盒装现代化数据堆栈搭载 DuckDB
太长不看:一个快速、免费、开源的现代化数据堆栈(MDS)现在可以通过结合使用 DuckDB、Meltano、dbt 和 Apache Superset,完全部署到您的笔记本电脑或单台机器上。

本文与 Jacob Matson 合作完成,并同时发布于 dataduel.co。
总结
关于数据管道扩展的文献很多,例如 1 和 2。“使用 Kafka!构建湖仓!不要构建湖仓,使用 Snowflake!不要使用 Snowflake,使用 XYZ!”然而,随着硬件的进步和数据软件的快速成熟,存在一种更简单的方法。本文将阐明如何使用盒装开源 MDS 堆栈(Meltano、DuckDB、dbt 和 Apache Superset)在 Windows 上通过适用于 Linux 的 Windows 子系统(WSL)实现高性能的单节点分析。MDS 中有许多选择,因此如果您正在使用其他堆栈来构建盒装 MDS,请在 DuckDB 的 Twitter、GitHub 或 Discord,或 dbt slack 上与社区分享!或者,也可以来一场关于我们工具选择的友好辩论!
动机
什么是现代化数据堆栈,为何使用它?MDS 可以意味着许多东西(参见示例和历史视角),但从根本上说,它是通过结合多个同类最佳软件工具来形成一个堆栈,回归使用 SQL 进行数据转换。一个典型的堆栈至少包括一个从源提取数据并将其加载到数据仓库的工具、dbt 用于在数据仓库中转换和分析数据,以及一个商业智能工具。MDS 结合了 SQL 的易用性和 Git 等软件开发最佳实践,使分析师能够扩大他们在公司中的影响力。
为什么要将打包的现代化数据堆栈构建在单台机器上,而不是在多台机器和数据仓库上?原因有很多!
- 简化流程以提高开发者生产力
- 通过移除数据仓库来降低成本
- 轻松部署到本地、私有化部署、云端,或三者皆可
- 使用完全免费和开源的堆栈消除软件开销
- 通过 DuckDB 等现代软件和日益强大的单节点计算实例保持高性能
- 通过在笔记本电脑上完成端到端概念验证来实现自给自足
- 通过与 GitHub 集成来实现开发最佳实践
- 通过(可选地)完全在本地或私有化部署运行来增强安全性
如果您为开源社区做贡献或在现代化数据堆栈中提供产品,还有一个额外的好处!
- 通过提供免费且独立的示例堆栈来增加您工具的采用率
- Dagster 的示例项目已经为此使用了 DuckDB!
- 请在 DuckDB 的 Twitter、GitHub 或 Discord,或 dbt slack 上分享使用您工具的示例给社区!
权衡
MDS 的一个关键组成部分是计算的无限可扩展性。这与盒装 MDS 方法如何契合?如今,云计算实例可以比过去实现显著的垂直扩展(例如,AWS 上有 224 个核心和 24 TB 内存!)。笔记本电脑比以往任何时候都更强大。现在,DuckDB 等新的 OLAP 工具可以更好地利用这些计算资源,对于许多分析而言,水平扩展不再是必需的!此外,如果按数据主题领域进行分区,这种盒装 MDS 可以轻松复制到所需的任意数量的盒子中。因此,虽然牺牲了无限计算,但仍能轻松实现显著的规模。
