友好的列表及其伙伴 Lambda
介绍
列表和结构体等嵌套数据类型在分析中广泛使用。多种流行格式,如 Parquet 和 JSON,都支持嵌套类型。传统上,处理嵌套类型需要先进行规范化步骤,然后才能进行任何分析。接着,为了返回嵌套结果,系统需要(重新)聚合数据。从可用性和性能角度来看,规范化和聚合都是不可取的。为了简化嵌套数据操作,包括 DuckDB 在内的分析系统提供了这些嵌套类型的原生功能。
在这篇博客文章中,我们将首先介绍列表和Lambda的基础知识。然后,我们将深入探讨它们的技术细节。最后,我们将展示社区中的一些示例。如果您已经熟悉列表和 Lambda,并且只是为了我们的开箱即用示例,请随意跳过!
列表
在深入了解 Lambda 之前,让我们先快速了解 DuckDB 的LIST 类型。列表包含任意数量的相同数据类型的元素。下面是一个包含两列的表,l 和 n。l 包含整数列表,n 包含整数。
CREATE OR REPLACE TABLE my_lists (l INTEGER[], n INTEGER);
INSERT INTO my_lists VALUES ([1], 1), ([1, 2, 3], 2), ([-1, NULL, 2], 2);
FROM my_lists;
┌───────────────┬───────┐
│ l │ n │
│ int32[] │ int32 │
├───────────────┼───────┤
│ [1] │ 1 │
│ [1, 2, 3] │ 2 │
│ [-1, NULL, 2] │ 2 │
└───────────────┴───────┘
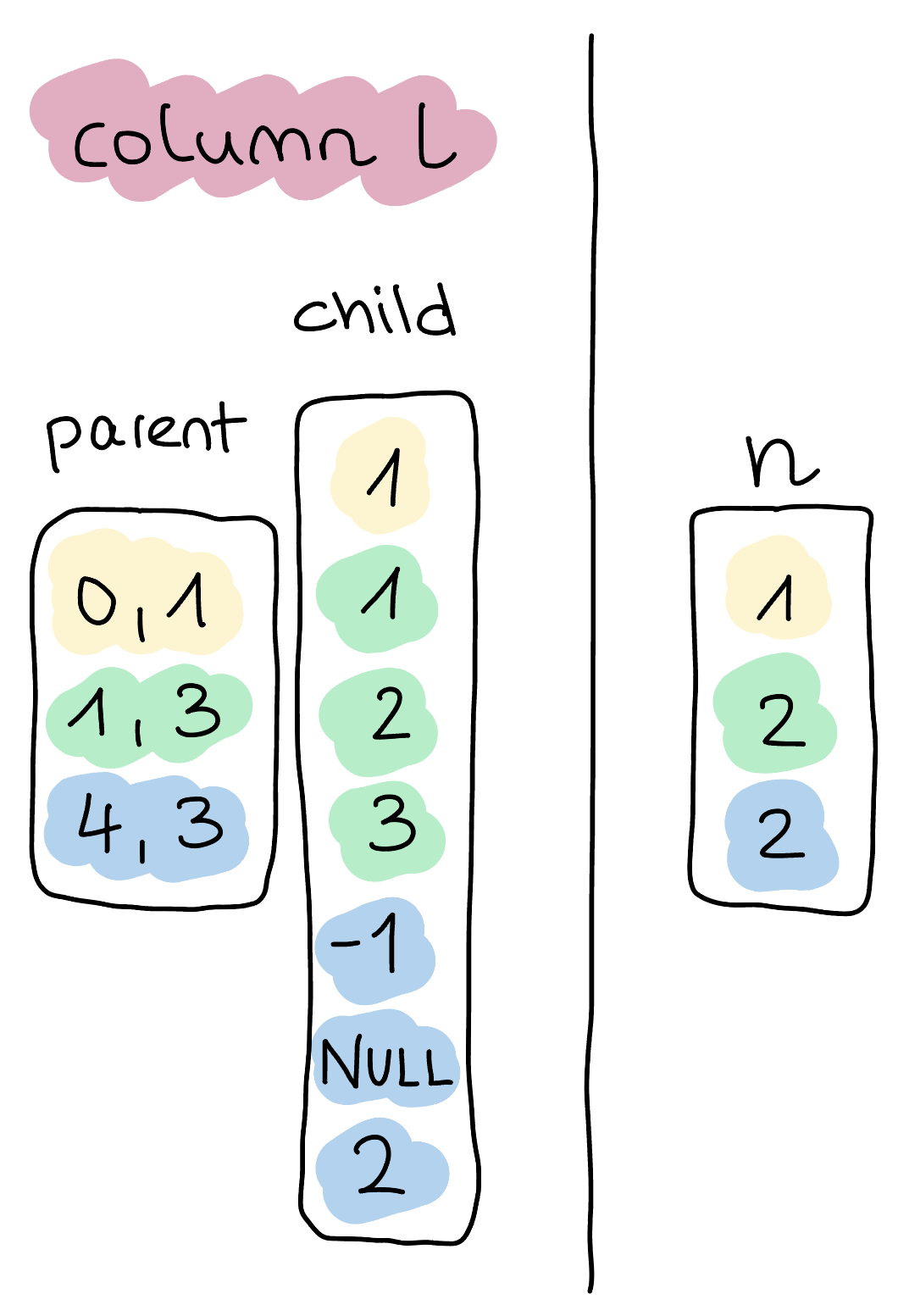
在内部,所有数据都通过 DuckDB 的执行引擎以 Vectors 的形式移动。有关 Vectors 和向量化执行的更多详细信息,请参阅文档和相关研究论文(1 和 2)。在这种情况下,我们得到两个向量,如下图所示。这种表示方式与 Arrow 的物理列表表示方式基本相似。
仔细观察,我们可以发现 l 的嵌套子向量看起来与向量 n 惊人地相似。这些嵌套向量表示使我们的执行引擎能够在嵌套类型上重用现有组件。我们稍后将详细阐述其相关性。
Lambda
Lambda 函数是匿名函数,即没有名称的函数。在 DuckDB 中,Lambda 函数的语法是 (param1, param2, ...) -> expression。参数可以有任何名称,并且 expression 可以是任何 SQL 表达式。
目前,DuckDB 有三个用于处理 Lambda 的标量函数:list_transform、list_filter 和 list_reduce,以及它们的别名。每个函数都接受一个 LIST 作为第一个参数,一个 Lambda 函数作为第二个参数。
