DuckDB:在手机上运行TPC-H SF100
TL;DR:DuckDB 可以在 iOS 和 Android 等移动平台上运行,并且完成 TPC-H 基准测试的速度比 20 年前大型机上的尖端研究系统还要快。
几周前,我们着手进行了一系列实验,旨在回答两个简单的问题
- 当在一台新型智能手机上运行时,DuckDB 能否在 SF100 数据集上完成 TPC-H 查询?
- 如果能,DuckDB 能否在 400 秒内完成一次运行,即比最初引入向量化查询处理的研究论文中的系统更快?
这些问题引导我们进行了一次有趣的探索。在此过程中,我们玩得很开心,并了解了冷运行与真正冷运行之间的区别。继续阅读以了解更多信息。
干冰与火之歌
我们的第一次尝试是使用一台 iPhone,具体来说是一台 iPhone 16 Pro。这款手机拥有 8 GB 内存和 6 核 CPU,其中包含 2 个性能核心(运行频率 4.05 GHz)和 4 个效率核心(运行频率 2.42 GHz)。
我们使用 DuckDB Swift 客户端实现了该应用程序,并将所有 30 GB 的基准测试数据加载到手机上。我们很快发现 iPhone 确实可以毫无问题地运行工作负载——除了它在工作负载期间发热。这促使手机执行热节流,降低 CPU 速度以减少热量产生。因此,DuckDB 耗时 615.1 秒。这不错,但不足以达到我们的目标。
这些结果让我们思考:如果我们改善手机的散热效果会怎样?为此,我们购买了一盒干冰,其温度低于零下 50 摄氏度,并在实验期间将手机放入其中。

这帮助很大:DuckDB 在 478.2 秒内完成。这是一个超过 20% 的改进——但我们仍然未能达到 400 秒以下。

安卓机器人会梦见电动鸭吗?
在我们的下一次实验中,我们选用了一台运行 Android 14 的 三星 Galaxy S24 Ultra 手机。这款手机充满了有趣的硬件。首先,它拥有一个 8 核 CPU,包含 4 种不同类型的核心(1×3.39 GHz、3×3.10 GHz、2×2.90 GHz 和 2×2.20 GHz)。其次,它拥有巨大的 RAM——准确地说是 12 GB。最后,其散热系统包含一个 均热板 以改善散热。
我们在 Termux 终端模拟器中运行了 DuckDB。我们按照 Android 构建说明从源代码编译了 DuckDB CLI 客户端,并从命令行运行了实验。
最终结果毫无悬念。这款安卓手机在 235.0 秒内完成了基准测试,比我们的基线性能高出约 40%。
从未有阴天
这些结果让我们思考:这些结果与云服务器相比如何?我们选择了 AWS EC2 中两个基于 x86 的云实例,它们都配备了实例附加的 NVMe 存储。
这些基准测试的细节远不如之前的有趣。我们启动了安装 Ubuntu 24.04 的实例,并在命令行中运行了 DuckDB。我们发现一个 r6id.large 实例(2 个 vCPU,16 GB RAM)在 570.8 秒内完成了查询,这与空冷 iPhone 的性能大致相当。然而,一个 r6id.xlarge(4 个 vCPU,32 GB RAM)在 166.2 秒内完成了基准测试,比我们在手机上获得的任何结果都要快。
DuckDB 结果摘要
该表格包含 DuckDB 基准测试结果的摘要。
| 设置 | CPU 核心数 | 内存 | 运行时长 |
|---|---|---|---|
| iPhone 16 Pro(空冷) | 6 | 8 GB | 615.1 秒 |
| iPhone 16 Pro(干冰冷却) | 6 | 8 GB | 478.2 秒 |
| 三星 Galaxy S24 Ultra | 8 | 12 GB | 235.0 秒 |
AWS EC2 r6id.large |
2 | 16 GB | 570.8 秒 |
AWS EC2 r6id.xlarge |
4 | 32 GB | 166.2 秒 |
历史背景
那么,我们最初为什么要进行这些实验呢?
就在几周前,DuckDB 的诞生地 CWI 举行了 Dijkstra 奖学金颁奖典礼。该奖学金授予 Marcin Żukowski,以表彰他在数据库管理系统开发中的开创性作用,以及他成功创业并开发出 VectorWise 和 Snowflake 等系统。
许多源自 Marcin 研究的思想都被用于 DuckDB。最重要的是,向量化查询处理使得 DuckDB 能够同时实现快速和可移植。他与合著者 Peter Boncz 和 Niels Nes 在 CIDR 2005 年的论文 “MonetDB/X100: 超流水线查询执行 (Hyper-Pipelining Query Execution)” 中首次描述了这种范式。
术语向量化、超流水线和超标量指的是同一个思想:以切片方式处理数据,这在逐行处理或逐列处理之间取得了很好的折衷。DuckDB 的查询引擎也使用了相同的原理。
这篇论文于 2005 年 1 月发表,因此可以肯定它在 2004 年底定稿——距今几乎正好 20 年!
如果我们阅读这篇论文,会了解到实验是在一台配备 12 GB 内存(与当今三星手机的内存量相同!)的 HP 工作站上进行的。它还配备了 Itanium CPU,看起来像这样

