在 Streamlit 中使用 DuckDB
TL;DR: 我们使用真实的铁路数据集来演示 DuckDB 和 Streamlit 的集成,包括数据库连接管理、DuckDB Python 关系型 API 以及交互式地图图表的响应性。
介绍
在文章 《分析荷兰铁路交通》 中,Gabor 演示了如何使用 SQL 分析数据,以及如何使用 DuckDB 读取远程文件,利用 Rijden de Treinen (火车运行了吗?) 应用程序 的开放数据。
使用上述开放数据,本文将构建一个应用程序,用户可以在其中
- 了解铁路交通数据;
- 使用 Plotly 可视化 2024 年的铁路网络流量;
- 使用 Streamlit Folium 组件,可视化地图上任意选中点周围的五个最近的火车站。
该应用程序将使用 Streamlit 开发,这是一个开源框架,可以使用 Python 轻松实现数据应用程序。应用程序代码可在 GitHub 上获取。
在 Streamlit 中连接到 DuckDB
为了加载铁路交通数据,我们编写了一个函数,该函数将创建我们要使用的两个表:services 和 stations
def prepare_duckdb(duckdb_conn):
duckdb_conn.sql("""
create table if not exists services as
from 'https://blobs.duckdb.org/nl-railway/services-2024.csv.gz'
""")
duckdb_conn.sql("""
create table if not exists stations as
from 'https://blobs.duckdb.org/nl-railway/stations-2023-09.csv'
""")
从 Streamlit 应用程序连接到 DuckDB 有三种方式
- 内存连接;
- 持久化本地文件连接;
- 附加外部数据库。
内存连接
连接到内存数据库意味着每当建立 DuckDB 连接时,都会将数据加载到内存中。根据应用服务器的资源和数据量,在每次请求时创建新的内存 DuckDB 连接并加载所需数据会降低应用程序的速度。在 Streamlit 中,这种行为通过 缓存资源 来解决,具体可以通过以下方式实现:
- 将 DuckDB 连接作为应用程序中的全局共享连接进行缓存;
- 为用户会话缓存 DuckDB 连接。
@st.cache_resource(ttl=datetime.timedelta(hours=1), max_entries=2)
def get_duckdb_memory(session_id):
"""
Set a caching resource which will be refreshed
- either at each hour
- either at each third call
- either when the connection is established for a new session_id
"""
duckdb_conn = duckdb.connect()
prepare_duckdb(duckdb_conn=duckdb_conn)
return duckdb_conn
持久化本地文件连接
可以在应用程序服务器上针对持久化数据库文件建立 DuckDB 连接。数据库文件可以
- 在部署期间、应用程序启动之前创建;
- 作为一个独立的进程,创建数据库并将其复制到应用服务器。根据应用程序对数据新鲜度的要求,可以安排一个进程来刷新数据。
duckdb_conn = duckdb.connect(
"train_stations_and_services.duckdb",
read_only=True
)
附加外部数据库
连接到 DuckDB 的另一种方式是通过 HTTPS 或 S3 兼容的 API 建立与实例的只读连接,例如:DUCKDB_EXTERNAL_LOCATION = "https://blobs.duckdb.org/nl-railway/train_stations_and_services.duckdb"
duckdb_conn = duckdb.connect()
duckdb_conn.execute(f"attach '{DUCKDB_EXTERNAL_LOCATION}' as ext_db")
duckdb_conn.execute("use ext_db")
有关附加外部数据库的更多详细信息,请参见 DuckDB 文档。
注意事项
- 如果每个线程分配 1-4GB 内存,DuckDB 效果最佳,因此在部署 Streamlit 应用程序时,请配置适当的资源。
- 建议是每次数据库交互使用新连接,或者至少在用户会话级别使用一个连接,而不是在应用程序级别使用全局连接。使用全局连接可能会导致意外行为,具体取决于同时使用应用程序的用户数量。
- 使用持久化本地数据库时,请注意,一旦建立了数据库连接,其他进程就无法写入它。一种解决方法是创建一个进程,在服务器上创建并替换数据库文件。
- 使用附加数据库时,请注意应用程序的性能可能会因所选存储解决方案而受到影响。
从现在开始,我们将使用外部数据库。
分析荷兰铁路数据
为了在 Streamlit 中分析数据,我们将通过链式查询使用 Python 关系型 API。我们首先定义一个关系,它将从 stations 中选择所需数据
stations_selection = duckdb_conn.sql("""
select name_long as station_name, geo_lat, geo_lng, code
from stations
""").set_alias("stations_selection")
然后我们定义一个用于 services 选择的关系
services_selection = (
duckdb_conn.sql("from services")
.aggregate("""
station_code: "Stop:Station code",
service_date: "Service:Date",
service_date_format: strftime(service_date, '%d-%b (%A)'),
num_services: count(*)
""")
.set_alias("services")
)
然后我们将这两个关系连接起来,选择车站名称、地理位置和我们稍后将使用的其他详细信息,并将上述代码整合到一个函数中。
def get_stations_services_query(duckdb_conn):
# create a relation for the station selection
stations_selection = ...
