DuckDB 中对 Delta Lake 的原生支持

TL;DR: DuckDB 现在通过 delta 扩展原生支持 Delta Lake,一个开源的湖仓框架。
在过去的几个月里,DuckDB Labs 与 Databricks 合作,使用新的 delta-kernel-rs 项目,在 DuckDB 中增加了对 Delta Lake 的第一方支持。在这篇博客文章中,我们将简要介绍 Delta Lake、Delta Kernel,当然还有新的 DuckDB Delta 扩展。
如果您已经非常熟悉 Delta Lake 和 Delta Kernel,或者您只是想了解如何使用,请随意跳到精彩部分,了解如何在 DuckDB 中使用 Delta。
简介
Delta Lake 是一种开源存储框架,它支持构建湖仓架构。因此,要理解 Delta Lake,我们需要理解什么是湖仓架构。湖仓是一种数据管理架构,旨在将廉价对象存储的成本效益与智能管理层相结合。简而言之,湖仓架构是各种格式文件的集合,在其之上附加了一些元数据层。这些元数据层旨在为原始文件集合提供额外功能,例如 ACID 事务、时间旅行、分区和模式演进、统计数据等等。湖仓架构使得可以直接在大量的结构化、半结构化和非结构化数据集合上运行各种数据密集型应用程序,例如数据分析和机器学习应用程序,而无需中间的数据仓库步骤。如果您准备深入了解,我们推荐阅读 Michael Armbrust 等人撰写的 CIDR 2021 论文 《湖仓:统一数据仓库和高级分析的新一代开放平台》。然而,如果您(可以理解地)不愿深入阅读晦涩的科学文献,这张图片很好地总结了它
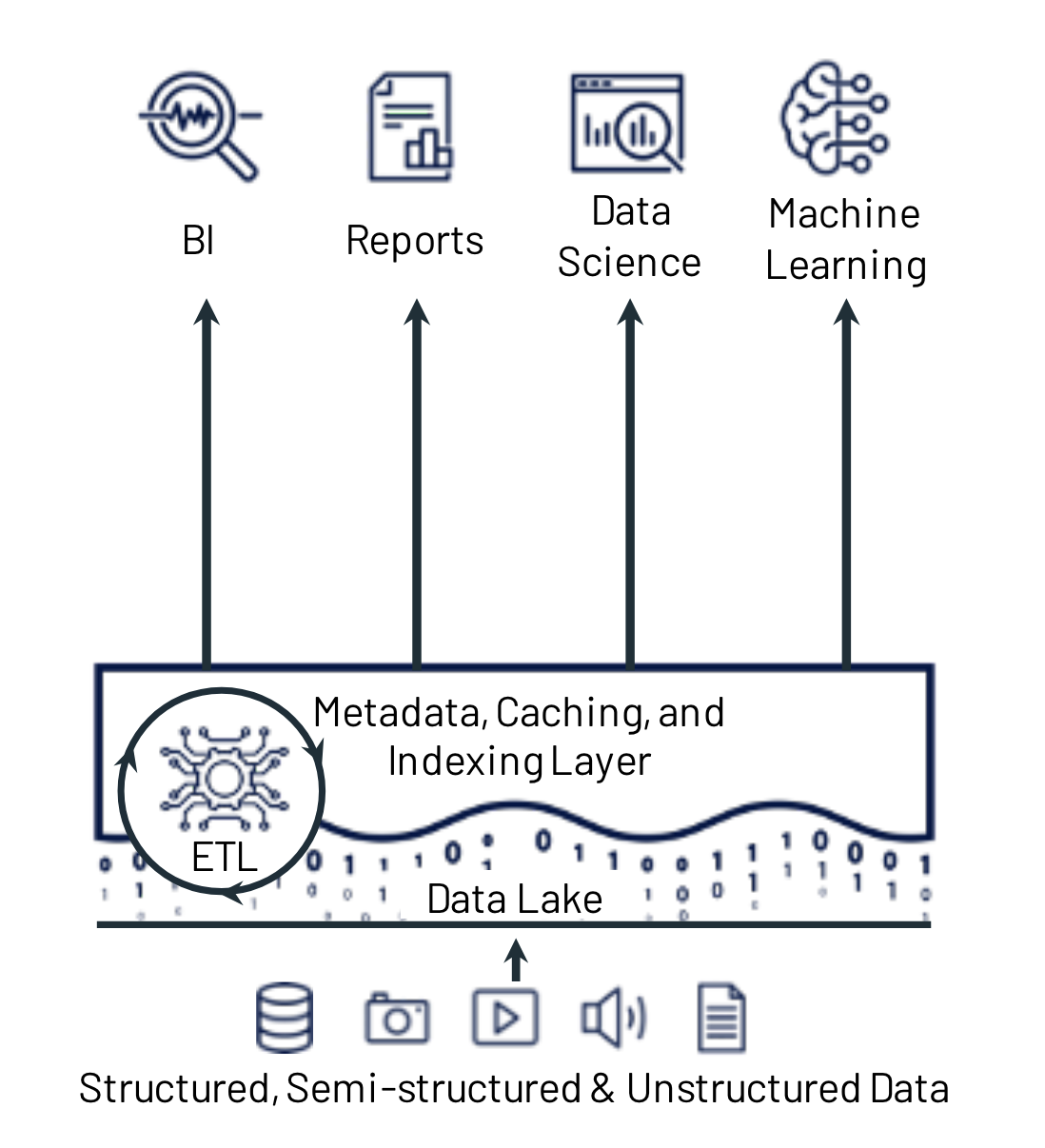
Delta Lake
现在让我们将焦点转向今晚的主角——Delta Lake。Delta Lake(或简称“Delta”)目前是领先的开源湖仓格式之一,与 Apache Iceberg™ 和 Apache HUDI™ 并列。要理解 Delta 表是什么,最简单的方法是将其视为“包含一些元数据的 Parquet 文件集合”。考虑到这种轻微的过度简化,我们现在将创建一个 Delta 表并检查创建的文件,以加深我们的理解。为此,我们将使用以下 Python 包进行设置:duckdb、pandas 和 deltalake
pip install duckdb pandas deltalake
然后,我们使用 DuckDB 创建一些包含测试数据的数据帧,并使用 deltalake 包将其写入 Delta 表。
import duckdb
from deltalake import DeltaTable, write_deltalake
con = duckdb.connect()
df1 = con.query("SELECT i AS id, i % 2 AS part, 'value-' || i AS value FROM range(0, 5) tbl(i)").df()
df2 = con.query("SELECT i AS id, i % 2 AS part, 'value-' || i AS value FROM range(5, 10) tbl(i)").df()
write_deltalake(f"./my_delta_table", df1, partition_by=["part"])