2001 年发布时,Itanium 的目标是高端市场,旨在最终用一种高度专注于 SIMD(单指令多数据)的新指令集取代当时占主导地位的 x86 架构。尽管这一雄心未能实现,但 Itanium 是当时最先进的架构。由于专注于服务器市场,Itanium CPU 拥有大量的缓存:实验中使用的 1.3 GHz Itanium2 型号拥有 3 MB 的 L2 缓存,而同期发布的 Pentium 4 CPU 只有 0.5–1 MB。
该论文提供了运行时间的详细分解
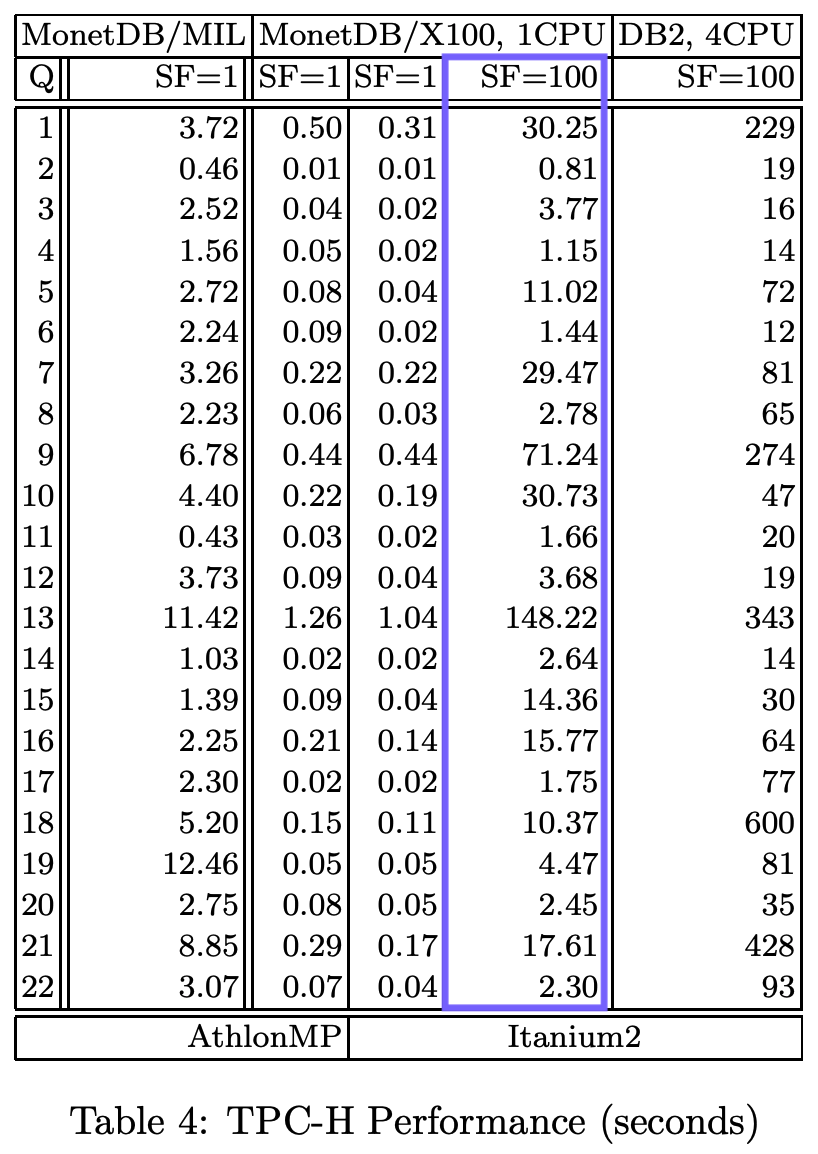
TPC-H SF100 查询的总运行时间为 407.9 秒——这就是我们实验的基准线。这是 Hannes 在活动中展示结果的视频
这是所有结果在图表上的可视化展示

结论
从最初的向量化执行论文到在手机上运行分析型数据库,这是一段漫长的旅程。许多关键创新使得这些结果得以实现,而硬件的巨大改进只是其中之一。另一个关键组成部分是编译器优化变得更加复杂。因此,虽然 MonetDB/X100 系统需要使用显式 SIMD,但 DuckDB 可以依赖于我们(精心构建的)循环的自动向量化。
剩下的就是回答我们在旅程开始时提出的问题。是的,DuckDB 可以在手机上运行 TPC-H SF100。是的,在某些情况下,它甚至可以在一台放入你口袋的现代智能手机上,超越 2004 年高端机器上运行的研究原型。
随着更先进的硬件、更智能的编译器以及尚待发现的数据库优化,未来的版本只会更快。


{kind=link}