DuckDB 中的并行分组聚合
总结来说:DuckDB 拥有一个完全并行化的聚合哈希表,能够高效地对数百万个组进行聚合。
分组聚合是核心数据分析命令。它对于大规模数据分析(“OLAP”)尤为重要,因为它有助于计算巨型表的统计摘要。DuckDB 包含一个高度优化的并行聚合能力,可实现快速且可扩展的汇总。
直接跳转到基准测试?
介绍
GROUP BY 会改变结果集的基数——它不会像普通的 SELECT 那样返回与输入相同行数的结果,而是返回与数据中组的数量相同的行数。考虑这个(有点眼熟的)示例查询:
SELECT
l_returnflag,
l_linestatus,
sum(l_extendedprice),
avg(l_quantity)
FROM
lineitem
GROUP BY
l_returnflag,
l_linestatus;
GROUP BY 后跟两个列名:l_returnflag 和 l_linestatus。这些是用于计算组的列,结果表将包含数据中出现的相同列的所有组合。我们将 GROUP BY 子句中的列称为“分组列”,将其中出现的所有值组合称为“组”。SELECT 子句包含四个(不是五个)表达式:对分组列的引用,以及两个聚合:l_extendedprice 的 sum 和 l_quantity 的 avg。我们将这些称为“聚合”。如果执行,此查询的结果看起来像这样:
| l_returnflag | l_linestatus | sum(l_extendedprice) | avg(l_quantity) |
|---|---|---|---|
| N | O | 114935210409.19 | 25.5 |
| R | F | 56568041380.9 | 25.51 |
| A | F | 56586554400.73 | 25.52 |
| N | F | 1487504710.38 | 25.52 |
一般来说,SQL 仅允许 GROUP BY 子句中提及的列直接成为 SELECT 表达式的一部分,所有其他列都需要应用诸如 sum、avg 等聚合函数。根据您使用的 SQL 系统,还有更多聚合函数。
查询处理引擎应如何计算此类聚合?这涉及许多设计决策,我们将在下面讨论这些,特别是 DuckDB 所做的决策。计算分组结果时的主要问题是,组在输入表中可能以任意顺序出现。如果输入已按分组列排序,那么计算聚合将是微不足道的,因为我们只需将分组列的当前值与先前的值进行比较。如果发生变化,则开始下一个组,并且需要计算新的聚合结果。由于排序情况很简单,因此计算分组聚合的一种直接方法是首先根据分组列对输入表进行排序,然后使用这种简单方法。但不幸的是,尽管我们付出了最大的努力,对输入进行排序仍然是一个计算开销很大的操作。一般来说,排序的计算复杂度为 O(nlogn),其中 n 是排序的行数。
用于聚合的哈希表
