使用 DuckDB 绘制 JupySQL 图表
TL;DR: JupySQL 在 Jupyter 中提供了无缝的 SQL 体验,并使用 DuckDB 在 Matplotlib 中可视化超出内存的数据集。
介绍
数据可视化对每个数据从业者来说都至关重要,因为它能帮助我们发现那些难以察觉的模式。绘制表格型数据集的典型方法涉及 Pandas 和 Matplotlib。然而,随着数据量的增长,这种技术很快就会力不从心,因为 Pandas 会引入显著的内存开销,即使是绘制中等规模的数据集也变得具有挑战性。
在这篇博文中,我们将使用 JupySQL 和 DuckDB 在我们的笔记本电脑上高效绘制超出内存大小的数据集。JupySQL 是 ipython-sql 的一个分支,它为 Jupyter 添加了 SQL 单元,并且正由 Ploomber 团队积极维护和增强。
JupySQL 与 DuckDB 的结合,尤其是在 JupySQL 新的绘图功能加持下,能够提供强大且用户友好的本地 SQL 处理体验。无需购置强劲(且昂贵!)的 EC2 机器,也无需配置复杂的分布式框架!通过我们的Jupyter Notebook 指南开始使用 JupySQL 和 DuckDB,或者直接访问示例 Colab Notebook!
我们希望 JupySQL 能在 Jupyter 中提供最佳的 SQL 体验,所以如果您有任何反馈,请在 GitHub 上提交一个 issue!
问题
使用 pandas 和 matplotlib 进行数据可视化时的一个显著限制是,我们需要将所有数据加载到内存中,这使得绘制超出内存大小的数据集变得困难。此外,考虑到 pandas 引入的开销,我们可能无法可视化一些我们认为“能放入”内存的较小数据集。
让我们使用 pandas 加载一个示例 .parquet 数据集,以展示内存开销
from urllib.request import urlretrieve
_ = urlretrieve("https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet",
"yellow_tripdata_2022-01.parquet")
下载的 .parquet 文件占用 36 MB 磁盘空间
ls -lh *.parquet
-rw-r--r-- 1 eduardo staff 36M Jan 18 14:45 yellow_tripdata_2022-01.parquet
现在让我们将 .parquet 文件加载为数据帧,看看它占用多少内存
import pandas as pd
df = pd.read_parquet("yellow_tripdata_2022-01.parquet")
df_mb = df.memory_usage().sum() / (1024 ** 2)
print(f"Data frame takes {df_mb:.0f} MB")
Data frame takes 357 MB
如您所见,我们使用的内存几乎是文件大小的 10 倍。考虑到这种开销,我们必须对超出内存大小的含义更加保守,因为“中等”大小的文件一旦加载,可能就无法放入内存了。但这仅仅是我们内存问题的开始。
绘制数据时,我们通常需要对其进行预处理,使其适合可视化。然而,如果我们不小心,这些预处理步骤会复制我们的数据,从而大幅增加内存占用。让我们看一个实际的例子。
我们的示例数据集包含 2022 年 1 月纽约市每趟黄色出租车行程的一个观察值。让我们为行程距离创建一个箱线图
import matplotlib.pyplot as plt
plt.boxplot(df.trip_distance)
_ = plt.title("Trip distance")
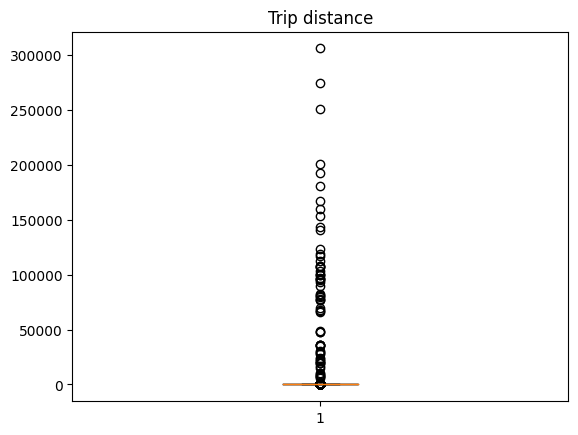
哇!看起来有些纽约人真的很喜欢坐出租车!为了改善可视化效果,我们暂且把那些出租车爱好者放在一边,计算第 99 个百分位数作为截止值。
cutoff = df.trip_distance.quantile(q=0.99)
cutoff
19.7
现在,我们需要过滤掉大于截止值的观察值;但在操作之前,我们先创建一个实用函数来捕获内存使用情况
import psutil
def memory_used():
"""Returns memory used in MB"""
mem = psutil.Process().memory_full_info().uss / (1024 ** 2)
print(f"Memory used: {mem:.0f} MB")
memory_used()
Memory used: 941 MB
现在让我们过滤掉这些观察值
df_ = df[df.trip_distance < cutoff]
绘制直方图
plt.boxplot(df_.trip_distance)
_ = plt.title("Trip distance (top 1% observations removed)")
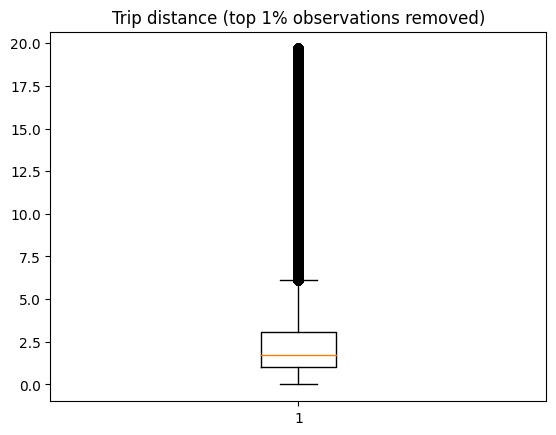
现在移除了前 1% 的异常值后,我们看到了更合理的数据。有少数行程超过 10 英里(也许是一些上城区的纽约人去布鲁克林吃美味披萨?)。
现在我们使用了多少内存?
