分析优化的并发事务
TL;DR: DuckDB 采用了独特的分析优化型乐观多版本并发控制技术。这些技术使得 DuckDB 能够高效地执行大规模原地更新。
这是关于 DuckDB 的 ACID 支持的第二篇文章。如果您还没有阅读第一篇文章《自信地更改数据与 ACID》,那么最好从那里开始。
在我们上一篇文章中,我们讨论了为什么在满足正式的“ACID”事务属性时,数据更改会更合理。数据系统不应该因为在第 431,741 行遇到某个意想不到的字符串,就允许将“一半”的 CSV 文件导入到表中。
在并发情况下确保事务的 ACID 属性是非常具有挑战性的,也是数据库领域的“圣杯”之一。DuckDB 实现了先进的并发控制和日志记录方法。在本文中,我们将描述 DuckDB 的多版本并发控制(MVCC)和预写式日志(WAL)方案,这些方案专为在并发工作负载下高效地确保分析用例的事务性保证而设计。
并发控制
悲观并发控制。传统的数据库系统使用锁来管理并发。事务获取锁以确保 (a) 其他事务无法看到其未提交的更改,以及 (b) 它看不到其他事务的未提交更改。在读取(共享锁)和写入(排他锁)时都需要获取锁。当不同的事务尝试读取被另一个事务写入的数据时,它必须等待另一个事务完成并释放其对数据的排他锁。这种并发控制称为悲观,因为即使事务之间没有冲突,也总是会获取锁。
这种策略适用于事务性工作负载。这些工作负载由读取或修改少量行的小型事务组成。典型的事务只锁定几行,并且只在短时间内保持这些行被锁定。另一方面,对于分析工作负载,这种策略效果不佳。这些工作负载由读取或修改表大部分的大型事务组成。因此,在采用悲观并发控制的系统中执行的分析事务将锁定许多行,并长时间保持这些行被锁定,从而阻止其他事务的执行。
乐观并发控制。DuckDB 使用不同的方法来管理并发冲突。事务不持有锁——它们可以随时读取和写入任何表的任何行。当发生冲突,多个事务试图同时写入同一行时,冲突的事务之一将被中止。如果需要,中止的事务可以重试。这种并发控制称为乐观。
如果从未发生并发冲突,这种策略将非常高效,因为我们没有通过悲观地获取锁来不必要地减慢事务速度。这种策略非常适合分析工作负载——因为只读事务永远不会相互冲突,并且在这些工作负载中,修改相同行的多个写入操作很少见。
多版本并发控制
在乐观并发控制模型中,多个事务可以同时读取和更改相同的表。我们必须确保这些事务无法看到彼此的未完成更改,以维护 ACID 隔离。一种众所周知的实现方法是多版本并发控制(MVCC)。MVCC 通过保留修改行的多个版本来工作。当事务修改一行时,我们可以创建该行的副本并修改该副本。这允许其他事务继续读取该行的原始版本。这使得每个事务都能看到自己一致的数据库状态。通常,该状态是事务启动时存在的“版本”。MVCC 在数据库系统中广泛使用,例如PostgreSQL 也使用 MVCC。
DuckDB 采用了一种受Thomas Neumann(独一无二的)的论文《用于主内存数据库系统的快速可序列化多版本并发控制》启发的 MVCC 实现。这种 MVCC 实现通过维护表中每行的先前版本列表来工作。事务将原地更新表数据,但会将更新行的先前版本保存在撤销缓冲区中。下面是一个图示示例。