由于这种权衡,这种方法更像是一个“盒装开源分析堆栈”,而非传统的 MDS。它牺牲了无限扩展性,以换取显著的简化和上述其他好处。
选择一个问题
鉴于 NBA 赛季即将开始,对赛季进行蒙特卡罗式模拟既应景又非常适合分析性 SQL。这是一个测试 DuckDB 极限的绝佳场景,因为它只需要简单的输入,并且可以轻松扩展到海量记录。整个项目都保存在一个 GitHub 仓库中,您可以在 GitHub 上找到它。
构建环境
构建项目的详细步骤可以在仓库中找到,但此处将重复概述性步骤。需要注意的是,选择适用于 Linux 的 Windows 子系统(WSL)是为了支持 Apache Superset,而此堆栈的其他组件可以直接在任何操作系统上运行。幸好,在 Windows 上使用 Linux 已经变得非常简单。
- 在 WSL 上安装 Ubuntu 20.04。
- 升级您的软件包(
sudo apt update)。 - 安装 Python。
- 克隆 Git 仓库。
- 在终端中运行
make build,然后运行make run。 - 在终端中为 Superset 创建超级管理员用户,然后登录并配置数据库。
- 在 Superset 中运行测试查询以检查您的工作。
Meltano 作为管道插件的包装器
在此示例中,Meltano 将多个零散的组件整合在一起,使管道能够通过一条语句运行。第一部分是提取器(tap),即“tap-spreadsheets-anywhere”。这个提取器允许我们从各种来源获取平面数据文件。需要注意的是,DuckDB 可以直接从平面文件(本地和网络)、SQLite 和 PostgreSQL 数据库中消费数据。然而,选择这个提取器是为了提供一个清晰的示例,说明如何将静态数据导入数据库,并且这些数据可以轻松地在 meltano.yml 文件中配置。随着数据源复杂性的增加,Meltano 的优势也愈发明显。
plugins:
extractors:
- name: tap-spreadsheets-anywhere
variant: ets
pip_url: git+https://github.com/ets/tap-spreadsheets-anywhere.git
# data sources are configured inside of this extractor
下一部分是加载器(target),即“target-duckdb”。这个加载器可以从任何 Meltano 提取器获取数据并加载到 DuckDB 中。这种方法的美妙之处在于,您无需处理典型数据库带来的所有额外复杂性。DuckDB 可以即插即用,无需任何配置或持续维护。此外,由于组件和数据是共置的,因此无需考虑网络问题,进一步降低了复杂性。
loaders:
- name: target-duckdb
variant: jwills
pip_url: target-duckdb~=0.4
config:
filepath: /tmp/mdsbox.db