memory_used()
Memory used: 1321 MB
又多了 380 MB!加载一个 36 MB 的 Parquet 文件,在加载并应用一个预处理步骤后,内存占用变成了 >700 MB!
所以,实际上,当我们使用 pandas 时,内存中能容纳的数据比我们想象的要少得多,即使是配备了 16 GB 内存的笔记本电脑,我们在处理数据集大小时也会受到极大限制。当然,我们可以通过只加载我们绘制的列并删除不需要的数据副本来节省大量内存;然而,说实话,这在实际操作中几乎不会发生。在探索数据时,我们很少能提前知道需要哪些列;此外,我们的时间最好花在分析和可视化数据上,而不是手动删除数据副本。
面对这一挑战时,我们可能会考虑使用分布式框架;然而,这会给过程增加巨大的复杂性,而且它只能部分解决问题,因为我们需要编写代码以分布式方式计算统计数据。或者,我们也可以考虑获取一台更大的机器,如果能访问云资源,这是一种相对直接(但昂贵!)的方法。然而,这仍然需要我们移动数据、设置新环境等。幸运的是,我们有 DuckDB!
DuckDB:用于统计可视化的高度可扩展后端
当使用诸如 hist(直方图)或 boxplot(箱线图)等函数时,matplotlib 会执行两个步骤
- 计算汇总统计数据
- 绘制数据
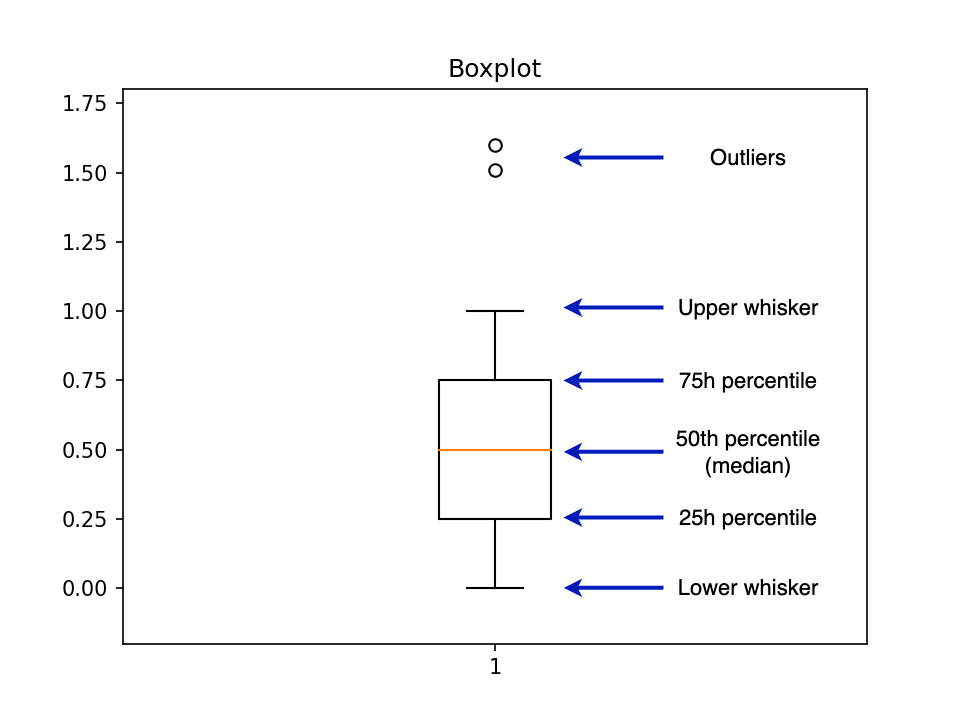
例如,boxplot 会调用另一个名为 boxplot_stats 的函数,该函数返回绘制图表所需的统计数据。要创建一个箱线图,我们需要几个汇总统计数据,例如第 25 百分位数、第 50 百分位数和第 75 百分位数。下图展示了一个箱线图以及各部分的标签
pandas + matplotlib 方法的瓶颈在于 boxplot_stats 函数,因为它需要 numpy.array 或 pandas.Series 作为输入,这迫使我们将所有数据加载到内存中。然而,我们可以实现一个新版本的 boxplot_stats,将数据聚合步骤推送到另一个分析引擎。
我们选择 DuckDB 是因为它极其强大且易于使用。无需启动服务器或管理复杂的配置:使用 pip install 安装,指向您的数据文件,就大功告成了;您可以立即开始聚合数百万的数据点!
