DuckDB – 枚举之王:分类与因子联盟


字符串类型是最常用的类型之一。然而,通常字符串列只有有限数量的不同值。例如,一个国家列永远不会超过几百个唯一的条目。将数据类型存储为纯字符串会导致存储空间的浪费,并影响查询性能。一个更好的解决方案是对这些列进行字典编码。在字典编码中,数据被分成两部分:类别和值。类别存储实际的字符串,而值存储对字符串的引用。这种编码如下图所示。
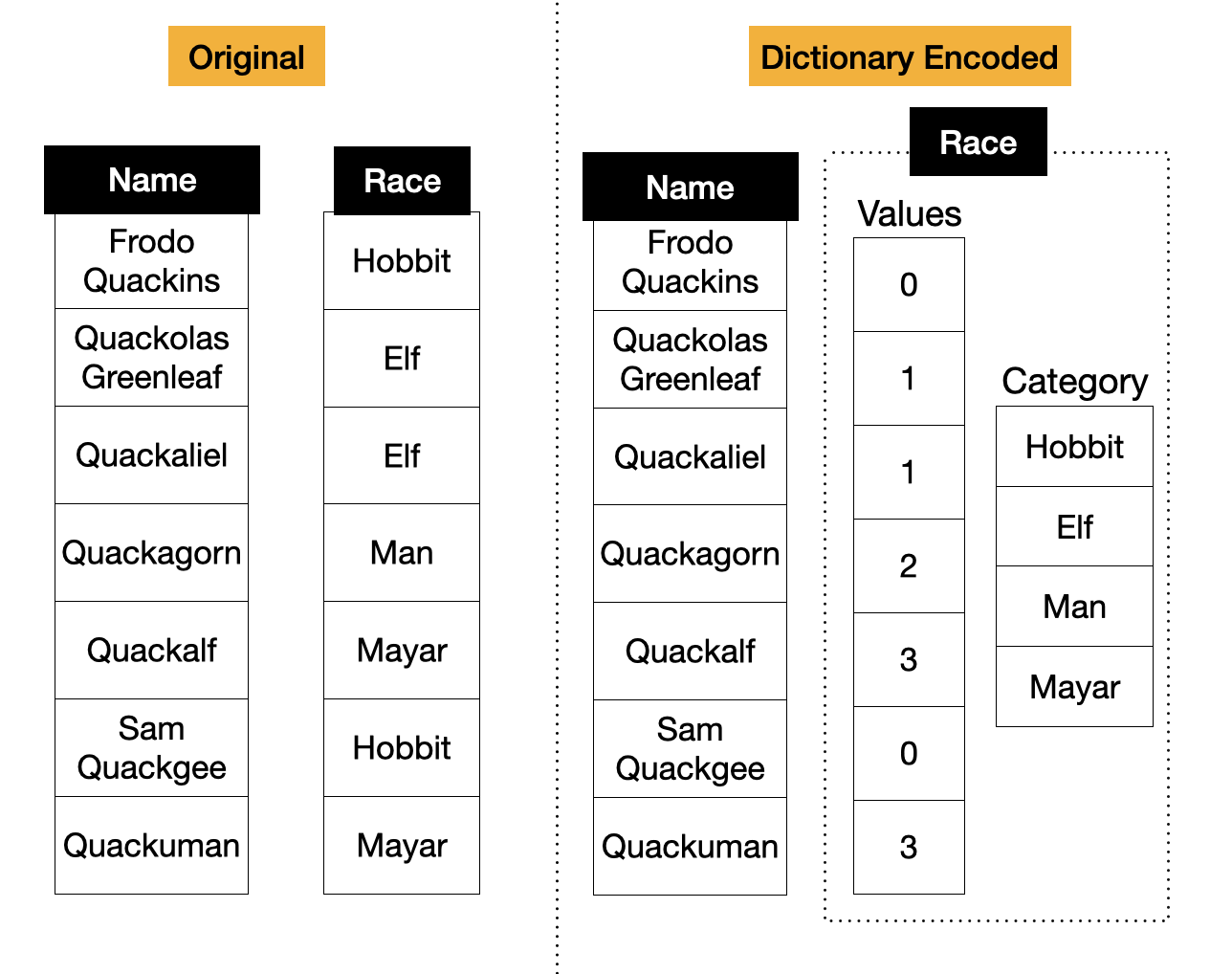
在过去,用户会通过创建查找表并使用连接操作将他们的 ID 转换回来来手动执行字典编码。像 Pandas 和 R 这样的环境更优雅地支持这些类型。Pandas Categorical 和 R Factors 是允许通过字典编码有效地存储具有许多重复条目的字符串列的类型。
字典编码不仅可以节省大量的存储空间,还允许系统操作数字而不是字符串,从而极大地提高查询性能。通过降低 RAM 使用率,ENUMs 还允许 DuckDB 扩展到更大的数据集。
为了让 DuckDB 完全集成这些编码结构,我们实现了枚举类型。这篇博文将展示如何使用 SQL API 和 Python/R 客户端的 ENUM 类型,并将演示枚举类型相对于使用常规字符串的性能优势。据我们所知,DuckDB 是第一个与 Pandas 分类列和 R 因子原生集成的 RDBMS。
SQL
我们的 Enum SQL 语法深受 Postgres 的启发。下面,我们描述如何创建和使用 ENUM 类型。
CREATE TYPE lotr_race AS ENUM ('Mayar', 'Hobbit', 'Orc');
CREATE TABLE character (
name text,
race lotr_race
);
INSERT INTO character VALUES ('Frodo Quackins','Hobbit'), ('Quackalf ', 'Mayar');
-- We can perform a normal string comparison
-- Note that 'Hobbit' will be cast to a lotr_race
-- hence this comparison is actually a fast integer comparison
SELECT name FROM character WHERE race = 'Hobbit';
----
Frodo Quackins
ENUM 列的行为与普通的 VARCHAR 列完全相同。它们可以在字符串函数中使用(例如 LIKE 或 substring),可以进行比较、排序等。唯一的例外是 ENUM 列只能包含枚举定义中指定的值。插入不属于枚举定义的值将导致错误。
DuckDB ENUM 目前是静态的(即,在 ENUM 定义后无法添加或删除值)。但是,ENUM 更新已在下一个版本的路线图上。
有关更多信息,请参阅文档。
Python
设置
首先我们需要安装 DuckDB 和 Pandas。在 Python 中安装这两个库非常简单
# Python Install
pip install duckdb
pip install pandas
用法
分类类型的 Pandas 列直接转换为 DuckDB 的 ENUM 类型
import pandas as pd
import duckdb
# Our unencoded data.
data = ['Hobbit', 'Elf', 'Elf', 'Man', 'Mayar', 'Hobbit', 'Mayar']
# 'pd.Categorical' automatically encodes the data as a categorical column
df_in = pd.DataFrame({'races': pd.Categorical(data),})
# We can query this dataframe as we would any other
# The conversion from categorical columns to enums happens automatically
df_out = duckdb.execute("SELECT * FROM df_in").df()
R
设置
我们只需要在 R 客户端中安装 DuckDB,就可以开始了。
# R Install
install.packages("duckdb")
用法
与之前使用 Pandas 的示例类似,R Factor 列也会自动转换为 DuckDB 的 ENUM 类型。
library ("duckdb")