default_target_schema: main
接下来是转换器:“dbt-duckdb”。dbt 结合 SQL 和 Jinja 模板实现转换,从而实现易于理解的基于 SQL 的分析工程。DuckDB 的 dbt 适配器现在支持跨线程并行执行,这使得盒装 MDS 运行得更快。由于大部分工作都在 dbt 内部进行,这部分内容将在文章后面详细描述。
transformers:
- name: dbt-duckdb
variant: jwills
pip_url: dbt-core~=1.2.0 dbt-duckdb~=1.2.0
config:
path: /tmp/mdsbox.db
最后,Apache Superset 作为 Meltano 工具包含在内,以实现数据查询和可视化。Superset 利用 DuckDB 的 SQLAlchemy 驱动程序 duckdb_engine,因此它也可以直接查询 DuckDB。
utilities:
- name: superset
variant: apache
pip_url: apache-superset==1.5.0 markupsafe==2.0.1 duckdb-engine==0.6.4
使用 Superset 时,引擎需要配置为以“只读”模式打开 DuckDB。否则,一次只能运行一个查询(并发查询将导致锁定)。这也会阻止在管道运行时刷新 Superset 仪表盘。在这种情况下,管道在 8 秒内运行完成!
整理数据
NBA 赛程是从 basketball-reference.com 下载的,9 月 27 日的 Draft Kings 胜场总数被用作胜场总数。赛程和胜场总数构成了本项目所需的所有输入数据。一旦转换为 CSV 格式,它们就被上传到 GitHub 项目中,并且 meltano.yml 文件也更新以引用文件位置。
加载源
一旦数据在 GitHub 上的网络中,Meltano 就可以将副本拉取到 DuckDB 中。通过命令 meltano run tap-spreadsheets-anywhere target-duckdb,数据被加载到 DuckDB 中,并准备好在 dbt 内部进行转换。
构建 dbt 模型
源加载完成后,数据通过 dbt 进行转换。首先,创建源模型以及场景生成器。然后生成该模拟运行的随机数——需要注意的是,随机数被记录为表而非视图,以便于后续使用图操作符重新运行下游模型以进行故障排除(即 dbt run -s random_num_gen+)。底层数据布局完成后,模拟开始,首先模拟常规赛,然后是附加赛,最后是季后赛。由于每轮比赛都依赖于前一轮,因此此模型中的并行化受限,这体现在 dbt DAG 中,此 DAG 方便地托管在 GitHub Pages 上。
还有一些值得提及的设计选择
- 模拟表和汇总表被拆分为独立的模型,以方便使用和提高透明度。因此,模拟的每一轮都有一个模拟模型和一个结束模型——这允许清晰地了解传递给后续每一轮的正确参数(赛区、球队、Elo 评分)。