Lambda 是我们在SQL 体操:将 SQL 弯曲成灵活的新形态这篇博客文章中的特邀嘉宾。这一次,我们想让它们成为焦点。
深入探究:列表转换
回到我们之前的例子,假设我们想将 n 添加到对应列表 l 的每个元素中。
纯关系型解决方案
使用纯关系运算符,即避免使用列表原生函数,我们需要执行以下步骤:
- 展开列表,同时保持与各自行的连接。我们可以通过发明一个临时的唯一标识符来实现这一点,例如
rowid或UUID。 - 通过添加
n来转换每个元素。 - 使用我们的临时标识符
rowid,我们可以通过将转换后的元素分组到列表中来重新聚合它们。
在 SQL 中,它看起来是这样的:
WITH flattened_tbl AS (
SELECT unnest(l) AS elements, n, rowid
FROM my_lists
)
SELECT array_agg(elements + n) AS result
FROM flattened_tbl
GROUP BY rowid
ORDER BY rowid;
┌──────────────┐
│ result │
│ int32[] │
├──────────────┤
│ [2] │
│ [3, 4, 5] │
│ [1, NULL, 4] │
└──────────────┘
虽然上面的例子相当可读,但更复杂的转换可能会导致冗长的查询,难以编写和维护。更重要的是,这个查询添加了一个 unnest 操作和一个带 GROUP BY 的聚合 (array_agg)。添加 GROUP BY 可能代价高昂,特别是对于大型数据集。
为了完全理解为什么上述查询的性能不理想,我们必须深入探讨其技术含义。在内部,查询执行会执行下图所示的步骤。我们可以直接为 unnest 操作发出子向量,即无需复制任何数据。对于相关列 rowid 和 n,我们使用选择向量,这再次防止了数据的复制。通过这种方式,我们可以在子向量、另一个嵌套向量和展开的向量 n 上执行表达式。
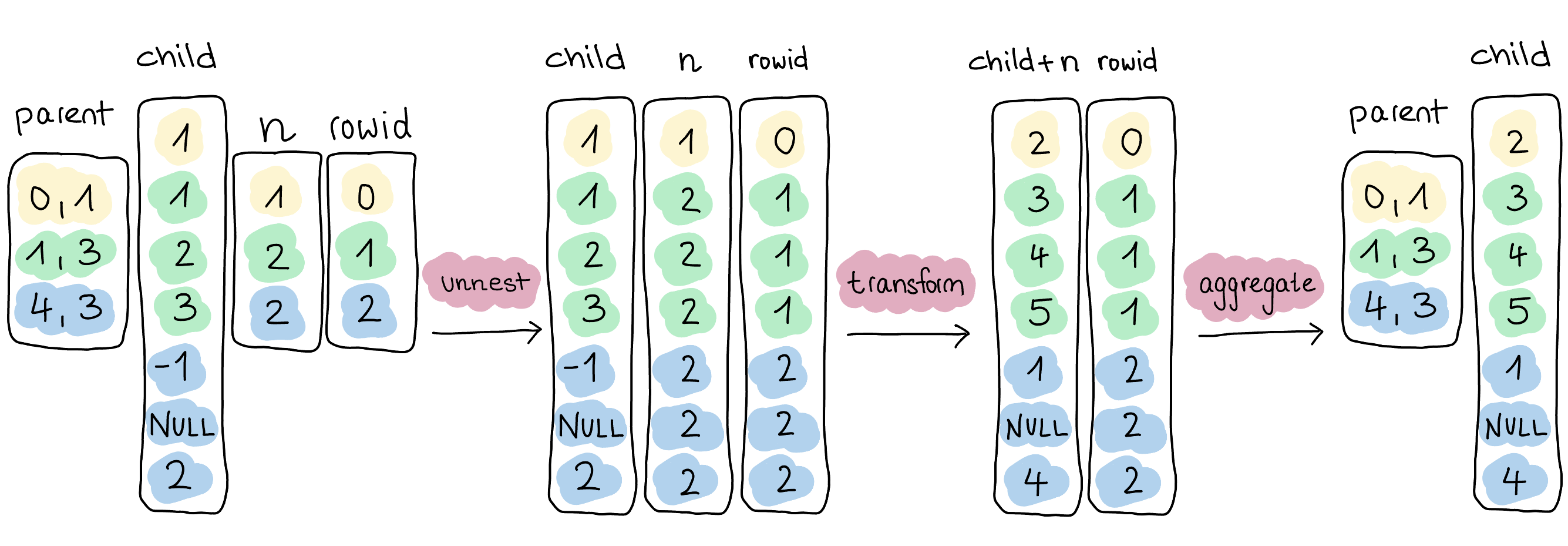
最耗费资源的操作是最后一个,将转换后的元素重新聚合到各自的列表中。由于我们不传播父向量,我们没有关于结果元素与初始列表相关性的信息。重新创建这些列表需要完全复制数据和分区,即使使用DuckDB 的高性能聚合运算符,这也会影响性能。
因此,规范化方法既编写繁琐又效率低下,尽管查询相对简单,但它产生了显著(且不必要)的开销。这又是一个例子,说明将嵌套数据塑造成关系形式或强制其通过矩形会对性能产生显著的负面影响。
原生列表函数