# create a relation for the services selection
services_selection = ...
# return the query and the duckdb_conn
return (
stations_selection
.join(
services_selection,
"services.station_code = stations_selection.code"
)
.select("""
service_date,
service_date_format,
station_name,
geo_lat,
geo_lng,
num_services
""")
), duckdb_conn
当我们运行 get_stations_services_query(get_duckdb_conn()) 时,尚未从数据库中检索到数据。这是因为查询评估是惰性的,这意味着直到遇到执行命令,查询才会在数据库上执行。
当遇到以下方法之一时,查询将被执行
stations_query.df()提取到 Pandas 数据帧;stations_query.fetchall()提取到列表中;stations_query.write_to()将数据导出到文件;- 任何其他计算方法,例如
.sum、.row_number等。关系方法可以在 DuckDB 文档中找到。
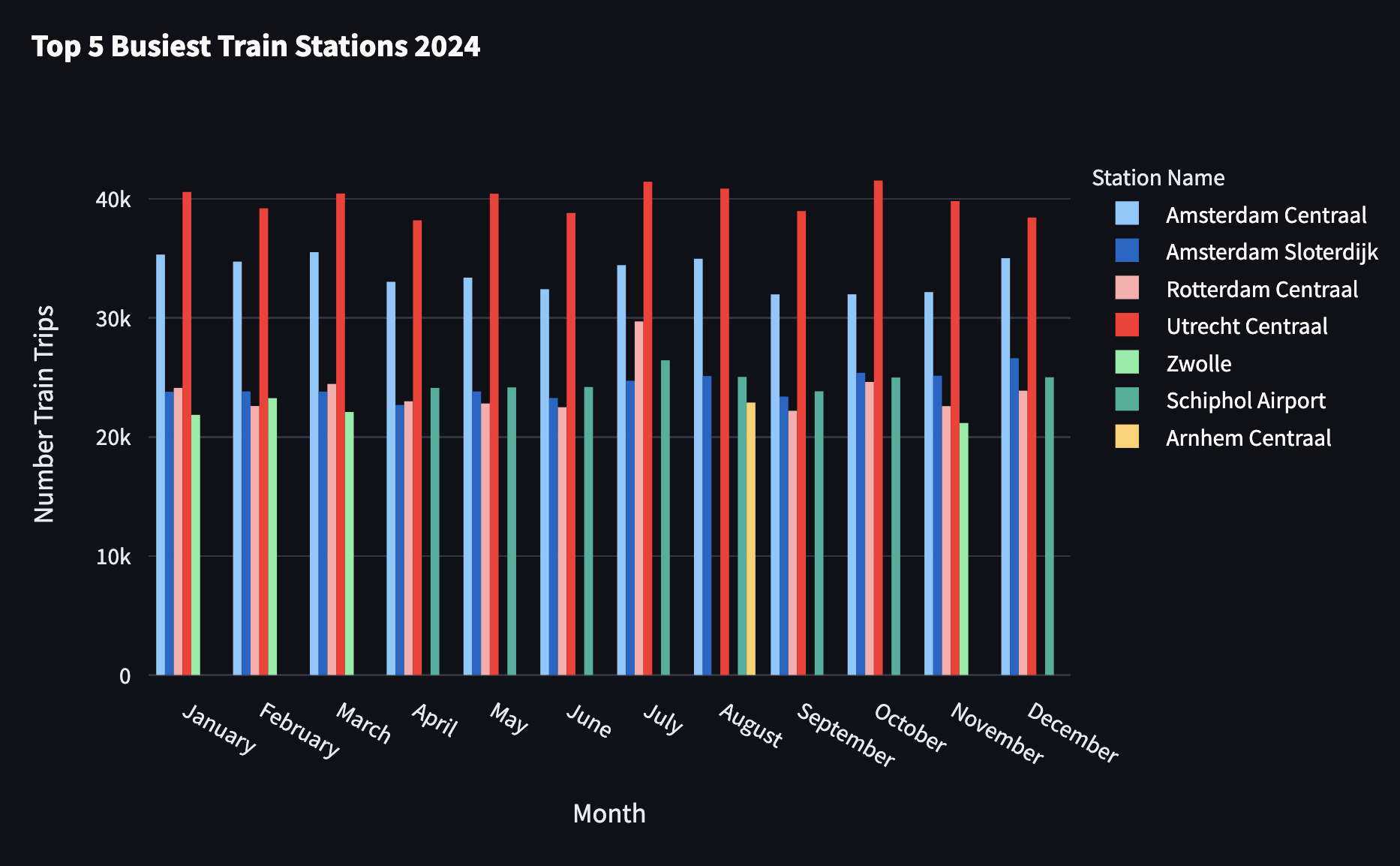
每月最繁忙的 5 个火车站
为了提取每月最繁忙的 5 个火车站,我们从上面的查询开始,添加一个 row_number 计算,并最终过滤排名小于或等于 5 的结果。
stations_query, _ = get_stations_services_query(get_duckdb_conn())
top_5_query = (
stations_query.aggregate("""
station_name,
service_month: monthname(service_date),
service_month_id: month(service_date),
num_services: sum(num_services)
""")
.select("""
station_name,
service_month,
service_month_id,
num_services,
rn: row_number()
over (
partition by service_month
order by num_services desc
)
""")
.filter("rn <= 5")
.order("service_month_id, station_name")
)
Streamlit 提供了一系列图表,例如折线图和条形图,但遗憾的是,它们不提供太多个性化可能性。因此,上述图表是使用 Plotly 生成的,Plotly 是一个开源绘图库,通过调用 st.plotly_chart 与 Streamlit 集成。
铁路网络利用率分析
荷兰火车站的每日列车运行数据是分析全国和全年铁路网络利用率的完美输入。
全国铁路网络利用率

为了分析全国范围内的网络利用率,我们使用 Plotly 的 density_map 图表,它将在地图图表上生成热力图。由于热力图最适合预聚合数据,我们首先聚合列车服务数量和车站的地理位置。