write_deltalake(f"./my_delta_table", df2, partition_by=["part"], mode='append')
运行此脚本后,我们创建了一个基本的 Delta 表,其中包含 10 行数据,分布在两个分区中,这些分区是在两个单独的步骤中添加的。为了再次确认一切按计划进行,让我们使用 DuckDB 查询该表
SELECT *
FROM delta_scan('./my_delta_table')
ORDER BY id;
| id | part | value |
|---|---|---|
| 0 | 0 | value-0 |
| 1 | 1 | value-1 |
| 2 | 0 | value-2 |
| 3 | 1 | value-3 |
| 4 | 0 | value-4 |
| 5 | 1 | value-5 |
| 6 | 0 | value-6 |
| 7 | 1 | value-7 |
| 8 | 0 | value-8 |
| 9 | 1 | value-9 |
看起来很棒!所有预期数据都在那里。现在让我们使用 tree 命令查看实际创建了哪些文件。
tree ./my_delta_table`
my_delta_table
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part=0
│ ├── 0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet
│ └── 1-76c82535-d1e7-4c2f-b700-669019d94a0a-0.parquet
└── part=1
├── 0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet
└── 1-76c82535-d1e7-4c2f-b700-669019d94a0a-0.parquet
tree 的输出显示了两种不同类型的文件。虽然 Delta 表可以包含各种其他类型的文件,但这些文件构成了任何 Delta 表的基础。
首先,有 Parquet 格式的数据文件。数据文件包含存储在表中的所有数据。这与 DuckDB 用于写入 分区 Parquet 文件时数据存储的方式非常相似。
其次,有 JSON 格式的 Delta 文件。Delta 文件包含对表所做更改的日志。通过重放此日志,读取器可以构建表的有效视图。为了说明这一点,让我们稍微看一下第一个 Delta 日志文件
cat my_delta_table/_delta_log/00000000000000000000.json
...
{ "add": {
"path": "part=1/0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet",
"partitionValues": { "part": "1" }
},
...
}
{ "add": {
"path": "part=0/0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet",
"partitionValues": { "part": "0" },
},
...
}
...