更好的方法是使用哈希表。哈希表是计算机领域的基础数据结构,它允许我们以 O(1) 的计算复杂度查找条目。关于哈希表工作原理的完整讨论远远超出本文的范围。下面我们将重点介绍与聚合计算相关的非常基本的描述和考虑因素。

向哈希表添加 n 行的复杂度为 O(n),这比排序的 O(nlogn) 要好得多,尤其当 n 达到数十亿时。上图说明了随着表大小的增加,复杂度如何演变。另一个巨大的优势是,我们不必首先对输入进行排序并复制一份,因为复制的输入将与原始输入一样大。相反,哈希表的条目最多与组的数量一样多,这通常(并且确实)显著少于输入行数。因此,整个过程如下:扫描输入表,并为每一行相应地更新哈希表。一旦输入处理完毕,我们扫描哈希表,将行提供给上游操作符或直接作为查询结果。
冲突处理
那么,就用哈希表吧!我们根据输入构建一个哈希表,以组作为键,以聚合作为条目。然后,对于每一行输入,我们计算组值的哈希值,在哈希表中找到相应的条目,然后使用行中的值创建或更新聚合状态?不幸的是,事情没那么简单:两行具有不同分组列值的记录可能产生指向相同哈希表条目的哈希值,这将导致不正确的结果。
解决这个问题的主要方法有两种:“链式处理”或“线性探测”。使用链式处理时,我们不直接在哈希表中存储聚合值,而是保留一个组值和聚合的列表。如果分组值指向一个列表为空的哈希表条目,则简单地添加新组和聚合。如果分组值指向一个现有列表,我们会检查每个列表条目以查看分组值是否匹配。如果匹配,则更新该组的聚合。如果不匹配,则创建一个新的列表条目。在线性探测中没有这样的列表,但在找到现有条目时,我们会比较分组值,如果匹配则更新该条目。如果不匹配,我们会在哈希表中向下移动一个条目并再次尝试。此过程在找到匹配的组条目或找到空的哈希表条目时结束。尽管理论上等效,但由于缓存局部性,计算机硬件架构将偏向于线性探测。因为线性探测是线性地遍历哈希表条目,所以下一个条目很可能在 CPU 缓存中,从而访问速度更快。链式处理通常会导致随机访问,并在现代硬件架构上导致更差的性能。因此,我们的聚合哈希表采用了线性探测。
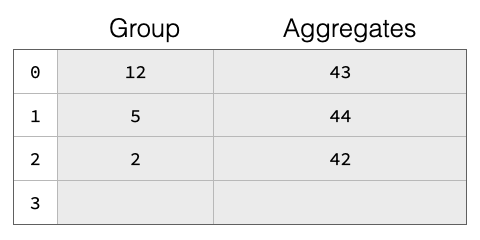
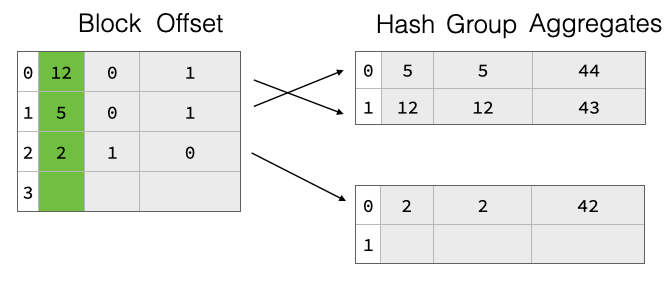
如果冲突过多,即太多组哈希到相同的哈希表条目,链式处理和线性探测的理论查找性能都会从 O(1) 降至 O(n)(相对于哈希表大小)。解决此问题的常见方法是,一旦“填充率”超过某个阈值(例如,Java 的 HashMap 默认值为 75%),就对哈希表进行扩容。这尤其重要,因为我们不知道在开始聚合之前结果中会有多少组。我们也不假设知道输入表中的行数。因此,我们从一个相当小的哈希表开始,一旦填充率超过阈值就对其进行扩容。基本的哈希表结构如下图所示,该表有四个槽位 0-4。表中已有三个组,组键分别为 12、5 和 2。每个组都有聚合值(例如,来自 SUM)为 43 等。
部分填充的哈希表在扩容时面临一个巨大挑战:扩容后,所有组都位于错误的位置,我们将不得不移动所有内容,这将非常昂贵。
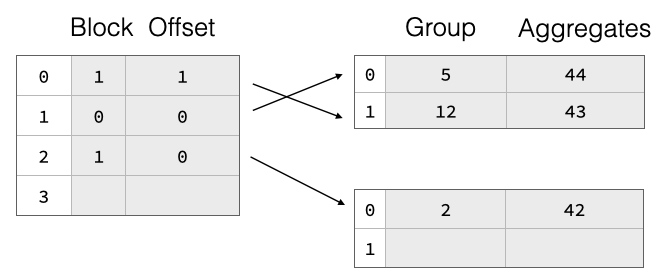
