不活动间隔的时间段。
我们首先使用 lag 窗口函数计算每个记录的上一次服务时间。 我们在上面观察到夜间几乎没有交通,因此我们仅包括早上 6 点到晚上 11 点之间的服务
SELECT
service_sk,
station_service_time,
lag(station_service_time) OVER (
PARTITION BY station_service_time::DATE
ORDER BY station_service_time
) AS previous_service_time,
date_diff('minute', previous_service_time, station_service_time) AS gap_minutes
FROM ams_traffic_v
WHERE hour(station_service_time) BETWEEN 6 AND 23
在上面的查询中,我们还使用 date_diff 计算当前服务与上一次服务之间的间隔(以分钟为单位)。 如果没有上一次服务,则该列将为 NULL,表示当天第一个服务会话
┌──────────────────────┬───────────────────────┬─────────────┐
│ station_service_time │ previous_service_time │ gap_minutes │
│ timestamp │ timestamp │ int64 │
├──────────────────────┼───────────────────────┼─────────────┤
│ 2024-01-09 06:00:00 │ NULL │ NULL │
│ 2024-01-16 06:00:00 │ NULL │ NULL │
│ 2024-01-22 06:00:00 │ NULL │ NULL │
│ · │ · │ · │
│ · │ · │ · │
│ · │ · │ · │
│ 2024-11-28 06:01:00 │ NULL │ NULL │
│ 2024-12-05 06:01:00 │ NULL │ NULL │
│ 2024-12-23 06:00:00 │ NULL │ NULL │
├──────────────────────┴───────────────────────┴─────────────┤
│ 366 rows (6 shown) 3 columns │
└────────────────────────────────────────────────────────────┘
提示:由于
gap_minutes是基于窗口函数计算的,因此我们可以使用QUALIFY对其进行筛选,例如:QUALIFY gap_minutes IS NULL
然后,我们通过将经过的分钟数与超时时间(在本例中为 10 分钟)进行比较,来标记当前记录是否与上一个记录位于同一会话中
IF(gap_minutes >= 10 OR gap_minutes IS NULL, 1, 0) AS new_session
通过在天级别上对 new_session 属性应用移动总和,我们将标识符分配给会话
sum(new_session) OVER (
PARTITION BY station_service_date
ORDER BY station_service_time ROWS UNBOUNDED PRECEDING
) AS session_id_in_day
将所有内容整合在一起,我们现在可以检索在 18 小时白天服务时间(早上 6 点到晚上 11 点之间的时数)内至少有一个 10 分钟不活动间隔的日期
WITH ams_daily_traffic AS (
SELECT
service_sk,
station_service_time,
lag(station_service_time) OVER (
PARTITION BY station_service_time::DATE
ORDER BY station_service_time
) AS previous_service_time,
date_diff('minute', previous_service_time, station_service_time) AS gap_minutes
FROM ams_traffic_v
WHERE hour(station_service_time) BETWEEN 6 AND 23
), window_calculation AS (
SELECT
service_sk,
station_service_time,
station_service_time::DATE AS station_service_date,
gap_minutes,