正如我们所看到的,此日志文件包含两个 add 对象,描述了数据分别添加到 1 和 0 分区。另请注意,分区值本身明确存储在这些 Delta 文件中,因此即使文件结构看起来与 Hive 风格的分区方案非常相似,但文件夹名称实际上并未被 Delta 内部使用。相反,分区值是从元数据中读取的。
通过这个简单的例子,我们展示了 Delta 的基本工作原理。要更深入地了解其内部机制,请参阅 官方 Delta 规范,按照协议规范的标准,它相当易读。官方规范详细描述了 Delta 如何处理所有细节,从这里描述的基础知识到更复杂的功能,如检查点、删除、模式演进等等。
实现
Delta 内核
支持 Delta 这样相对复杂的协议需要大量的开发和维护工作。因此,当考虑向引擎添加对这类协议的支持时,合理的选择是寻找一个现成的库来处理这个问题。以 Delta Lake 为例,我们可以选择使用 delta-rs 库。然而,在实现原生的 DuckDB Delta 扩展时,这会带来问题:如果使用 delta-rs 库来实现 DuckDB 扩展,所有与 Delta 表的交互都将通过 delta-rs 库进行。但请记住,Delta 表实际上“只是一堆带有一些元数据的 Parquet 文件”。因此,这意味着当 DuckDB 想要读取 Delta 表时,数据文件将由 delta-rs 的 Parquet 读取器使用 delta-rs 文件系统读取。但这很麻烦:DuckDB 本身已经带有一个 出色的 Parquet 读取器。此外,DuckDB 已经支持 各种 文件 系统,并拥有自己的 凭证管理系统。如果将 delta-rs 这样的库用于 DuckDB 的 Delta 扩展,实际上会遇到各种问题:
- 增加扩展二进制文件大小
delta_scan和read_parquet之间不一致的用户体验- 增加维护负担
为了解决这些问题,我们更倾向于拥有一个只实现 Delta 协议的库,而让 DuckDB 处理所有它已经知道如何处理的事情。
对我们来说幸运的是,这个库确实存在,它被称为 Delta Kernel 项目。Delta Kernel 是“一组用于构建 Delta 连接器的库,这些连接器可以从 Delta 表中读取数据和写入数据,而无需理解 Delta 协议的详细信息”。这是通过公开两组相对简单的 API 来实现的,引擎将实现这些 API,如下图所示
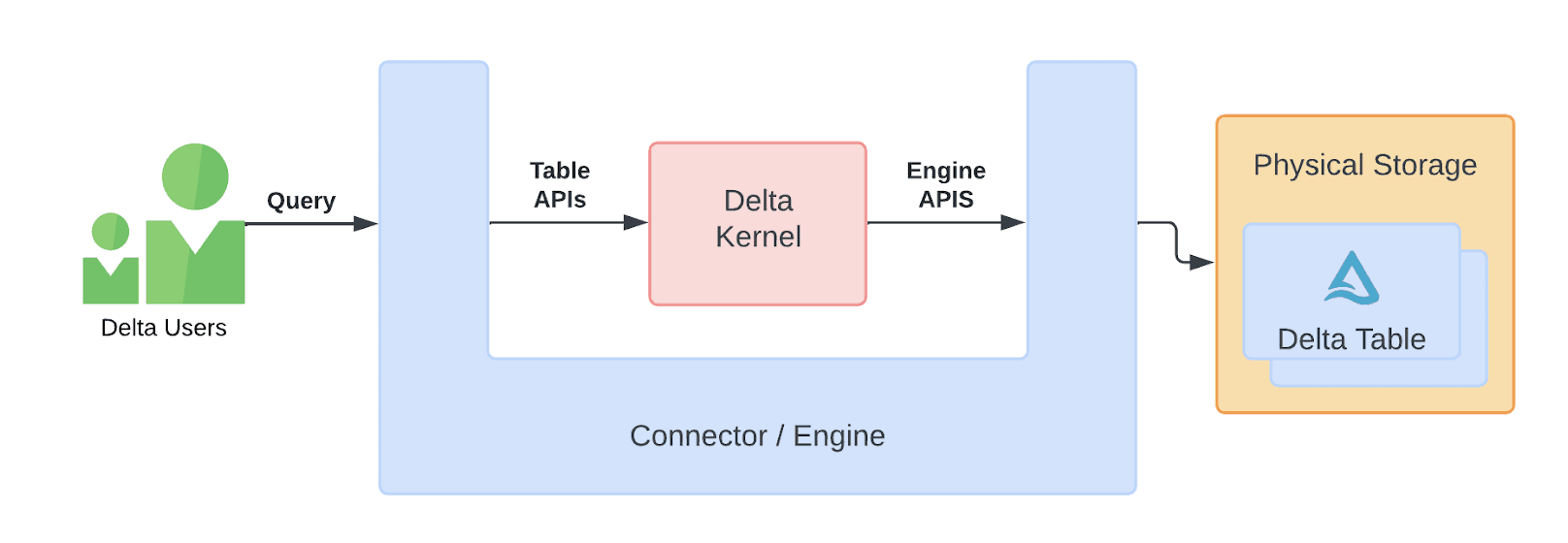
有关 delta-kernel-rs 项目的更多细节,我们推荐阅读这篇 出色的博客文章,其中深入探讨了内部机制和设计理念。
虽然 delta-kernel-rs 库仍处于实验阶段,但它已 最近发布了 v0.1.0 版本,并且已经提供了许多功能。此外,由于 delta-kernel-rs 暴露了 C/C++ 外部函数接口(FFI),将其集成到 DuckDB 扩展中变得非常简单。
DuckDB Delta 扩展 delta_scan
现在我们准备深入探讨 DuckDB Delta 扩展的内部细节。首先,Delta 扩展目前实现了一个单一的表函数:delta_scan。它是一个简单但功能强大的函数,用于扫描 Delta 表。
为了理解这个函数的实现方式,我们首先需要明确涉及的四个主要组件
| 组件 | 描述 |
|---|---|
| Delta 内核 | delta-kernel-rs 库 |
| Delta 扩展 | DuckDB 的可加载 Delta 扩展 |
| Parquet 扩展 | DuckDB 的可加载 Parquet 扩展 |
| DuckDB | 超酷的鸭子主题分析型数据库 |
此外,我们需要理解涉及四个主要的 API
| API | 描述 |
|---|---|
文件系统(FileSystem) |
DuckDB 的 I/O API(用于本地文件、Azure、S3 等) |
表函数(TableFunction) |
DuckDB 的表函数 API(例如,read_parquet、read_csv) |
多文件读取器(MultiFileReader) |