为了高效支持扩容,我们实现了一个两部分聚合哈希表,它由一个单独分配的指针数组组成,该数组指向包含每个组的分组值和聚合状态的载荷块。这些指针不是实际的内存指针,而是符号化的,它们引用一个块 ID 和该块内的行偏移量。如上图所示,哈希表条目分布在两个载荷块中。在扩容时,我们丢弃旧的指针数组并分配一个更大的。然后,我们再次读取所有载荷块,对组值进行哈希计算,并将指向它们的新指针重新插入到新的指针数组中。因此,组数据保持不变,这大大降低了扩容哈希表的成本。这可以在下图中看到,我们将指针数组大小加倍,但载荷块保持不变。
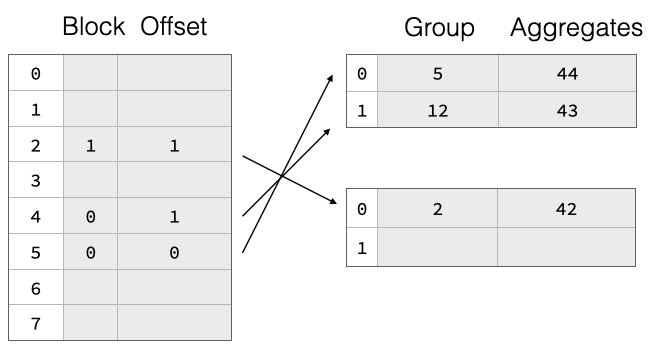
朴素的两部分哈希表设计在扩容时需要对所有组值进行重新哈希,尤其对于字符串值来说,这会非常昂贵。为了加快速度,我们还将每个组的组值的原始哈希写入载荷块。这样,在扩容期间,我们就不必重新哈希这些组,而只需从载荷块中读取它们,计算指针数组中的新偏移量,然后插入。
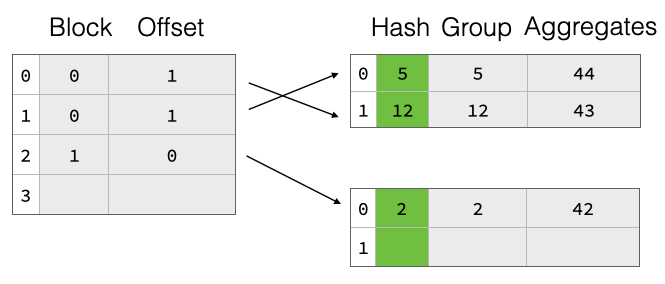
两部分哈希表在查找条目时有一个巨大的缺点:指针数组与载荷块中的组条目之间没有排序。因此,遵循指针会在内存层次结构中产生随机访问。这将导致计算中不必要的停顿。为了缓解此问题,我们扩展了指针数组的内存布局,使其除了指向载荷值的指针外,还包含组哈希值的一些(1 或 2)字节。这样,线性探测可以首先比较指针数组中的哈希位与当前组哈希值,并决定是否值得跟随载荷指针。这可以对指针链中的每个组继续进行。只有当哈希位匹配时,我们才必须实际遵循指针并比较实际的组。这种优化大大减少了需要遵循指向载荷块的指针的次数,从而减少了对内存的随机访问量,这与整体性能直接相关。它还有一个不错的附带效果,即大大减少了完整的组比较,这在对包含字符串的组进行聚合时也可能很昂贵。
这里另一个(较小的)优化涉及指针数组条目的宽度。对于条目较少的小型哈希表,我们不需要太多位来编码载荷块偏移指针。DuckDB 支持 4 字节和 8 字节的指针数组条目。
对于大多数聚合查询,绝大部分查询处理时间都花在查找哈希表条目上,这就是为什么值得花时间对其进行优化的原因。如果您好奇,所有这些代码都在 DuckDB 仓库中的 aggregate_hashtable.cpp 文件里。还有另一种优化,当我们从列统计信息中得知只有少数不同的组时,即完美哈希聚合,但这将是另一篇文章的主题。但我们在这里还没结束。
并行聚合
虽然我们现在有了一个应该适用于分组聚合的聚合哈希表设计,但我们仍然没有考虑 DuckDB 自动并行化所有查询以使用多个硬件线程(“CPU”)这一事实。并行化如何与哈希表协同工作?一般来说,不幸的答案是:“不理想”。哈希表是精妙的结构,不擅长并行修改。例如,想象一个线程想要扩容哈希表,而另一个线程想要向其中添加新的组数据。或者,我们应该如何处理多个线程同时为同一条目插入新组?可以使用锁来确保一次只有一个线程使用该表,但这在很大程度上会违背查询并行化的目的。关于并发友好的哈希表已经有大量研究,但简而言之,这仍然是一个悬而未决的问题。
