DuckDB ADBC – 通过 Arrow 数据库连接实现零拷贝数据传输

概要:DuckDB 增加了对 Arrow 数据库连接 (ADBC) 的支持,这是一种 API 标准,可以实现从数据库系统高效地摄取和检索数据,类似于 开放数据库连接 (ODBC) 接口。 但是,与 ODBC 不同,ADBC 专门为列式存储模型而设计,方便列式数据库和外部应用程序之间快速数据传输。
![]()
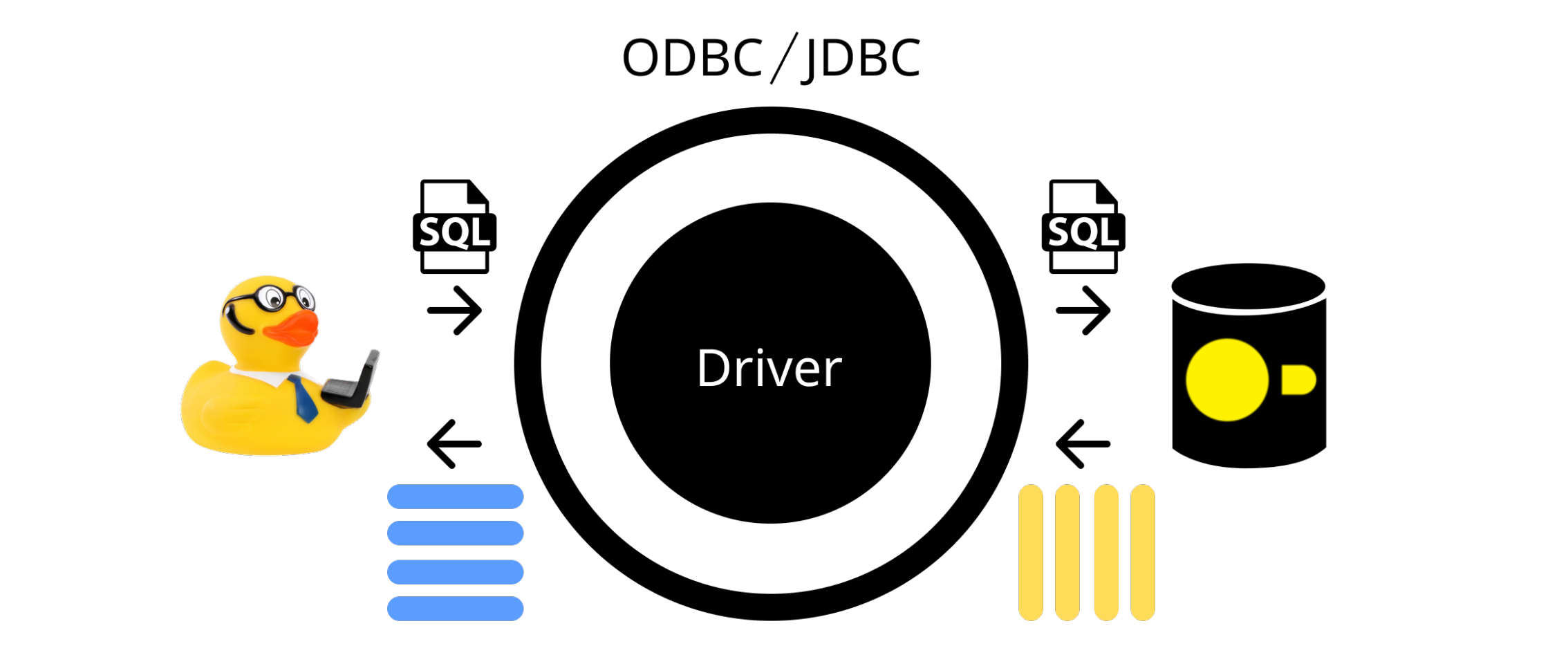
数据库接口标准允许开发人员编写独立于底层数据库管理系统 (DBMS) 的应用程序代码。 DuckDB 支持过去几十年中流行的两个标准:ODBC 的核心接口 和 Java 数据库连接 (JDBC)。 这两个接口都旨在完全支持数据库连接和管理,其中 JDBC 适用于 Java 环境。 使用这些 API,开发人员可以以与 DBMS 无关的方式查询、检索查询结果、运行预处理语句和管理连接。
这些接口是在 90 年代初设计的,当时行式数据库系统占据主导地位。 因此,它们主要用于以行式格式传输数据。 然而,在 2000 年代中期,列式数据库系统开始受到广泛关注,因为它们在数据分析方面具有显著的性能优势(您可以在 EuroPython 中找到我对这种差异的简要举例说明)。 这意味着这些 API 不支持以列式格式传输数据(或者,在 ODBC 的情况下,提供一些支持,但增加了许多复杂性)。 实际上,当像 DuckDB 这样的分析性列式系统使用这些 API 时,在这些表示格式之间转换数据成为一个主要的瓶颈。
下图描述了开发人员如何使用这些 API 查询 DuckDB 数据库。 例如,开发人员可以通过 API 提交 SQL 查询,然后 API 使用 DuckDB 驱动程序在内部调用适当的函数。 然后,在 DuckDB 的内部列式表示中生成查询结果,并且驱动程序负责将其转换为 JDBC 或 ODBC 行式结果格式。 这种转换在重新排列和复制数据方面具有显著的成本,很快就会成为主要的瓶颈。
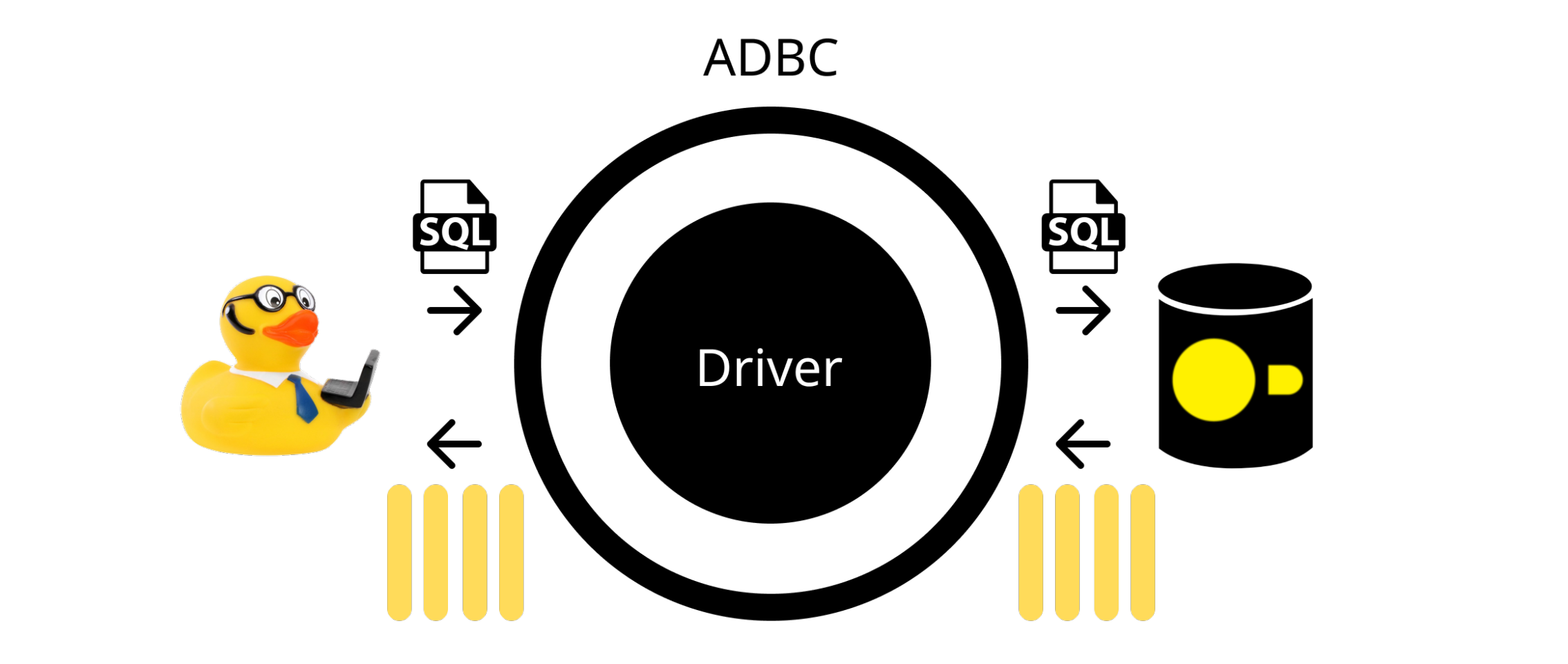
为了克服这种转换成本,提出了 ADBC,它提供了一个通用 API 来支持数据库操作,同时使用 Apache Arrow 内存格式来发送数据进出 DBMS。 DuckDB 现在支持 ADBC 规范。 由于 DuckDB 的 与 Arrow 格式的零拷贝集成,使用 ADBC 作为接口相当高效,因为将 DuckDB 查询结果转换为 Arrow 格式的成本只是一个小的常量。
下图描述了使用 ADBC 时的查询执行流程。 请注意,ODBC/JDBC 之间的主要区别在于结果不需要转换为行式格式。