通过支持原生列表函数,DuckDB 通过直接对 LIST 数据结构进行操作来弥补这些缺点。正如我们所见,列表本质上是嵌套列,我们可以将这些函数重塑为我们的执行引擎已经理解的概念,并充分发挥其潜力。
在转换的情况下,对应的列表原生函数是 list_transform。以下是重写的查询:
SELECT list_transform(l, x -> x + n) AS result
FROM my_lists;
或者,使用 Python 的列表推导式语法:
SELECT [x + n FOR x IN l] AS result
FROM my_lists;
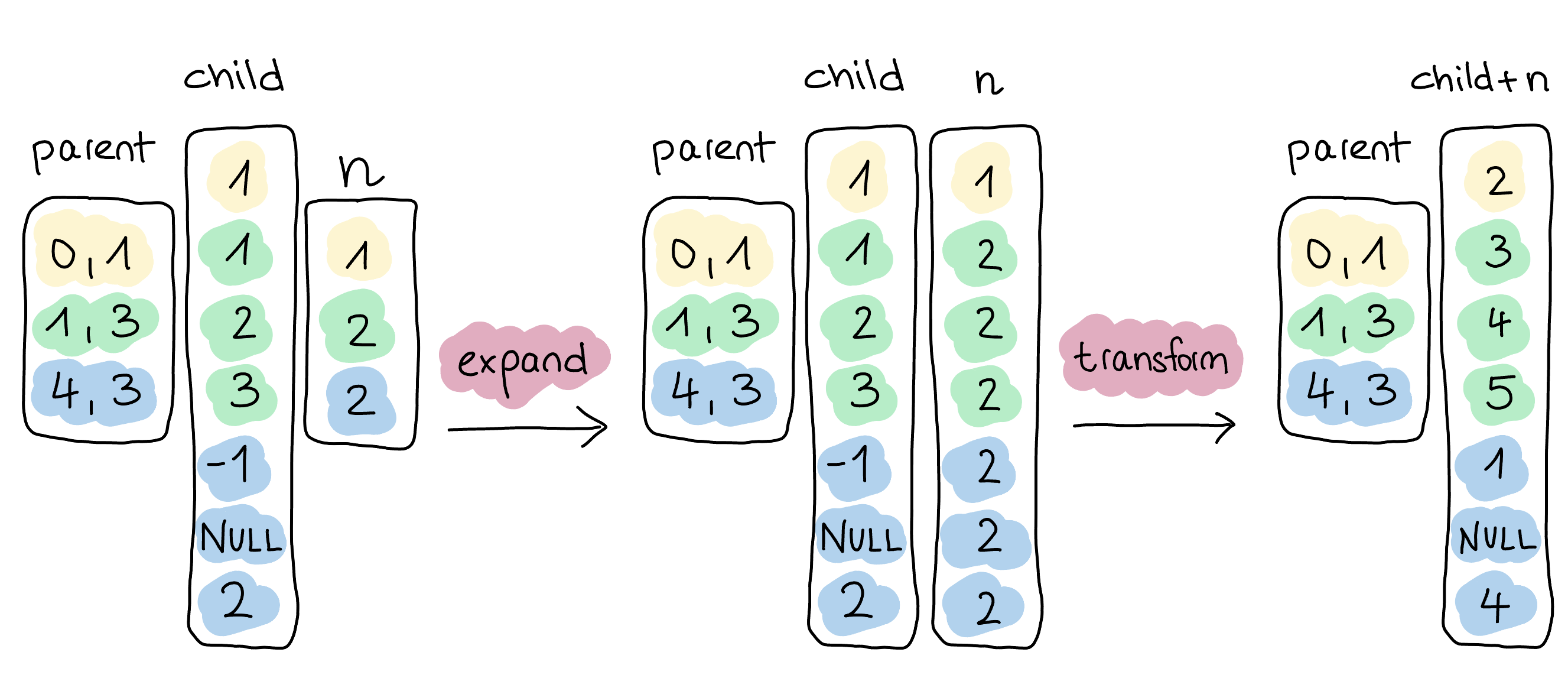
在内部,此查询扩展所有相关向量,在本例中就是 n。正如之前,我们使用选择向量来避免任何数据复制。然后,我们使用 Lambda 函数 x -> x + n 在子向量和扩展向量 n 上执行表达式。由于这是一个列表原生函数,我们知道存在父向量并保持其活跃。因此,一旦我们从转换中获得结果,我们就可以完全省略重新聚合步骤。
为了亲眼看到 list_transform 的效率,我们进行了一项简单的基准测试。首先,我们向表 my_lists 添加了 100 万行,每行包含五个元素。
INSERT INTO my_lists
SELECT [r, r % 10, r + 5, r + 11, r % 2], r
FROM range(1_000_000) AS tbl(r);
然后,我们在此数据上运行了规范化查询和列表原生查询。这两个查询都在 CLI 中使用 DuckDB v1.0.0 在 MacBook Pro 2021(M1 Max 芯片)上运行。
| 规范化 | 原生 |
|---|---|
| 0.522 秒 | 0.027 秒 |
如我们所见,原生查询的速度快了 10 倍以上。太棒了!如果我们使用 EXPLAIN ANALYZE 查看执行计划(未在此博客文章中显示),我们可以看到 DuckDB 大部分时间都花在了 HASH_GROUP_BY 和 UNNEST 运算符上。相比之下,这些运算符在列表原生查询计划中不再存在。
社区中的列表和 Lambda
为了更好地展示结合我们的 LIST 类型和 Lambda 函数的可能性,我们搜索了社区 Discord 和 GitHub,以及互联网的一些偏远角落,寻找令人兴奋的用例。
list_transform
如前所述,list_transform 将 Lambda 函数应用于输入列表的每个元素,并返回一个包含转换后元素的新列表。这里,我们的一位用户通过嵌套不同的 LIST 原生函数实现了一个 list_shuffle 函数。
CREATE OR REPLACE MACRO list_shuffle(l) AS (