con <- dbConnect(duckdb::duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
# Our unencoded data.
data <- c('Hobbit', 'Elf', 'Elf', 'Man', 'Mayar', 'Hobbit', 'Mayar')
# Our R dataframe holding an encoded version of our data column
# 'as.factor' automatically encodes it.
df_in <- data.frame(races=as.factor(data))
duckdb::duckdb_register(con, "characters", df_in)
df_out <- dbReadTable(con, "characters")
基准比较
为了演示 DuckDB 在 Pandas DataFrames 分类列上运行操作时的性能,我们展示了一些基准。这些基准的源代码可以在 GitHub 上找到。在我们的基准测试中,我们始终使用和生成 Pandas DataFrames。
数据集
我们的数据集由一个具有 4 列和 1000 万行的 dataframe 组成。前两列名为 race 和 subrace,表示种族。它们都是分类的,具有相同的类别但不同的值。其他两列 race_string 和 subrace_string 是 race 和 subrace 的字符串表示``。
def generate_df(size):
race_categories = ['Hobbit', 'Elf', 'Man', 'Mayar']
race = np.random.choice(race_categories, size)
subrace = np.random.choice(race_categories, size)
return pd.DataFrame({'race': pd.Categorical(race),
'subrace': pd.Categorical(subrace),
'race_string': race,
'subrace_string': subrace,})
size = pow(10,7) #10,000,000 rows
df = generate_df(size)
分组聚合
在我们的分组聚合基准测试中,我们计算了表中 race 或 race_string 列中每个种族有多少个字符。
def duck_categorical(df):
return con.execute("SELECT race, count(*) FROM df GROUP BY race").df()
def duck_string(df):
return con.execute("SELECT race_string, count(*) FROM df GROUP BY race_string").df()
def pandas(df):
return df.groupby(['race']).agg({'race': 'count'})
def pandas_string(df):
return df.groupby(['race_string']).agg({'race_string': 'count'})
下表描述了此操作的计时。我们可以看到对编码值进行分组而不是对字符串进行分组的好处,当分组小的无符号值时,DuckDB 的速度快 4 倍。
| 名称 | 时间 (秒) |
|---|---|
| DuckDB(分类) | 0.01 |
| DuckDB(字符串) | 0.04 |
| Pandas(分类) | 0.06 |
| Pandas(字符串) | 0.40 |
过滤器
在我们的过滤器基准测试中,我们计算了表中 race 或 race_string 列中有多少个霍比特人角色。
def duck_categorical(df):
return con.execute("SELECT count(*) FROM df WHERE race = 'Hobbit'").df()
def duck_string(df):
return con.execute("SELECT count(*) FROM df WHERE race_string = 'Hobbit'").df()
def pandas(df):
filtered_df = df[df.race == "Hobbit"]
return filtered_df.agg({'race': 'count'})