IF(gap_minutes >= 10 OR gap_minutes IS NULL, 1, 0) new_session,
sum(new_session) OVER (
PARTITION BY station_service_date
ORDER BY station_service_time ROWS UNBOUNDED PRECEDING
) AS session_id_in_day
FROM ams_daily_traffic
), session_window AS (
SELECT
station_service_date,
session_id_in_day,
max(gap_minutes) AS gap_minutes,
min(station_service_time) AS window_start,
max(station_service_time) AS window_end,
count(service_sk) AS number_of_services
FROM window_calculation
GROUP BY ALL
)
SELECT
station_service_date,
max(ceil(date_diff('minute', window_start, window_end) / 60)) AS number_of_hours_without_gap,
count(*) AS number_of_sessions,
sum(number_of_services) as number_of_services,
FROM session_window
GROUP BY ALL
HAVING number_of_hours_without_gap < 18
ORDER BY 2, 1;
┌──────────────────────┬─────────────────────────────┬────────────────────┬────────────────────┐
│ station_service_date │ number_of_hours_without_gap │ number_of_sessions │ number_of_services │
│ date │ double │ int64 │ int128 │
├──────────────────────┼─────────────────────────────┼────────────────────┼────────────────────┤
│ 2024-04-29 │ 7.0 │ 12 │ 521 │
│ 2024-12-31 │ 14.0 │ 6 │ 946 │
│ 2024-01-01 │ 16.0 │ 6 │ 847 │
│ 2024-04-30 │ 16.0 │ 7 │ 645 │
│ 2024-04-14 │ 17.0 │ 3 │ 1289 │
│ 2024-05-01 │ 17.0 │ 5 │ 788 │
│ 2024-05-02 │ 17.0 │ 3 │ 729 │
│ 2024-05-03 │ 17.0 │ 5 │ 699 │
│ 2024-05-04 │ 17.0 │ 3 │ 907 │
│ 2024-05-19 │ 17.0 │ 3 │ 837 │
│ 2024-10-28 │ 17.0 │ 2 │ 748 │
│ 2024-10-29 │ 17.0 │ 2 │ 785 │
│ 2024-10-30 │ 17.0 │ 2 │ 783 │
│ 2024-11-02 │ 17.0 │ 2 │ 654 │
├──────────────────────┴─────────────────────────────┴────────────────────┴────────────────────┤
│ 14 rows 4 columns │
└──────────────────────────────────────────────────────────────────────────────────────────────┘
2024 年 4 月 29 日肯定发生了什么事! 我们观察到,在 18 小时的服务期间,有 12 个会话窗口,这意味着,至少有 10 次,在 10 分钟的时间段内没有火车到达或离开。 造成这种情况的原因可能是当天没有运行常规列车服务。 事实上,维护工作始于 阿姆斯特丹和乌得勒支 之间。
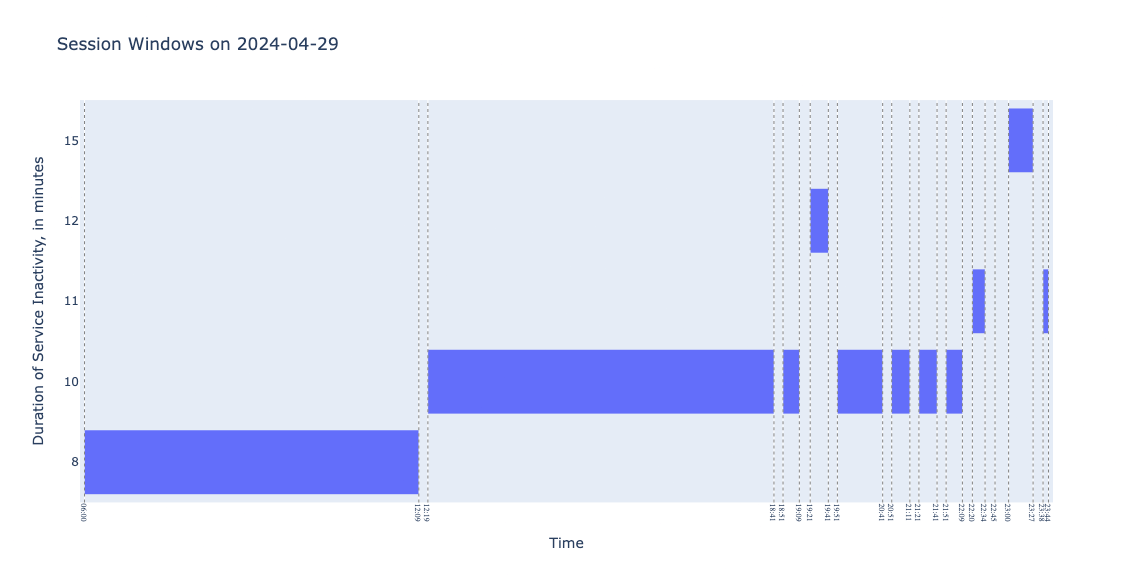
提示:时间窗口使用 Plotly 时间线图表可视化,这是一种甘特图。
结论
在这篇文章中,我们演示了如何在 DuckDB 中对历史时间戳数据实现流式窗口函数,为时间(序列)数据分析提供了一个起点。 我们还建议阅读 “赶上窗口”,这是一篇关于 DuckDB 窗口功能的文章,可以将其应用于此处介绍的函数。