list_select(l, list_grade_up([random() FOR _ IN l]))
);
另一位用户研究了使用 DuckDB 查询远程 Parquet 文件。在他们的查询中,他们首先使用 list_transform 生成 Parquet 文件 URL 列表。接下来是 read_parquet 函数,该函数读取 Parquet 文件并计算数据的总大小。查询如下所示:
SELECT
sum(size) AS size
FROM read_parquet(
['https://hugging-face.cn/datasets/vivym/midjourney-messages/resolve/main/data/' ||
format('{:06d}', n) || '.parquet'
FOR n IN generate_series(0, 55)
]
);
list_filter
list_filter 函数过滤输入列表中的所有元素,这些元素使得 Lambda 函数返回 true。
以下是一个使用 list_filter 的示例,来自我们在 Discord 上的讨论,其中用户希望从每个列表中删除索引为 idx 的元素。
CREATE OR REPLACE MACRO remove_idx(l, idx) AS (
list_filter(l, (_, i) -> i != idx)
);
到目前为止,我们在这篇博客文章中主要侧重于展示我们对 Lambda 函数的支持。然而,SQL 及其丰富的方言通常有许多可能的路径。我们忍不住展示了如何使用我们的一些其他原生列表函数实现相同的功能。在这种情况下,我们使用了 list_slice 和 list_concat。
CREATE OR REPLACE MACRO remove_idx(l, idx) AS (
l[:idx - 1] || l[idx + 1:]
);
list_reduce
最近,我们添加了 list_reduce,它将 Lambda 函数应用于累加器值。累加器是前一个 Lambda 函数的结果,也是函数最终返回的值。
我们从 GitHub 上的一个讨论中选取了以下示例。用户希望使用 Lambda 函数来验证 BSN 号码,这是荷兰的社会安全号码。BSN 必须是 8 或 9 位数字,但为了限制范围,我们只关注 9 位数字的 BSN。在将每个数字乘以其索引(从 9 递减到 2),并将最后一位数字乘以 -1 后,总和必须能被 11 整除才能有效。
设置
在我们的示例中,我们假设输入的 BSN 类型为 INTEGER[]。
CREATE OR REPLACE TABLE bsn_tbl AS
FROM VALUES
([2, 4, 6, 7, 4, 7, 5, 9, 6]),