可以让每个线程从下游操作符读取数据,并构建独立的、本地的哈希表,然后稍后由单个线程将它们合并。如果组的数量很少,就像本文开头的示例那样,这种方法效果很好。如果组的数量很少,单个线程可以合并许多线程局部哈希表而不会造成瓶颈。然而,完全有可能组的数量与输入行数一样多,当人们对可能成为主键的列(例如 observation_number、timestamp 等)进行分组时,这种情况经常发生。因此,需要的是并行哈希表的并行合并。我们采用了 Leis 等人的一种方法:每个线程不是构建一个,而是基于组哈希的基数分区构建多个分区哈希表。
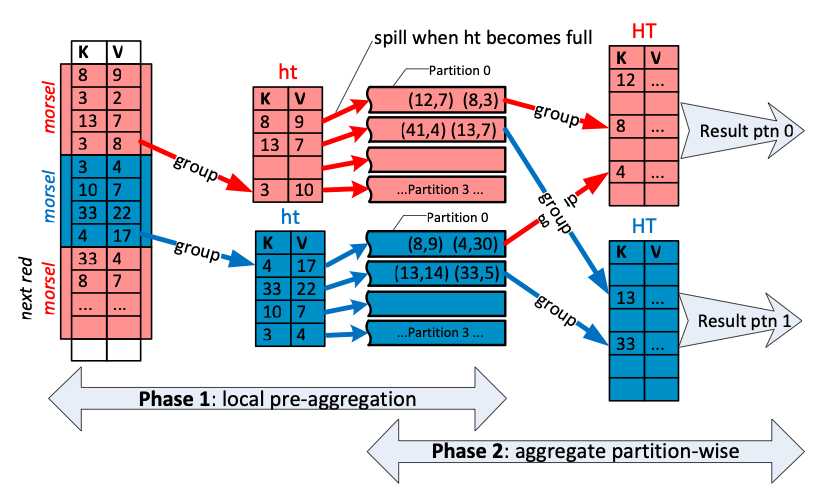
这里的关键观察是,如果两个组具有不同的哈希值,它们就不可能相同。由于这一特性,只要所有线程使用相同的分区方案(参见上图中的阶段 1),就可以使用哈希值来创建完全独立的组分区,而无需线程之间进行任何通信。
所有本地哈希表构建完成后,我们将独立的分区分配给每个工作线程,并将该分区内的哈希表合并在一起(阶段 2)。由于分区是使用基于哈希的基数分区方案创建的,所有工作线程都可以在各自的分区内独立合并哈希表。结果是正确的,因为每个组都只进入一个分区。
一个有趣的细节是,我们永远不需要构建一个最终的(可能巨大的)哈希表来容纳所有组,因为基数组分区确保每个组都局限于一个分区。
并行分区哈希表策略还有两个额外的优化:1) 我们仅在单个线程的聚合哈希表条目超过固定限制(当前设置为 10,000 行)后才开始分区。这是因为使用分区哈希表并非没有开销。对于添加的每一行,我们都必须确定它应该进入哪个分区,并且最后我们必须将所有内容合并回来。因此,我们不会开始分区,直到并行化收益超过成本。由于分区决策是每个线程独立的,因此很可能只有部分线程开始分区。如果是这种情况,在开始合并之前,我们需要对尚未这样做的线程的哈希表进行分区。然而,这是一个完全的线程局部操作,不会干扰并行性。2) 一旦哈希表的指针数组超过某个阈值,我们将停止向其添加值。然后每个线程会构建多组可能的分区哈希表。这是因为我们不希望指针数组变得任意大。尽管这可能在多个哈希表中为同一组创建重复条目,但这并不是问题,因为我们无论如何都会在稍后将它们全部合并。这种优化对于具有许多不同组,但组值在输入中以某种方式聚集的数据集尤其有效。例如,在按日期排序的数据集中按天分组时。
有些聚合类型无法使用并行和分区哈希表方法。虽然并行化求和是微不足道的,因为总体结果的总和就是各个结果的总和,但对于像 DuckDB 也支持的 median 这样的计算来说,这几乎是不可能的。也正因为如此,DuckDB 还支持 approx_quantile,它是可以并行化的。
实验