stations_df = stations_query.aggregate(
"geo_lat, geo_lng, num_services: sum(num_services)"
).df()
有趣的是,该国东北部几乎没有铁路覆盖,尽管格罗宁根和海牙全年似乎都在使用,但它们的火车站都没有进入每月最繁忙的 5 个火车站之列。
热力图动画化
从上述静态图表,我们可以通过提供动画帧参数,轻松使用 Plotly 生成动画。在本例中,我们生成了一个动画,显示 2024 年 7 月服务日级别的铁路网络利用率。
全年铁路网络利用率
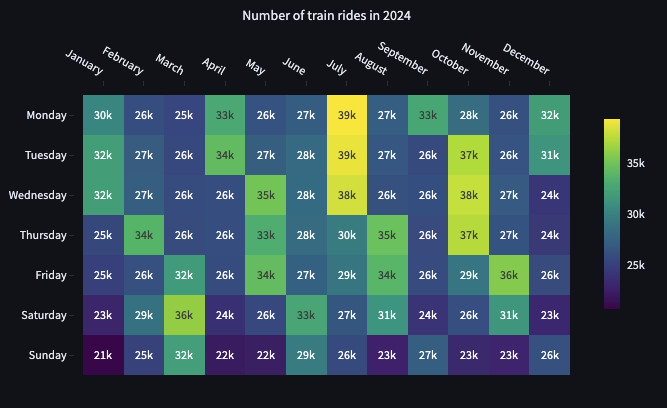
从一年的角度来看,我们很想了解每个月和每周的每一天网络有多繁忙,这通过热力图可以更好地显示。我们通过将服务数量按服务日期的月份名称进行透视,并按 ISO 周日名称进行分组来准备图表输入。目前,Python 关系型 API 中没有透视方法,但我们可以将关系型 API 生成的 SQL 查询用作原始 SQL 透视的源。
@st.cache_data(ttl=3600, max_entries=100)
def get_stations_services_data(_duckdb_conn):
query = _duckdb_conn.sql("from services").aggregate("""
service_day: dayname("Service:Date"),
service_day_isodow: isodow("Service:Date"),
service_month: monthname("Service:Date"),
num_services: count(distinct "Service:RDT-ID")
""")
return (
_duckdb_conn.sql(f"""
pivot ({query.sql_query()})
on service_month
using sum(num_services)
group by service_day, service_day_isodow
order by service_day_isodow
""")
.select(
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December",
"service_day",
)
.df()
)
我们决定创建一个函数,以突出显示 Streamlit 中的 cache_data 功能。虽然上述查询在配备 12 GB 内存的 MacBook Pro 上只需 300 毫秒即可执行,但我们希望缓存结果,因为查询结果不常更改。cache_data 在 Streamlit 中用于缓存函数的结果,与 cache_resource 一样,它具有生存时间和最大条目属性。这两种缓存机制要求传递给函数的输入参数是可哈希的。由于 DuckDB 连接对象不可哈希,我们可以通过添加前缀 _ 告诉 Streamlit 忽略它。
需要注意的是,在热力图表中,列和值的顺序很重要,并且在绘图之前需要重置透视数据的索引。
在 Streamlit 中使用 Plotly 实现交互式地图的代码可在 GitHub 上获取。
使用 Folium 查找最近的 5 个车站