def pandas_string(df):
filtered_df = df[df.race_string == "Hobbit"]
return filtered_df.agg({'race_string': 'count'})
对于 DuckDB 枚举类型,DuckDB 将字符串 Hobbit 转换为 ENUM 中的一个值,该值返回一个无符号整数。然后,我们可以进行快速的数值比较,而不是昂贵的字符串比较,从而大大提高了性能。
| 名称 | 时间 (秒) |
|---|---|
| DuckDB(分类) | 0.003 |
| DuckDB(字符串) | 0.023 |
| Pandas(分类) | 0.158 |
| Pandas(字符串) | 0.440 |
Enum – Enum 比较
在此基准测试中,我们对两个品种列进行相等性比较。race 和 subrace 或 race_string 和 subrace_string``
def duck_categorical(df):
return con.execute("SELECT count(*) FROM df WHERE race = subrace").df()
def duck_string(df):
return con.execute("SELECT count(*) FROM df WHERE race_string = subrace_string").df()
def pandas(df):
filtered_df = df[df.race == df.subrace]
return filtered_df.agg({'race': 'count'})
def pandas_string(df):
filtered_df = df[df.race_string == df.subrace_string]
return filtered_df.agg({'race_string': 'count'})
DuckDB ENUM 可以直接在其编码值上进行比较。这导致了与前一种情况相似的时间差,同样是因为我们能够比较数值而不是字符串。
| 名称 | 时间 (秒) |
|---|---|
| DuckDB(分类) | 0.005 |
| DuckDB(字符串) | 0.040 |
| Pandas(分类) | 0.130 |
| Pandas(字符串) | 0.550 |
存储
在此基准测试中,我们比较了存储 ENUM 类型与字符串的存储节省。
race_categories = ['Hobbit', 'Elf', 'Man','Mayar']
race = np.random.choice(race_categories, size)
categorical_race = pd.DataFrame({'race': pd.Categorical(race),})
string_race = pd.DataFrame({'race': race,})
con = duckdb.connect('duck_cat.db')
con.execute("CREATE TABLE character AS SELECT * FROM categorical_race")
con = duckdb.connect('duck_str.db')
con.execute("CREATE TABLE character AS SELECT * FROM string_race")
下表描述了将同一列存储为 Enum 或纯字符串时 DuckDB 文件大小的差异。由于字典编码不会重复字符串值,我们可以看到大小减少了一个数量级。
| 名称 | 大小 (MB) |
|---|---|
| DuckDB(分类) | 11 |
| DuckDB(字符串) | 102 |
续集怎么样?
在后续版本的 DuckDB 中,我们将朝着与 ENUMs 相关的三个主要方向发展。
- 自动存储编码:正如引言中所述,用户经常将数据库列定义为字符串,而实际上它们是
ENUMs。我们的想法是自动检测和字典编码这些列,无需用户的任何输入,并且以对用户完全不可见的方式进行。 ENUM更新:正如引言中所述,我们的ENUMs 目前是静态的。我们将允许插入和删除ENUM类别。- 与其他数据格式集成:我们希望扩展与实现
ENUM类结构的数据格式的集成。
反馈
与往常一样,请告诉我们您对我们的 ENUM 集成的看法,您希望我们与哪些数据格式集成,以及您希望我们在此主题上追求的任何想法!请随时给我发送电子邮件。如果您在使用我们的 ENUMs 时遇到任何问题,请在我们的 问题跟踪器 中打开一个 issue!