-- add 5 to Sally's balance
UPDATE Accounts SET Balance = Balance + 5 WHERE Name = 'Sally';
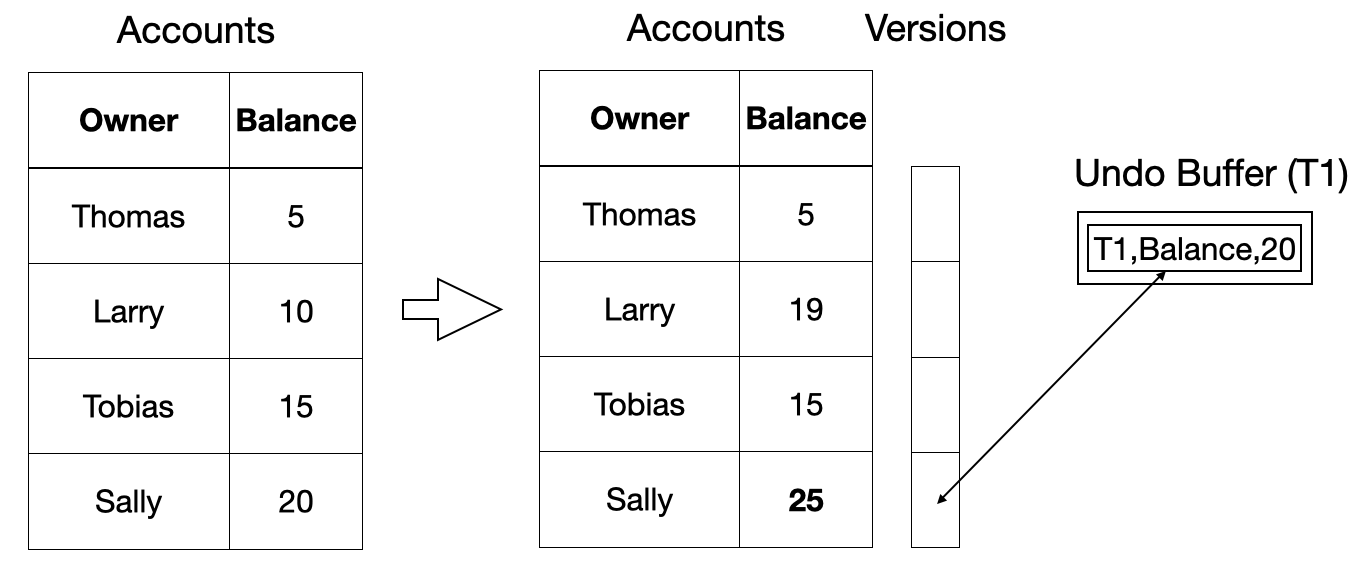
当读取一行时,事务首先会检查该行是否有版本信息。如果没有(这是常见情况),事务可以直接读取原始数据。如果有版本信息,事务必须将事务开始时的事务号与撤销缓冲区中的事务号进行比较,并选择正确的版本进行读取。
分析场景下的高效 MVCC
上述方法对于频繁更改单个行的事务性工作负载非常有效。然而,对于分析用例,我们观察到一种截然不同的使用模式:更改通常更“批量”,并且通常只影响一部分列。例如,我们通常不会删除单个行,而是删除所有符合模式的行,例如:
DELETE FROM orders WHERE order_time < DATE '2010-01-01';
我们也通常批量更新列,例如,修复人们使用无意义的域内值来表达NULL这一长期令人烦恼的问题:
UPDATE people SET age = NULL WHERE age = -99;
如果每一行都有版本信息,这样的批量更改会在撤销缓冲区中创建大量条目,这会消耗大量内存,并且操作和读取效率低下。
还有另一个复杂问题——原始方法依赖于执行原地更新。虽然我们可以高效地对未压缩数据执行原地更新,但对于压缩数据则不可能。由于 DuckDB 在磁盘和内存中都保持数据压缩,因此无法执行原地更新。
为了解决这些问题,DuckDB 而是以每列为基础存储批量版本信息。对于每批 2048 行,只存储一个版本信息条目。版本信息存储的是对数据的更改,而不是旧数据,因为我们不能原地修改原始数据。相反,对数据进行的任何更改都会在检查点期间刷新到磁盘。下面是一个图示示例。
-- add 20% interest to all accounts
UPDATE Accounts SET Balance = Balance + Balance / 5;
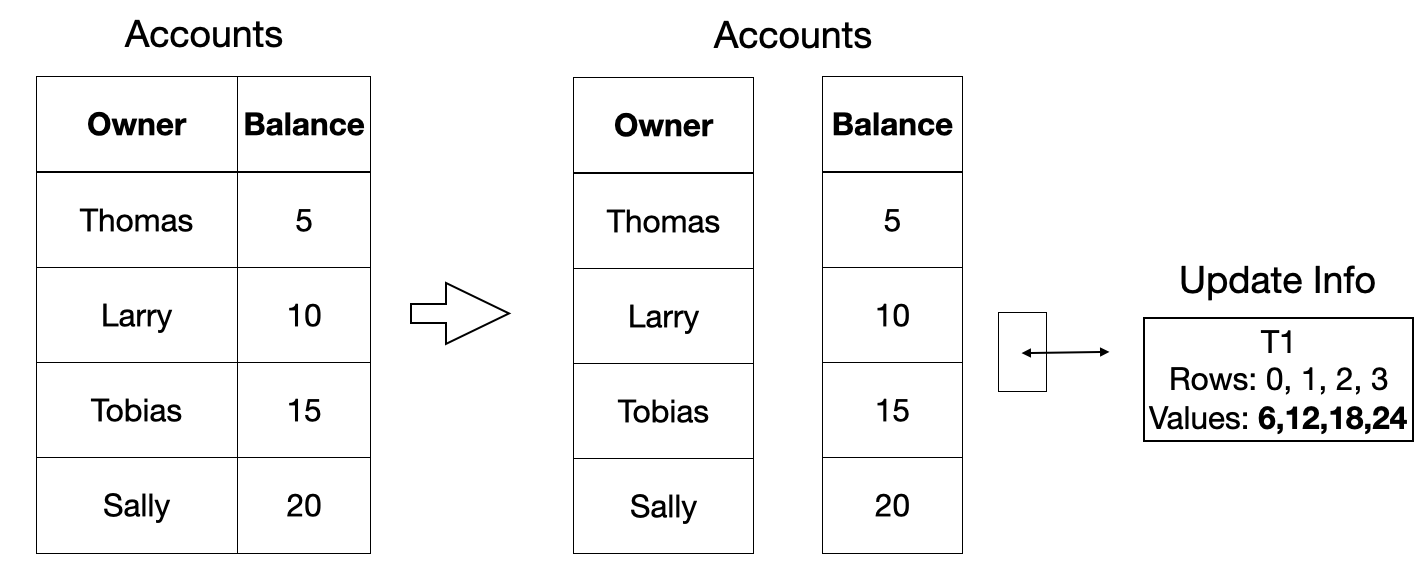
这种撤销缓冲区方案的一个优点是它在很大程度上是性能透明的:如果没有进行任何更改,则不会产生额外的计算成本来支持事务。据我们所知,DuckDB 是唯一一个针对分析用例中常见的批量数据更改进行优化的事务数据管理系统。即使存在更改,我们的事务方案对于我们预期用于分析用例的事务类型来说也速度非常快。
基准测试
下面是一个小实验,比较了 DuckDB 1.1.0、HyPer 9.1.0、SQLite 3.43.2 和 PosgreSQL 14.13 在最近的 MacBook Pro 上的表现,展示了 OLAP 优化型事务方案可能产生的一些效果。我们应该注意到 HyPer 实现了上述 Neumann 论文中的 MVCC 方案。SQLite 实际上没有实现 MVCC,它主要作为比较点包含在内。