快速浏览
在我们的快速浏览中,我们将通过 Python 演示使用 DuckDB-ADBC 的数据往返示例。 请注意,DuckDB-ADBC 也可以与其他编程语言一起使用。 具体来说,您可以在 DuckDB GitHub 存储库 中找到 C++ DuckDB-ADBC 示例和测试,以及 C++ 中的使用示例。 为了方便起见,您还可以在 Colab 笔记本中找到此浏览的现成版本。 如果您想查看 DuckDB-ADBC API 的更详细说明或查看 C++ 示例,请参阅我们的 文档页面。
设置
对于此示例,您必须拥有来自 DuckDB 最新前沿版本的动态库、pyarrow 和 adbc-driver-manager。 ADBC 驱动程序管理器是由 Voltron Data 开发的 Python 包。 驱动程序管理器符合 DB-API 2.0。 它包装了 ADBC,使其使用起来更加简单。 有关 ADBC 驱动程序的详细信息,请参阅 ADBC 驱动程序管理器的文档。
虽然 DuckDB 已经在 Python 中符合 DB-API,但 ADBC 的独特之处在于您不需要安装和加载 DuckDB 模块。 此外,与 DB-API 不同,它不使用行式作为其首选的数据传输格式。
pip install pyarrow
pip install adbc-driver-manager
插入数据
首先,我们需要包含本次浏览中将要使用的必要库。 主要是 PyArrow 和来自 ADBC 驱动程序管理器的 DBAPI。
import pyarrow
from adbc_driver_manager import dbapi
接下来,我们可以通过 ADBC 与 DuckDB 建立连接。 此连接仅需要 DuckDB 驱动程序的路径和入口点函数名称。 DuckDB 的入口点是 duckdb_adbc_init。 默认情况下,连接是与内存数据库建立的。 但是,如果需要,您可以选择指定 path 变量并连接到本地 duckdb 实例,从而允许您将数据存储在磁盘上。 请注意,这些是 ADBC 中唯一不是与 DBMS 无关的变量;相反,它们由用户设置,通常通过配置文件设置。
con = dbapi.connect(driver="path/to/duckdb.lib", entrypoint="duckdb_adbc_init", db_kwargs={"path": "test.db"})
要插入数据,我们可以简单地使用来自我们连接的游标调用 adbc_ingest 函数。 它需要我们要执行摄取的表的名称和我们要摄取的 Arrow Python 对象。 此函数还有两种模式:append,其中数据附加到现有表,以及 create,其中表尚不存在并将使用输入数据创建。 默认情况下,它设置为 create,因此我们不需要在此处定义它。