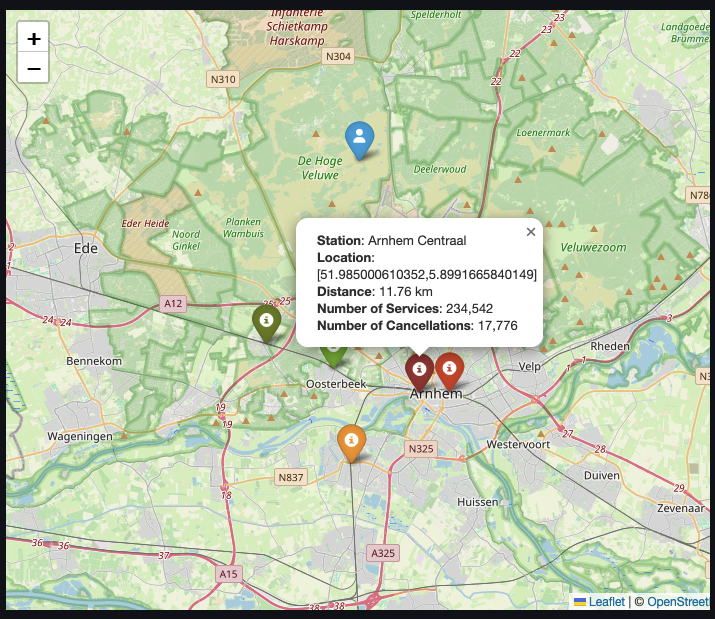
铁路网络数据的另一个用例是查找用户在地图上选择的位置附近最近的火车站。虽然 Streamlit 和 Plotly 具有在图表上注册点击事件的功能,但它们仅在用户选择属于图表数据一部分的点时才起作用。因此,我们将使用 streamlit-folium,这是一个包装在 Folium 上的 Streamlit 组件,它可以在地图上的任何点注册点击。
要在 DuckDB 中处理地理数据,我们必须安装并加载空间扩展
duckdb_conn.sql("install spatial;")
duckdb_conn.sql("load spatial;")
然后我们定义一个函数来检索查询,该查询返回距离由纬度和经度组成的位置最近的五个火车站。
def get_closest_stations_query(duckdb_conn, lat, lng):
stations_selection = duckdb_conn.sql("""
select name_long as station_name, geo_lat, geo_lng, code
from stations st
where exists (
select count(*)
from services sv
where st.code = sv."Stop:Station code"
having count(*) > 100
)
""")
return (
stations_selection.project(f"""
code as station_code,
station_name,
geo_lat,
geo_lng,
station_geo_point: st_point(geo_lng, geo_lat),
clicked_geo_point: st_point({lng}, {lat}),
distance_in_m: st_distance_sphere(
st_point(geo_lng, geo_lat),
clicked_geo_point
),
distance_in_km: round(distance_in_m/1000,2)
""")
.order("distance_in_km")
.limit(5)
)
在上述查询中,我们使用 st_point 创建点类型字段,并使用 st_distance_sphere 获取两点之间的距离(以米为单位)。
需要指出的是,虽然我们通常将地理点表示为
[latitude, longitude],但在使用空间扩展时,我们通常将点创建为[longitude, latitude]。这同样适用于 PostGIS。
当用户点击地图时,我们将点击存储在会话状态中,并重新运行 Streamlit 以显示带有新用户选择的地图。当重新运行时,Streamlit 将为当前会话重新运行整个应用程序,因此在构建 Streamlit 应用程序时,理解会话状态和缓存机制至关重要。
在 Streamlit 中使用 Folium 实现交互式地图的代码可在 GitHub 上获取。
结论
在本文中,我们阐述了如何在 Streamlit 中使用 DuckDB,Python 关系型 API 如何通过链式查询使代码更简洁,以及如何使用 Plotly 和 Folium 实现交互式地图,同时利用 Streamlit 的缓存机制。