我们创建了两个表,每个表有 1 列或 100 列,每列包含 1000 万行,内容为重复的整数值 1-100。
CREATE TABLE mvcc_test_1 (i INTEGER);
INSERT INTO mvcc_test_1
SELECT s1
FROM
generate_series(1, 100) s1(s1),
generate_series(1, 100_000) s2(s2);
CREATE TABLE mvcc_test_100 (i INTEGER,
j1 INTEGER, j2 INTEGER, ..., j99 INTEGER);
INSERT INTO mvcc_test_100
SELECT s1, s1, s1, ..., s1
FROM
generate_series(1, 100) s1(s1),
generate_series(1, 100_000) s2(s2);
然后,我们在这两个表上运行三个事务,它们递增一个单列,受影响的行数递增,分别为 1%、10% 和 100%。
UPDATE mvcc_test_... SET i = i + 1 WHERE i <= 1;
UPDATE mvcc_test_... SET i = i + 1 WHERE i <= 10;
UPDATE mvcc_test_... SET i = i + 1 WHERE i <= 100;
对于单列情况,使用行主序或列主序并发控制方案不应有巨大差异,结果也确实表明了这一点。
| 1 列 | 1% | 10% | 100% |
|---|---|---|---|
| DuckDB | 0.02 | 0.07 | 0.43 |
| SQLite | 0.21 | 0.25 | 0.61 |
| HyPer | 0.66 | 0.28 | 2.37 |
| PostgreSQL | 1.44 | 2.48 | 19.07 |
更改更多行需要更多时间。行很小,每行只包含一个值。DuckDB 和 HyPer 具有更现代的基于撤销缓冲区的 MVCC 方案,通常比 PostgreSQL 快得多。SQLite 表现不错,但它当然没有任何 MVCC。随着更改的行数增加十倍,时间大约增加十倍。到目前为止一切顺利。
对于100 列情况,结果看起来截然不同:
| 100 列 | 1% | 10% | 100% |
|---|---|---|---|
| DuckDB | 0.02 | 0.07 | 0.43 |
| SQLite | 0.51 | 1.79 | 12.93 |
| HyPer | 0.66 | 6.06 | 61.54 |
| PostgreSQL | 1.42 | 5.45 | 50.05 |
回想一下,这里我们正在更改 100 列中的单列,这是处理分析数据集的常见用例。因为 DuckDB 的 MVCC 方案是为这些用例设计的,所以它显示了与上述单列实验完全相同的运行时。在 SQLite 中,即使没有 MVCC,更大的行大小也对完成更新所需的时间产生了明显影响。HyPer 和 PostgreSQL 也显示出更大的、高达 100 倍(!)的减速,因为更改的行数增加了。