- 为防止查询深度过深,'reg_season_end' 和 'playoff_sim_r1' 已被实例化为表。虽然构建时会稍慢,但在查询汇总表(例如 'season_summary')时的性能提升完全值得这点减速。然而,需要注意的是,即使只有 1 万次模拟,数据库也会占用大约 150 MB 的磁盘空间。运行 10 万次模拟很容易将其扩展到几 GB。
连接 Superset
dbt 模型构建完成后,数据可视化即可开始。必须在 Superset 中创建管理员用户才能登录。连接数据库的说明可以在 GitHub 项目中找到,以及如何以“只读模式”连接它的注意事项。
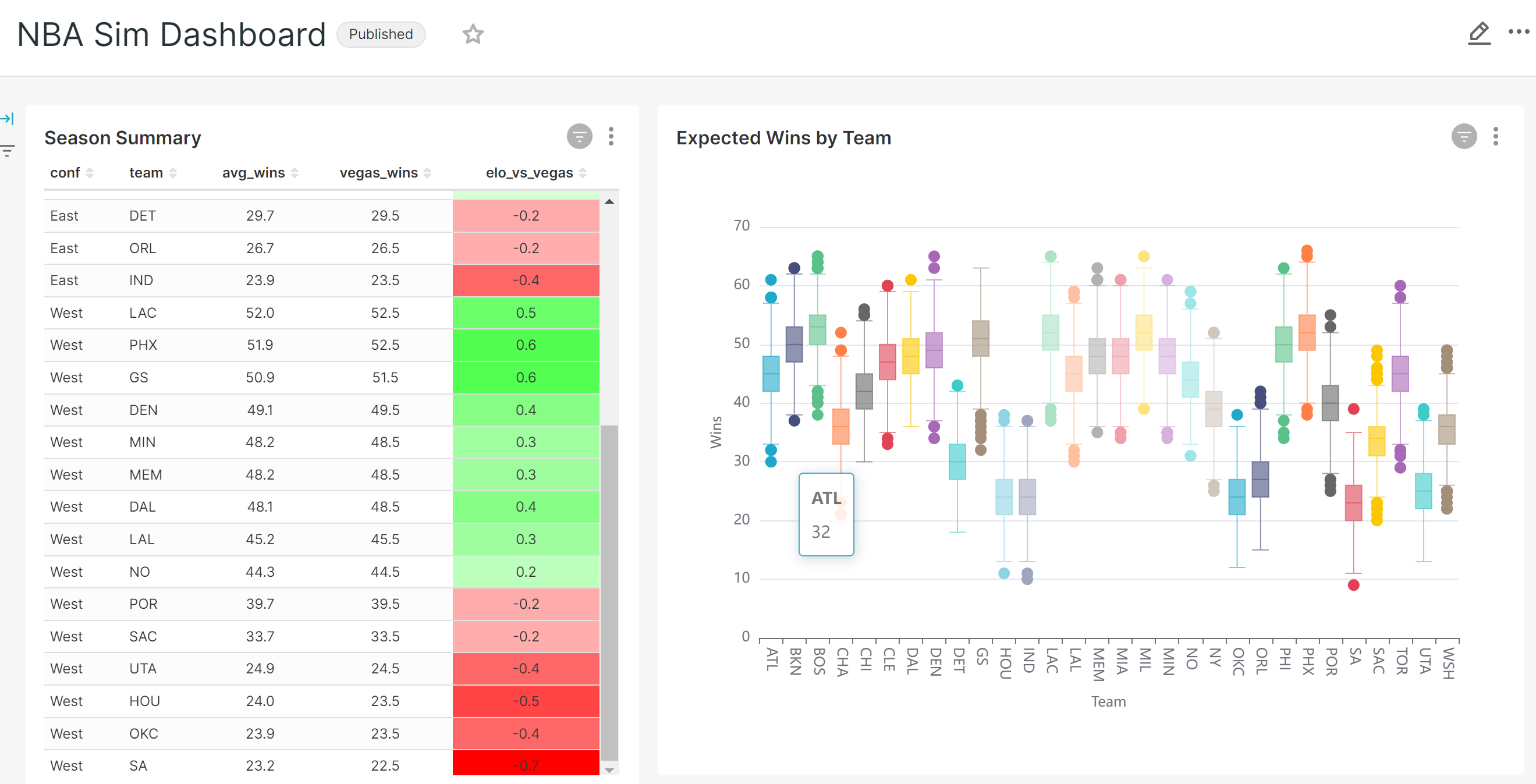
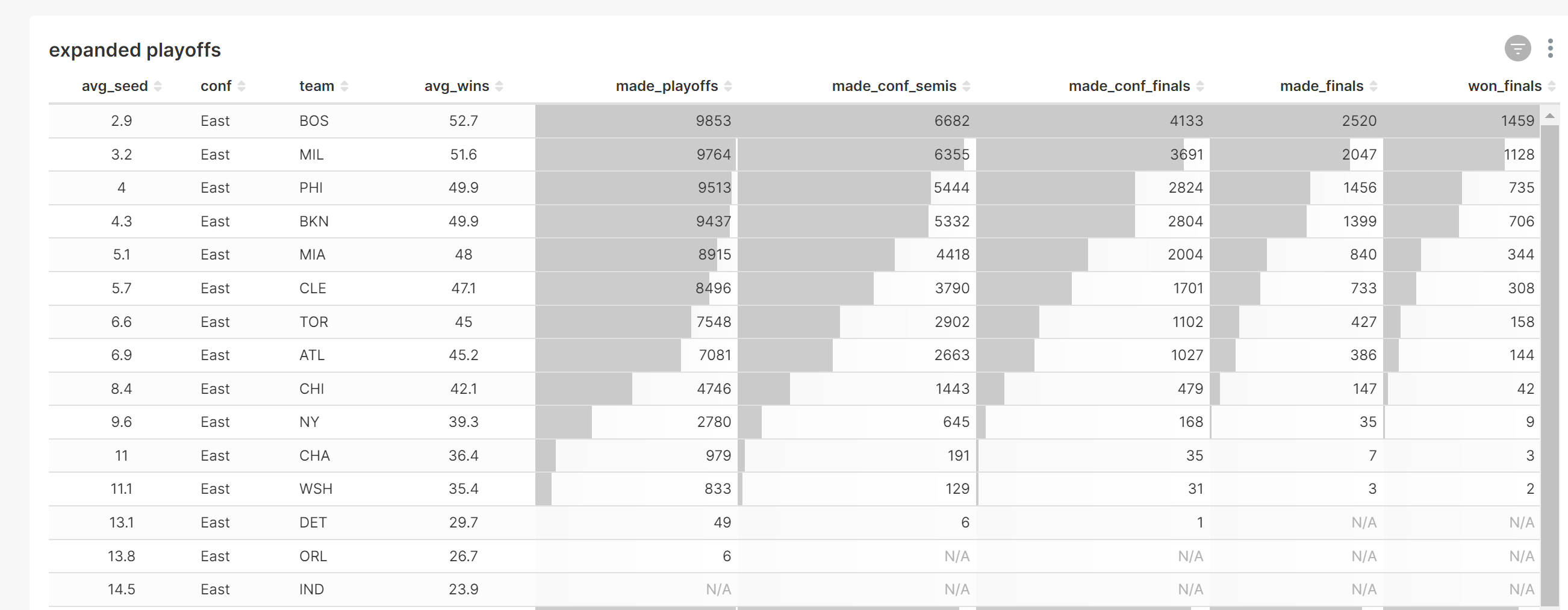
有两个模型专为分析设计,尽管可以使用任意数量的模型。'season_summary' 包含赛季的各种汇总统计数据,而 'reg_season_sim' 包含所有模拟比赛结果。第二个数据集会生成一个有趣的直方图。要在 Superset 中构建数据可视化,必须首先定义数据集,然后构建图表,最后将图表分配给仪表盘。
下面是一个 Superset 仪表盘示例,其中包含基于这些数据的多个图表。Superset 能够清晰地汇总数据,并显示蒙特卡罗模拟中的变异水平。当运行新的模拟时,duckdb_engine 查询可以快速刷新。
结论
DuckDB 周围的生态系统已经发展壮大,使其能够很好地与现代化数据堆栈集成。盒装 MDS 对于小型数据项目来说是一种可行的方法,并且特别适用于读密集型分析。这次实验还有一些其他的经验教训。Superset 仪表盘易于构建,但它们不可脚本化,必须在 GUI 中构建(付费托管版本 Preset 支持导出为 YAML)。此外,虽然您可以在 SQL 中进行蒙特卡罗分析,但在其他语言中可能更容易实现。然而,这表明了 SQL 的能力可以被拓展到何种程度!
下一步
本项目还有其他发展方向。下一步可以是对此工作流进行 Docker 化,以实现更简单的部署。如果您想制作一个 Docker 示例,请联系我们!另一种调整方法可能是将最终输出存储到 Parquet 文件中,并使用内存中的 DuckDB 连接来读取它们。这些文件甚至可以存储在 S3 兼容的对象存储中(并且仍然可以由 DuckDB 读取),尽管这与盒装方法相比增加了复杂性!还可以集成额外的 MDS 组件,用于数据质量监控、血缘跟踪等。
Josh Wills 也在对 dbt-duckdb 进行一项有趣的增强!使用 sqlglot 库,dbt-duckdb 将能够自动将使用其他数据库(包括 Snowflake 和 BigQuery)SQL 方言编写的 dbt 模型转译为 DuckDB 兼容的 SQL。想象一下,如果您可以在推送到生产环境之前在本地测试您的查询……加入 dbt slack 的 DuckDB 频道,讨论各种可能性!
如果您使用此方法或任何其他方法构建盒装 MDS,请联系我们!此外,如果您有兴趣为 DuckDB 博客撰写嘉宾文章,请在 Discord 上联系我们!