您可以在这里查看完整的实现;本质上,我们是将 Matplotlib 的 boxplot_stats 从 Python 翻译成了 SQL。例如,以下查询将计算我们需要的三个百分位数:第 25 个、第 50 个(中位数)和第 75 个
%load_ext sql
%sql duckdb://
%%sql
-- We calculate the percentiles all at once and
-- then convert from list format into separate columns
-- (Improving performance by reducing duplicate work)
WITH stats AS (
SELECT
percentile_disc([0.25, 0.50, 0.75]) WITHIN GROUP
(ORDER BY "trip_distance") AS percentiles
FROM 'yellow_tripdata_2022-01.parquet'
)
SELECT
percentiles[1] AS q1,
percentiles[2] AS median,
percentiles[3] AS q3
FROM stats;
| q1 | 中位数 | q3 |
|---|---|---|
| 1.04 | 1.74 | 3.13 |
一旦我们计算出所有统计数据,我们就会调用 bxp 函数,该函数根据输入的统计数据绘制箱线图。
这个过程已经在 JupySQL 中实现,您可以使用 %sqlplot boxplot 命令创建箱线图。让我们看看如何操作。但首先,我们先检查一下当前使用了多少内存,以便与 pandas 版本进行比较
memory_used()
Memory used: 1351 MB
让我们创建箱线图
%sqlplot boxplot --table yellow_tripdata_2022-01.parquet --column trip_distance
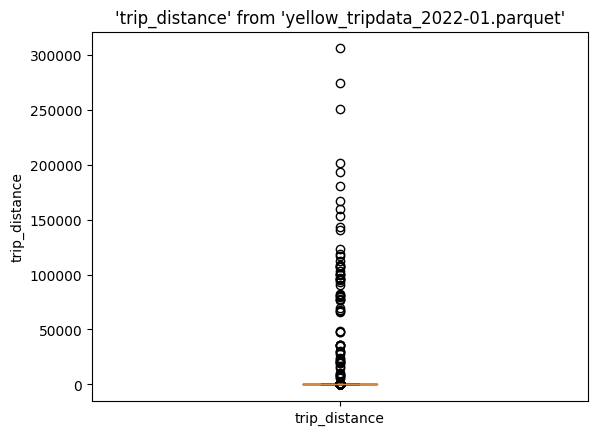
同样,我们看到了所有这些异常值。现在计算截止值
%%sql
SELECT percentile_disc(0.99) WITHIN GROUP (ORDER BY trip_distance)
FROM 'yellow_tripdata_2022-01.parquet'
| quantile_disc(0.99 ORDER BY trip_distance) |
|---|
| 19.7 |
让我们定义一个查询,过滤掉前 1% 的观察值。--save 选项允许我们存储这个 SQL 表达式,我们选择不执行它。
%%sql --save no-outliers --no-execute
SELECT *
FROM 'yellow_tripdata_2022-01.parquet'
WHERE trip_distance < 19.7;
现在我们可以在 %sqlplot boxplot 命令中使用 no-outliers
%sqlplot boxplot --table no-outliers --column trip_distance --with no-outliers
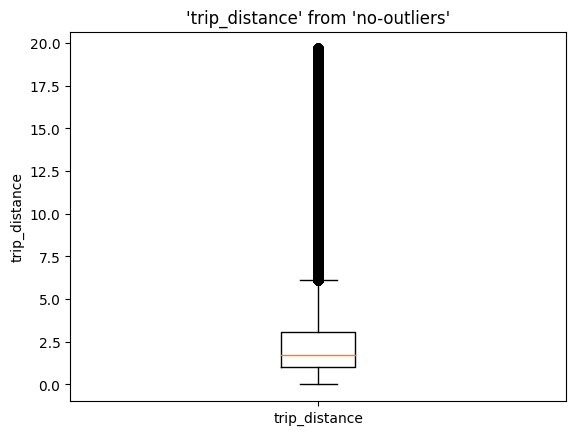
memory_used()
Memory used: 1375 MB
内存使用量基本保持不变(23 MB 的差异,主要归因于新导入的模块)。由于我们依赖 DuckDB 进行数据聚合步骤,SQL 引擎会在完成操作后立即负责加载、聚合和释放内存;这比同时加载所有数据并保留不需要的数据副本效率高得多!