这巧妙地引出了检查点。
预写式日志和检查点
任何未写入磁盘而仍滞留在 CPU 缓存或主内存中的数据,在操作系统崩溃或断电时都将丢失。为了在这些不利事件发生时保证更改的持久性,DuckDB 需要确保任何已提交的更改都写入持久存储。然而,事务中的更改可能分散在可能很大的表中,将其完全写入磁盘可能会非常慢,特别是如果它必须在任何事务提交之前发生。此外,我们尚不确定是否真的要持久化某个更改,我们可能在提交过程中遇到故障。
事务数据管理系统平衡将更改写入持久存储和不永久占用时间的传统方法是预写式日志(WAL)。WAL 可以被视为数据库所有更改的日志文件。每次事务提交时,其更改都会写入 WAL。重新启动时,数据库文件从磁盘重新加载,WAL 中的更改(如果存在)会重新应用,然后一切正常运行。在一定数量的更改之后,WAL 中的更改需要物理地应用到表中,这个过程称为“检查点”。之后,WAL 条目可以被丢弃,这个过程称为“截断”。此方案确保即使在提交后立即发生崩溃或断电,更改也能持久化。
DuckDB 实现了预写式日志,您可能偶尔看到一个.wal文件出现。检查点通常在 WAL 文件达到限制时自动发生,默认是 16 MB,但可以通过checkpoint_threshold设置进行调整。数据库关闭时也会自动发生检查点。检查点也可以使用CHECKPOINT和FORCE CHECKPOINT命令显式触发,区别在于后者会中止(回滚)任何活跃事务以确保检查点立即发生,而前者会等待。
DuckDB 显式调用 fsync() 系统调用,以确保所有 WAL 条目都被强制写入持久存储,忽略途中的许多缓存。这是必要的,因为这些缓存也可能在例如断电事件中丢失,因此如果日志条目最终因为操作系统或磁盘出于性能原因决定等待而没有实际写入存储,那么只将日志条目写入 WAL 是没有用的。然而,fsync()确实需要一些时间,虽然通常被认为是不良实践,但有些系统根本不这样做,或者默认不这样做,以吹嘘每秒更多的事务。
在 DuckDB 中,即使是批量加载,例如将大型文件加载到表中(例如,使用COPY语句),也都是完全事务性的。这意味着您可以这样做:
BEGIN TRANSACTION;
CREATE TABLE people (age INTEGER, ...);
COPY people FROM 'many_people.csv';
UPDATE people SET age = NULL WHERE age = -99;
SELECT
CASE
WHEN (SELECT count(*) FROM people) = 1_000_000 THEN true
ELSE error('expected 1m rows')
END;
COMMIT;
该事务创建一个表,将一个大型 CSV 文件复制到表中,然后更新表以替换一个特定值。最后,执行检查以查看表中是否存在预期数量的行。所有这些都捆绑到一个单一事务中。如果在过程中的任何时候出现问题或检查失败,事务将被中止,数据库将不会发生任何更改,甚至表都不会存在。这非常棒,因为它允许为复杂的加载任务(可能涉及多个表)实现全有或全无的语义。