综合以上所有,现在是时候进行一些性能实验了。我们将把 DuckDB 上述的聚合操作符与各种 Python 数据处理库中的相同操作符进行比较。其他竞争者包括 Pandas、Polars 和 Arrow。选择它们是因为它们都可以像 DuckDB 一样,无需先转换为其他存储格式即可在 Pandas DataFrames 上执行聚合操作符。
为了进行基准测试,我们生成了一个合成数据集,其中包含在两个整数列上预定义数量的组以及一些用于聚合的随机整数数据。在实验前,整个数据集会被打乱,以防止利用合成生成数据的集群特性。对于每个组,我们计算两个聚合:数据列的总和和一个简单的计数。此聚合的 SQL 版本将是 SELECT g1, g2, sum(d), count(*) FROM dft GROUP BY g1, g2 LIMIT 1;。在下面的实验中,我们改变数据集的大小和其中的组数量。这应该能很好地展示聚合的扩展行为。
由于我们不感兴趣测量结果集物化时间(对于数百万个组来说这将是显著的),因此我们在聚合之后使用一个只检索第一行的操作符。这完全不会改变聚合的复杂度,因为它需要在生成第一个结果行之前收集所有数据,因为最后一行输入数据中可能存在改变第一个结果的数据。当然,这在实践中相当不切实际,但它应该能很好地隔离聚合操作符的行为,因为对三列执行 head(1) 操作应该相当廉价且执行时间恒定。

我们测量了完成每次聚合所需的挂钟时间。为了消除微小变化,我们重复每次测量三次,并报告所需时间的中位数。所有实验均在配备十核 M1 Max 处理器和 64 GB 内存的 2021 款 MacBook Pro 上运行。我们的数据生成基准测试脚本可在网上获取,我们邀请有兴趣的读者在自己的机器上重新运行实验。

现在我们来讨论一些结果。我们首先将表的行数从一百万变到一亿。我们对两种情况重复进行了实验:一种是固定(小)组数 1000,另一种是组数等于行数。结果以双对数图绘制,我们可以看到 DuckDB 持续优于其他系统,其中单线程的 Pandas 最慢,Polars 和 Arrow 总体相似。

在下一个实验中,我们将行数固定在 1 亿(我们实验过的最大尺寸),并展示增加组大小时的完整行为。我们可以再次看到,DuckDB 在增加组大小时持续表现出良好的扩展行为,因为它能有效地并行化上述聚合的所有阶段。如果您对我们如何生成这些图感兴趣,绘图脚本也可用。
结论
大部分使用聚合的数据分析管道将其绝大部分执行时间花在聚合哈希表中,这就是为什么值得花费大量人力时间对其进行优化的原因。我们对此有一些未来的工作想法,例如,我们希望将比较排序键的工作扩展到比较聚合哈希表中的组。我们还希望增加根据对已创建哈希表的动态观察来动态选择线程使用的分区数量的功能,例如,如果分区不平衡,我们可以使用更多位来实现。未来工作的另一个重要领域是使我们的聚合哈希表支持核外操作,即单个哈希表不再适合内存的情况,这在合并时尤其成问题。当然,也总是存在微调聚合操作符的机会,我们正在持续改进 DuckDB 的聚合操作符。
如果您想从事像这样将被成千上万的人使用的尖端数据工程工作,请考虑为 DuckDB 贡献力量,或加入我们在阿姆斯特丹的 DuckDB 实验室!