DuckDB 用于处理多文件扫描的 API |
| Delta Kernel C/C++ FFI | Delta Kernel FFI,用于 Delta Lake |
现在我们有了所有的连接点,让我们把它们串联起来。当用户使用 delta_scan 表函数运行查询时,DuckDB 将使用 TableFunction API 调用 Delta 扩展中的 delta_scan 函数。然而,delta_scan 表函数实际上只是常规 read_parquet 函数的一个精确副本。为了将 read_parquet 转换为 delta_scan,它将用自定义的 DeltaMultiFileReader(它只扫描文件列表或通配符匹配的文件)替换 parquet_scan 的常规 MultiFileReader,该读取器将根据 Delta 表元数据生成文件列表。最后,每当 Parquet 扩展需要任何 I/O 时,它都会使用 FileSystem API 调用 DuckDB 来处理 I/O。整个交互过程如下图所示。

在此图中,我们可以看到处理包含 delta_scan 表函数的查询所涉及的所有四个组件。箭头表示组件之间通过四个 API 发生的通信。现在,在读取 Delta 表时,我们可以看到元数据通过 Delta 内核在右侧处理。在左侧,我们可以看到 Parquet 数据如何流经 Parquet 扩展。
虽然这里显然缺少一些重要的细节,例如删除向量和列映射的处理,但我们现在已经介绍了 DuckDB Delta 扩展的基本概念。此外,我们还展示了当前实现如何通过明确定义的 API 连接来抽象组件内部,从而实现非常自然的逻辑分离。通过这样做,该实现获得了以下关键特性
-
Delta 协议的细节在 DuckDB 的任何组件中都基本保持不透明。与 Delta 协议内部机制的唯一接触点是 Delta 内核暴露的狭窄 FFI。这完全由 Delta 扩展处理,其唯一工作就是将其转换为原生的 DuckDB API。
-
完全重用 DuckDB 现有的 Parquet 扫描逻辑,扩展之间没有代码复用或编译时依赖。由于 Delta 和 Parquet 扩展之间的所有交互都通过运行中的 DuckDB 实例,通过 DuckDB API 进行,因此这些扩展仅通过
TableFunction和MultiFileReaderAPI 进行接口。这也意味着对 Parquet 扩展进行的任何未来优化都将自动在 Delta 扩展中可用。 -
所有 I/O 都将通过 DuckDB 的
FileSystemAPI 进行。这意味着所有可供 DuckDB 使用的文件系统(Azure、S3 等)都可以用于扫描。这意味着任何能够读取和列出文件的 DuckDB 文件系统都可以用于 Delta。这在 DuckDB-Wasm 中也很有用,其中使用了自定义文件系统实现。警告:这里需要注意两点。首先,目前 DuckDB Delta 扩展仍然允许 Delta 内核通过内部文件系统库处理一小部分 I/O,这是因为 FFI 尚未暴露FileSystemAPI,但这种情况很快就会改变。其次,虽然 Delta 扩展的架构设计考虑了 DuckDB-Wasm,但该扩展的 Wasm 版本尚未发布。
如何在 DuckDB 中使用 Delta
在 DuckDB 中使用 Delta 扩展非常简单,因为它作为 DuckDB 的核心扩展之一分发,并且支持 自动加载。这意味着您只需启动 DuckDB(使用 v0.10.3 或更高版本)并运行
SELECT * FROM delta_scan('./my_delta_table');
DuckDB 将自动安装并加载 Delta 扩展。然后它将查询本地 Delta 表 ./my_delta_table。
如果您的 Delta 表位于 S3 上,您可能需要设置一些 S3 凭证。如果这些凭证已存在于 默认位置,例如环境变量中,或在 ~/.aws/credentials 文件中?只需运行
CREATE SECRET delta_s1 (
TYPE s3,
PROVIDER credential_chain