然而,记录大量更改是一个问题。想象一下 many_people.csv 文件很大,比如说十千兆字节。如前所述,所有更改都写入 WAL 并最终进行检查点。文件中的更改足够大,会立即触发检查点。所以现在我们首先将十千兆字节写入 WAL,然后再次读取它们,然后再次将它们写入数据库文件。我们读取了二十千兆字节并写入了二十千兆字节,而不是读取十千兆字节并写入十千兆字节。这并不理想,但 DuckDB 不会允许绕过批量加载的事务,而是乐观地将大量更改直接写入数据库文件中的新块,并仅在 WAL 中添加一个引用。在提交时,这些新块被添加到表中。在回滚时,这些块被标记为空闲空间。因此,虽然这可能导致数据库文件在事务中止时无意义地增加大小,但常见情况将大大受益。同样,这意味着用户体验到接近零成本的事务性。
更多实验
在面对故障时确保并发控制和预写式日志正确运行是非常具有挑战性的。软件工程师倾向于“顺利路径”,即一切按预期工作。著名的TPC-H 基准测试实际上包含测试并发和日志方案的测试(3.5.4 节,“持久性测试”)。我们之前的博客文章也实现了这个测试,并且 DuckDB 通过了。
此外,我们还定义了我们自己更具挑战性的持久性测试:我们一个接一个地在子进程中运行 TPC-H 刷新集。子进程报告最后提交的刷新。当它们运行时,在随机(短)时间间隔后,该子进程会被杀死(使用SIGKILL)。然后,DuckDB 会重新启动,它可能会从 WAL 恢复,然后继续执行刷新集。由于随机时间间隔,DuckDB 也可能在 WAL 恢复期间被杀死。这当然不应该对数据库的内容产生任何影响。最后,我们使用 DuckDB 预先计算了运行 4000 个刷新集后的正确结果,并在所有设置完成后检查是否存在任何差异。幸运的是,没有发现任何差异。
为了进一步强调我们的实现,我们在一款特殊的文件系统 LazyFS 上重复了此实验。这款 FUSE 文件系统专门设计用于通过——除其他外——不正确地使用 fsync() 将更改刷新到磁盘来帮助发现数据库系统中的错误。在我们的 LazyFS 配置中,写入文件的任何更改都会被丢弃,除非同步(当文件关闭时也会发生同步)。因此,在我们的实验中,当我们杀死数据库时,WAL 中任何未同步的条目都将丢失。我们已经在 LazyFS 上重新运行了上述持久性测试,并很高兴地报告没有发现任何问题。
结论
在这篇文章中,我们描述了 DuckDB 在并发控制和预写式日志方面的做法。当然,我们正在不断努力改进它们。实际系统中可能出现的一种讨厌的故障模式是文件上的部分(“撕裂”)写入,即写入请求中只有一部分实际写入了文件。幸运的是,LazyFS 可以配置得更加“敌意”,例如完全使读写系统调用失败,返回部分或错误的数据,或只将部分数据写入磁盘。我们计划扩展在这方面的实验,以确保 DuckDB 的事务处理尽可能地万无一失。
谁知道呢,也许我们甚至敢于在某个时候将著名的 Jepsen Kyle 先生放到 DuckDB 上一试身手。