table = pyarrow.table(
[
["Tenacious D", "Backstreet Boys", "Wu Tang Clan"],
[4, 10, 7]
],
names=["Name", "Albums"],
)
with con.cursor() as cursor:
cursor.adbc_ingest("Bands", table)
调用 adbc_ingest 后,将在 DuckDB 连接中创建表并完全插入数据。
读取数据
要从 DuckDB 读取数据,只需使用带有 SQL 查询的 execute 函数,然后将游标的结果返回到所需的 Arrow 格式,例如本示例中的 PyArrow Table。
with con.cursor() as cursor:
cursor.execute("SELECT * FROM Bands")
cursor.fetch_arrow_table()
基准测试 ADBC vs ODBC
在我们的基准测试部分中,我们旨在评估通过 ADBC 和 ODBC 从 DuckDB 读取数据的差异。 此基准测试在具有 32 GB RAM 的 Apple M1 Max 上执行,涉及输出和插入 TPC-H SF 1 的 lineitem 表。 您可以在 GitHub 上找到用于运行此基准测试的代码的存储库。
| 名称 | 时间 (秒) |
|---|---|
| ODBC | 28.149 |
| ADBC | 0.724 |
ODBC 和 ADBC 之间的时间差为 38 倍。 这种显著的对比是由于 ODBC 中存在的额外分配和复制造成的。
结论
DuckDB 现在支持用于数据库连接的 ADBC 标准。 由于 ADBC 使用 Arrow 零拷贝集成,因此与 DuckDB 结合使用时特别高效。
ADBC 特别有趣,因为与 ODBC 相比,它可以显著减少分析系统之间的交互。 例如,如果已经支持 ODBC 的软件,例如,如果 MS-Excel 实施 ADBC,那么与 DuckDB 等列式系统的集成可以从这种显著的性能差异中受益。
目前通过 C 接口和 Python ADBC 驱动程序管理器支持 DuckDB-ADBC。 我们将为其他语言添加更广泛的教程到我们的 文档网页。 请随时告诉我们您首选的通过 ADBC 与 DuckDB 交互的语言!
与往常一样,我们很高兴听到您的想法! 如果您有任何建议、意见或问题,请随时给我们发送 电子邮件!
最后但并非最不重要的是,如果您在使用 ADBC 时遇到任何问题,请在 DuckDB 的问题跟踪器中打开一个问题。