)
SELECT * FROM delta_scan('s3://some-bucket/path/to/a/delta/table');
您更喜欢记住您的 AWS 令牌并手动输入它们吗?请使用
CREATE SECRET delta_s2 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY',
REGION 'eu-west-1'
)
SELECT * FROM delta_scan('s3://some-bucket/path/to/a/delta/table');
您有多个具有不同凭证的 Delta 表吗?没问题,您可以使用作用域密钥(scoped secrets)
CREATE SECRET delta_s3 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE1',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY1',
REGION 'eu-west-1',
SCOPE 's3://some-bucket-1'
)
CREATE SECRET delta_s4 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE2',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY2',
REGION 'us-west-1',
SCOPE 's3://some-bucket-2'
)
SELECT * FROM delta_scan('s3://some-bucket-1/table1');
SELECT * FROM delta_scan('s3://some-bucket-2/table2');
最后,如果您的表是公开的,但不在默认的 AWS 区域?请务必使用空的 S3 Secret 来设置区域
CREATE SECRET delta_s5 (
TYPE s3,
REGION 'eu-west-2'
)
SELECT * FROM delta_scan('s3://some-public-bucket/table1');
Delta 扩展的当前状态
目前,Delta 扩展仍被认为是实验性的。这部分是因为 Delta 扩展本身还很新,但也因为其所依赖的 delta-kernel-rs 项目仍处于实验阶段。尽管如此,当前版本的 Delta 扩展已经支持核心的 Delta 扫描功能,例如
- 所有数据类型
- 过滤器和投影下推
- 基于过滤器下推的文件跳过
- 删除向量
- 分区表
- 完全并行扫描
Delta 扩展支持以下平台:linux_amd64、linux_arm64、osx_amd64 和 osx_arm64。对剩余平台的支持即将推出。此外,我们将继续与 Databricks 合作,进一步改进 Delta 扩展,增加更多功能,例如
- 写入支持
- 列映射
- 时间旅行
- Variant、RowIds
- Wasm 支持
有关新增功能的详细信息,请关注 Delta 扩展的 文档 和 仓库。
结论
在这篇博客文章中,我们介绍了 DuckDB 新的 Delta 扩展,它使得您可以直接在自己的 DuckDB 环境中轻松地与 Delta Lake 进行交互。为此,我们通过创建 Delta 表并使用 DuckDB 进行分析,展示了 Delta Lake 格式的结构。
我们希望强调,通过使用 delta-kernel-rs 库,DuckDB 和 Delta 扩展都保持了相对简单,并且在很大程度上与 Delta 协议的内部机制无关。
我们希望您能尝试一下 Delta 扩展,并期待社区的任何反馈!此外,如果您将参加 2024 Databricks 数据 + AI 峰会,务必在周四的主题演讲中关注 DuckDB 联合创始人 Hannes Mühleisen 的演讲,以及同样在周四的深入 分组讨论会,了解更多关于 DuckDB–Delta 集成的细节。