([1, 2, 3, 4, 5, 6, 7, 8, 9]),
([7, 6, 7, 4, 4, 5, 2, 1, 1]),
([8, 7, 9, 0, 2, 3, 4, 1, 7]),
([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
tbl(bsn);
解决方案
当这个方案最初被提出时,DuckDB 还不支持 list_reduce。相反,用户提出了以下解决方案:
CREATE OR REPLACE MACRO valid_bsn(bsn) AS (
list_sum(
[array_extract(bsn, x)::INTEGER * (IF (x = 9, -1, 10 - x))
FOR x IN range(1, 10, 1)]
) % 11 = 0
);
有了 list_reduce,我们可以将查询重写如下。我们还添加了一个验证长度始终为九位数字的检查。
CREATE OR REPLACE MACRO valid_bsn(bsn) AS (
list_reduce(list_reverse(bsn),
(x, y, i) -> IF (i = 1, -x, x) + y * (i + 1)) % 11 = 0
AND len(bsn) = 9
);
使用我们的宏和示例表,我们得到以下结果:
SELECT bsn, valid_bsn(bsn) AS valid
FROM bsn_tbl;
┌────────────────────────────────┬─────────┐
│ bsn │ valid │
│ int32[] │ boolean │
├────────────────────────────────┼─────────┤
│ [2, 4, 6, 7, 4, 7, 5, 9, 6] │ true │
│ [1, 2, 3, 4, 5, 6, 7, 8, 9] │ false │
│ [7, 6, 7, 4, 4, 5, 2, 1, 1] │ true │
│ [8, 7, 9, 0, 2, 3, 4, 1, 7] │ true │
│ [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] │ false │
└────────────────────────────────┴─────────┘
结论
原生嵌套类型支持对于分析系统至关重要。因此,DuckDB 提供原生嵌套类型支持和许多直接使用这些类型的函数。这些函数使嵌套类型的使用更简单、速度大大提高。在这篇博客文章中,我们通过深入研究 list_transform 函数,探讨了使用嵌套类型的技术细节。此外,我们还强调了在社区中遇到的各种用例。