使用 DuckDB 计算直方图统计数据
我们可以将我们的方法扩展到其他统计可视化,例如直方图。
直方图允许我们可视化数据集的分布,从而发现诸如众数、异常值、值范围等模式。与箱线图类似,当使用 pandas + matplotlib 创建直方图时,需要一次性将所有数据加载到内存中;然后,matplotlib 进行聚合并绘图。
在我们的例子中,我们将把聚合操作推送到 DuckDB,它将计算 bin 的位置(X 轴)和高度(Y 轴),然后我们将这些数据传递给 Matplotlib 的 bar 函数来创建直方图。
该实现包括两个步骤。
首先,给定用户选择的 bin 数量(N_BINS),我们计算 BIN_SIZE
%%sql
SELECT (max(trip_distance) - min(trip_distance)) / N_BINS
FROM 'yellow_tripdata_2022-01.parquet';
然后,使用 BIN_SIZE,我们找出落入每个 bin 的观察值数量
%%sql
SELECT
floor("trip_distance" / BIN_SIZE) * BIN_SIZE,
count(*) AS count
FROM 'yellow_tripdata_2022-01.parquet'
GROUP BY 1
ORDER BY 1;
第二个查询的直观解释如下:给定我们有 N_BINS,floor("trip_distance" / BIN_SIZE) 部分会将每个观察值分配到其对应的 bin(1, 2, …, N_BINS),然后,我们乘以 bin 大小以获取 X 轴上的值,而计数则表示 Y 轴上的值。完成这些后,我们调用 bar 绘图函数。
所有这些步骤都在 %sqplot histogram 命令中实现
%sqlplot histogram --table no-outliers --column trip_distance --with no-outliers
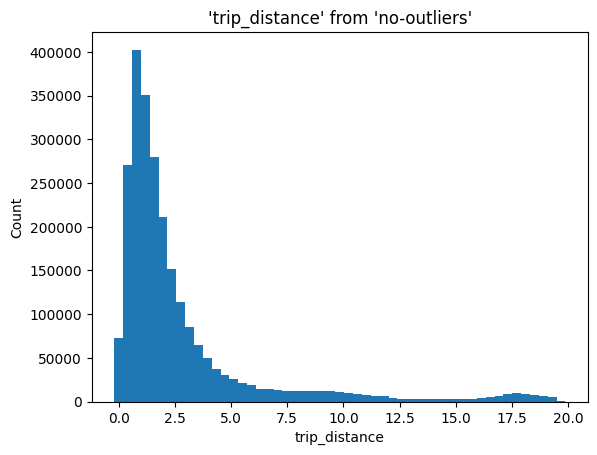
结语
这篇博文展示了一种利用 JupySQL 和 DuckDB 绘制大型数据集的强大方法。如果您需要可视化大型数据集,DuckDB 提供了无与伦比的简洁性和灵活性!
在 Ploomber,我们正在努力为 Jupyter 构建一个功能完善的 SQL 客户端!激动人心的功能,如自动化数据集分析、自动补全等即将推出!所以请关注我们的更新!如果您认为我们应该添加任何功能以在 Jupyter 中提供最佳 SQL 体验,请提交一个 issue!
JupySQL 是 ipython-sql 的一个积极维护的分支,并保持与其完全兼容。如果您想了解更多信息,请查看 GitHub 仓库和文档。
立即尝试
要亲自尝试,请查看这个 Colab Notebook,或者这里有一个您可以粘贴到 Jupyter 中的代码片段
from urllib.request import urlretrieve
urlretrieve("https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet",
"yellow_tripdata_2022-01.parquet")
%pip install jupysql duckdb-engine --quiet
%load_ext sql
%sql duckdb://
%sqlplot boxplot --table yellow_tripdata_2022-01.parquet --column trip_distance
注意:以 % 或 %% 开头的命令仅适用于 Jupyter/IPython。如果您想在常规 Python 会话中尝试此功能,请查看 Python API。

